 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Corner Cases: High-Resolution Inpainting for Safety Critical Detect and Avoid for Automated Flying
Jan 14, 2025Modern machine learning techniques have shown tremendous potential, especially for object detection on camera images. For this reason, they are also used to enable safety-critical automated processes such as autonomous drone flights. We present a study on object detection for Detect and Avoid, a safety critical function for drones that detects air traffic during automated flights for safety reasons. An ill-posed problem is the generation of good and especially large data sets, since detection itself is the corner case. Most models suffer from limited ground truth in raw data, \eg recorded air traffic or frontal flight with a small aircraft. It often leads to poor and critical detection rates. We overcome this problem by using inpainting methods to bootstrap the dataset such that it explicitly contains the corner cases of the raw data. We provide an overview of inpainting methods and generative models and present an example pipeline given a small annotated dataset. We validate our method by generating a high-resolution dataset, which we make publicly available and present it to an independent object detector that was fully trained on real data.
From Chaos to Calibration: A Geometric Mutual Information Approach to Target-Free Camera LiDAR Extrinsic Calibration
Nov 03, 2023Sensor fusion is vital for the safe and robust operation of autonomous vehicles. Accurate extrinsic sensor to sensor calibration is necessary to accurately fuse multiple sensor's data in a common spatial reference frame. In this paper, we propose a target free extrinsic calibration algorithm that requires no ground truth training data, artificially constrained motion trajectories, hand engineered features or offline optimization and that is accurate, precise and extremely robust to initialization error. Most current research on online camera-LiDAR extrinsic calibration requires ground truth training data which is impossible to capture at scale. We revisit analytical mutual information based methods first proposed in 2012 and demonstrate that geometric features provide a robust information metric for camera-LiDAR extrinsic calibration. We demonstrate our proposed improvement using the KITTI and KITTI-360 fisheye data set.
LiDAR-BEVMTN: Real-Time LiDAR Bird's-Eye View Multi-Task Perception Network for Autonomous Driving
Jul 17, 2023



LiDAR is crucial for robust 3D scene perception in autonomous driving. LiDAR perception has the largest body of literature after camera perception. However, multi-task learning across tasks like detection, segmentation, and motion estimation using LiDAR remains relatively unexplored, especially on automotive-grade embedded platforms. We present a real-time multi-task convolutional neural network for LiDAR-based object detection, semantics, and motion segmentation. The unified architecture comprises a shared encoder and task-specific decoders, enabling joint representation learning. We propose a novel Semantic Weighting and Guidance (SWAG) module to transfer semantic features for improved object detection selectively. Our heterogeneous training scheme combines diverse datasets and exploits complementary cues between tasks. The work provides the first embedded implementation unifying these key perception tasks from LiDAR point clouds achieving 3ms latency on the embedded NVIDIA Xavier platform. We achieve state-of-the-art results for two tasks, semantic and motion segmentation, and close to state-of-the-art performance for 3D object detection. By maximizing hardware efficiency and leveraging multi-task synergies, our method delivers an accurate and efficient solution tailored for real-world automated driving deployment. Qualitative results can be seen at https://youtu.be/H-hWRzv2lIY.
Continuous Online Extrinsic Calibration of Fisheye Camera and LiDAR
Jun 22, 2023



Automated driving systems use multi-modal sensor suites to ensure the reliable, redundant and robust perception of the operating domain, for example camera and LiDAR. An accurate extrinsic calibration is required to fuse the camera and LiDAR data into a common spatial reference frame required by high-level perception functions. Over the life of the vehicle the value of the extrinsic calibration can change due physical disturbances, introducing an error into the high-level perception functions. Therefore there is a need for continuous online extrinsic calibration algorithms which can automatically update the value of the camera-LiDAR calibration during the life of the vehicle using only sensor data. We propose using mutual information between the camera image's depth estimate, provided by commonly available monocular depth estimation networks, and the LiDAR pointcloud's geometric distance as a optimization metric for extrinsic calibration. Our method requires no calibration target, no ground truth training data and no expensive offline optimization. We demonstrate our algorithm's accuracy, precision, speed and self-diagnosis capability on the KITTI-360 data set.
