 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoints2Pix: 3D Point-Cloud to Image Translation using conditional Generative Adversarial Networks
Jan 26, 2019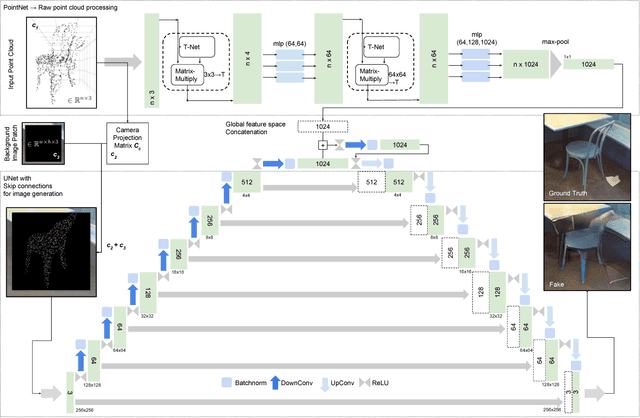
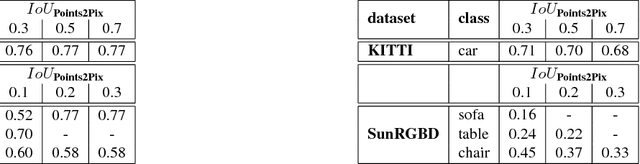
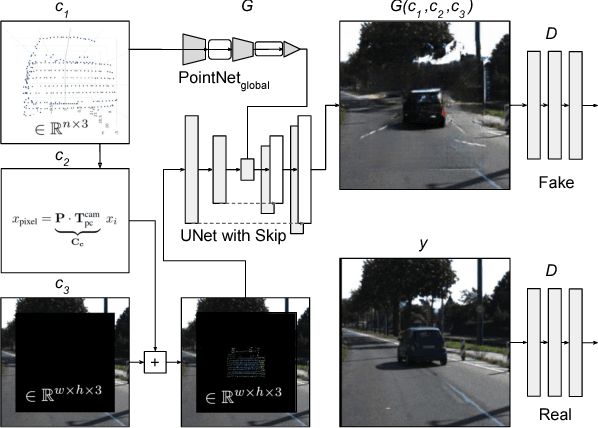

We present the first approach for 3D point-cloud to image translation based on conditional Generative Adversarial Networks (cGAN). The model handles multi-modal information sources from different domains, i.e. raw point-sets and images. The generator is capable of processing three conditions, whereas the point-cloud is encoded as raw point-set and camera projection. An image background patch is used as constraint to bias environmental texturing. A global approximation function within the generator is directly applied on the point-cloud (Point-Net). Hence, the representative learning model incorporates global 3D characteristics directly at the latent feature space. Conditions are used to bias the background and the viewpoint of the generated image. This opens up new ways in augmenting or texturing 3D data to aim the generation of fully individual images. We successfully evaluated our method on the Kitti and SunRGBD dataset with an outstanding object detection inception score.