LiMoSeg: Real-time Bird's Eye View based LiDAR Motion Segmentation
Nov 08, 2021


Moving object detection and segmentation is an essential task in the Autonomous Driving pipeline. Detecting and isolating static and moving components of a vehicle's surroundings are particularly crucial in path planning and localization tasks. This paper proposes a novel real-time architecture for motion segmentation of Light Detection and Ranging (LiDAR) data. We use two successive scans of LiDAR data in 2D Bird's Eye View (BEV) representation to perform pixel-wise classification as static or moving. Furthermore, we propose a novel data augmentation technique to reduce the significant class imbalance between static and moving objects. We achieve this by artificially synthesizing moving objects by cutting and pasting static vehicles. We demonstrate a low latency of 8 ms on a commonly used automotive embedded platform, namely Nvidia Jetson Xavier. To the best of our knowledge, this is the first work directly performing motion segmentation in LiDAR BEV space. We provide quantitative results on the challenging SemanticKITTI dataset, and qualitative results are provided in https://youtu.be/2aJ-cL8b0LI.
BEVDetNet: Bird's Eye View LiDAR Point Cloud based Real-time 3D Object Detection for Autonomous Driving
Apr 21, 2021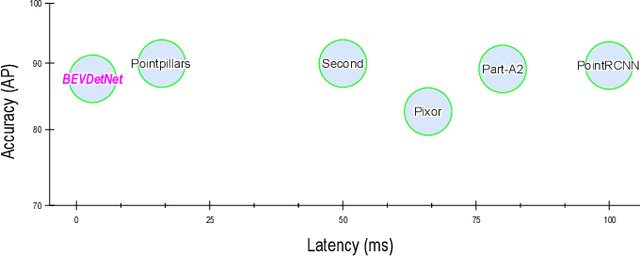
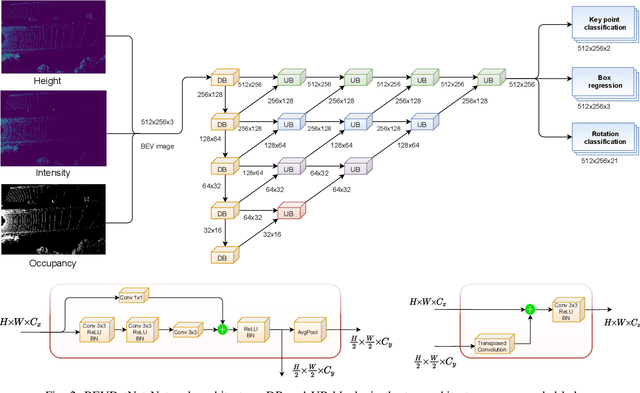

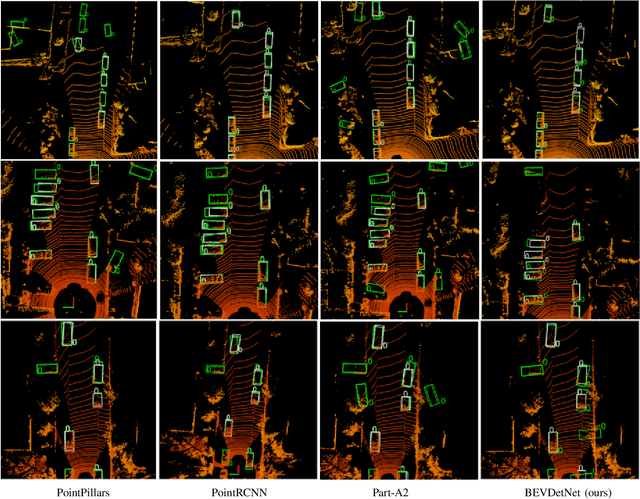
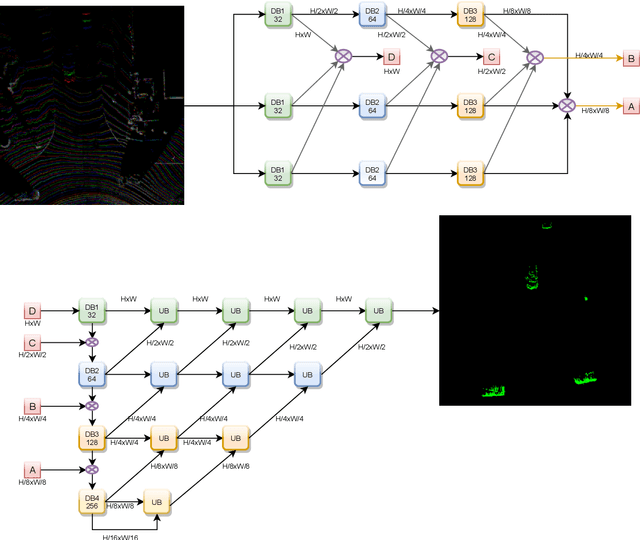
LiDAR based 3D object detection is a crucial module in autonomous driving particularly for long range sensing. Most of the research is focused on achieving higher accuracy and these models are not optimized for deployment on embedded systems from the perspective of latency and power efficiency. For high speed driving scenarios, latency is a crucial parameter as it provides more time to react to dangerous situations. Typically a voxel or point-cloud based 3D convolution approach is utilized for this module. Firstly, they are inefficient on embedded platforms as they are not suitable for efficient parallelization. Secondly, they have a variable runtime due to level of sparsity of the scene which is against the determinism needed in a safety system. In this work, we aim to develop a very low latency algorithm with fixed runtime. We propose a novel semantic segmentation architecture as a single unified model for object center detection using key points, box predictions and orientation prediction using binned classification in a simpler Bird's Eye View (BEV) 2D representation. The proposed architecture can be trivially extended to include semantic segmentation classes like road without any additional computation. The proposed model has a latency of 4 ms on the embedded Nvidia Xavier platform. The model is 5X faster than other top accuracy models with a minimal accuracy degradation of 2% in Average Precision at IoU=0.5 on KITTI dataset.
SVDistNet: Self-Supervised Near-Field Distance Estimation on Surround View Fisheye Cameras
Apr 09, 2021
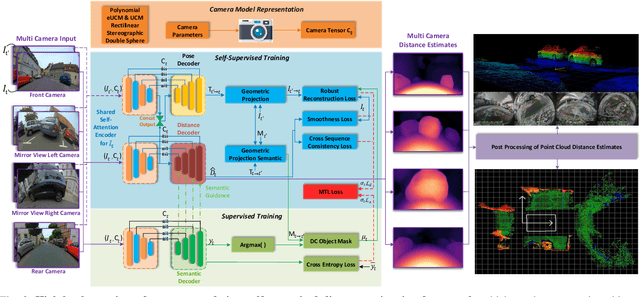
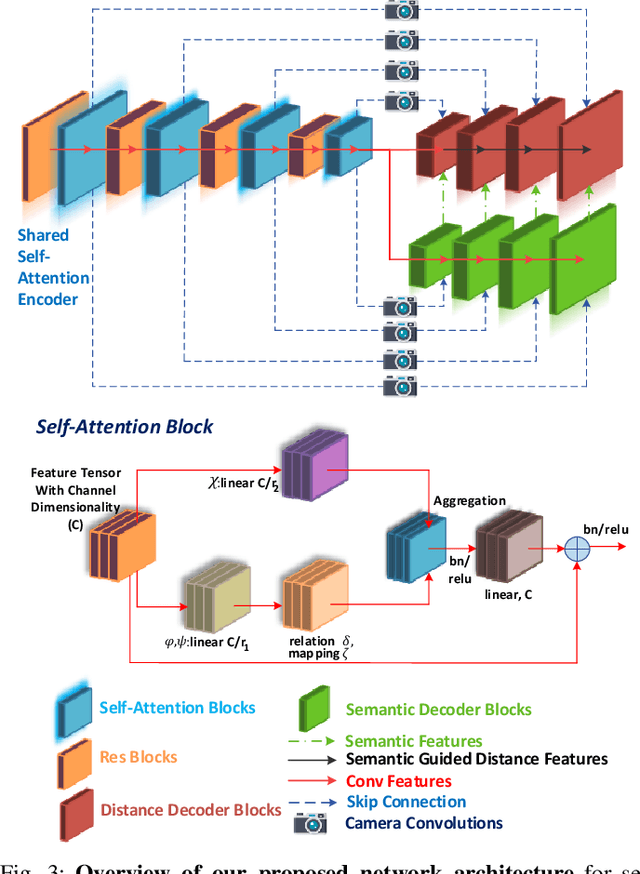

A 360{\deg} perception of scene geometry is essential for automated driving, notably for parking and urban driving scenarios. Typically, it is achieved using surround-view fisheye cameras, focusing on the near-field area around the vehicle. The majority of current depth estimation approaches focus on employing just a single camera, which cannot be straightforwardly generalized to multiple cameras. The depth estimation model must be tested on a variety of cameras equipped to millions of cars with varying camera geometries. Even within a single car, intrinsics vary due to manufacturing tolerances. Deep learning models are sensitive to these changes, and it is practically infeasible to train and test on each camera variant. As a result, we present novel camera-geometry adaptive multi-scale convolutions which utilize the camera parameters as a conditional input, enabling the model to generalize to previously unseen fisheye cameras. Additionally, we improve the distance estimation by pairwise and patchwise vector-based self-attention encoder networks. We evaluate our approach on the Fisheye WoodScape surround-view dataset, significantly improving over previous approaches. We also show a generalization of our approach across different camera viewing angles and perform extensive experiments to support our contributions. To enable comparison with other approaches, we evaluate the front camera data on the KITTI dataset (pinhole camera images) and achieve state-of-the-art performance among self-supervised monocular methods. An overview video with qualitative results is provided at https://youtu.be/bmX0UcU9wtA. Baseline code and dataset will be made public.
OmniDet: Surround View Cameras based Multi-task Visual Perception Network for Autonomous Driving
Feb 15, 2021
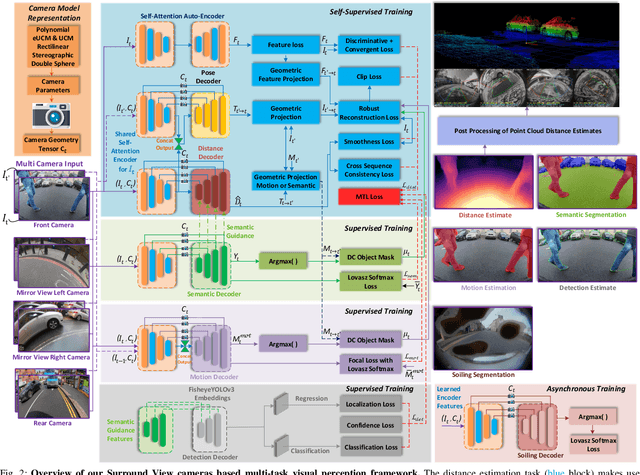
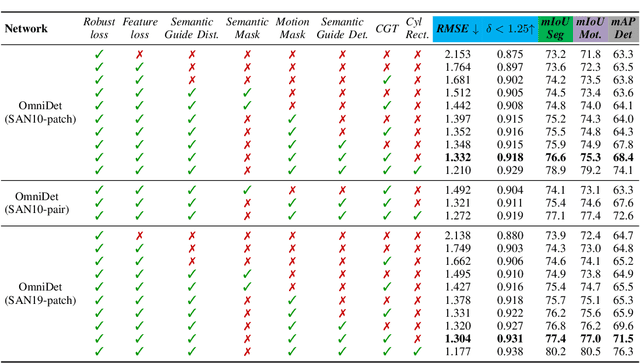
Surround View fisheye cameras are commonly deployed in automated driving for 360\deg{} near-field sensing around the vehicle. This work presents a multi-task visual perception network on unrectified fisheye images to enable the vehicle to sense its surrounding environment. It consists of six primary tasks necessary for an autonomous driving system: depth estimation, visual odometry, semantic segmentation, motion segmentation, object detection, and lens soiling detection. We demonstrate that the jointly trained model performs better than the respective single task versions. Our multi-task model has a shared encoder providing a significant computational advantage and has synergized decoders where tasks support each other. We propose a novel camera geometry based adaptation mechanism to encode the fisheye distortion model both at training and inference. This was crucial to enable training on the WoodScape dataset, comprised of data from different parts of the world collected by 12 different cameras mounted on three different cars with different intrinsics and viewpoints. Given that bounding boxes is not a good representation for distorted fisheye images, we also extend object detection to use a polygon with non-uniformly sampled vertices. We additionally evaluate our model on standard automotive datasets, namely KITTI and Cityscapes. We obtain the state-of-the-art results on KITTI for depth estimation and pose estimation tasks and competitive performance on the other tasks. We perform extensive ablation studies on various architecture choices and task weighting methodologies. A short video at https://youtu.be/xbSjZ5OfPes provides qualitative results.
SynDistNet: Self-Supervised Monocular Fisheye Camera Distance Estimation Synergized with Semantic Segmentation for Autonomous Driving
Aug 10, 2020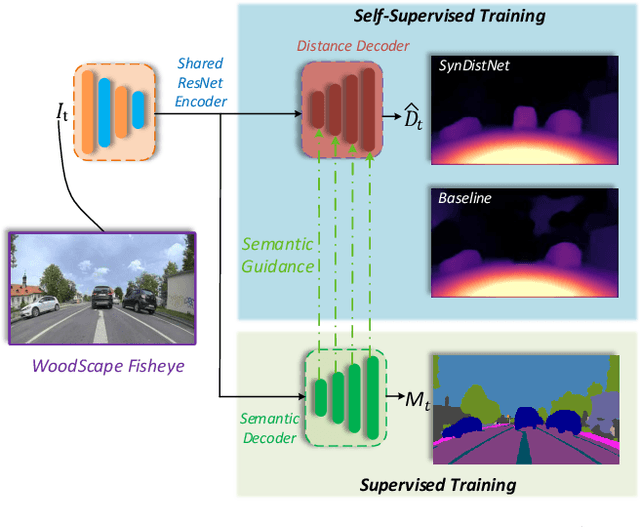
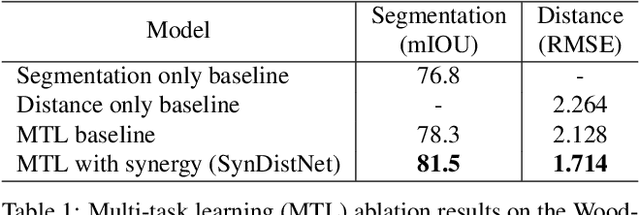
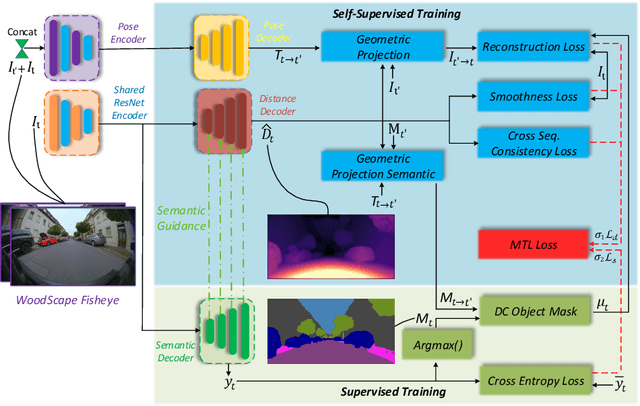
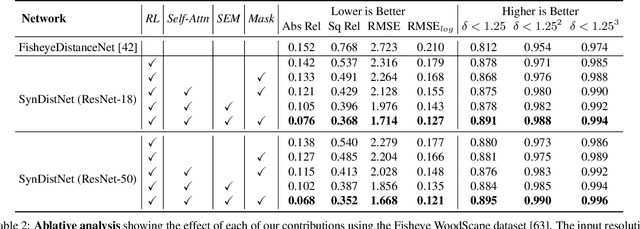
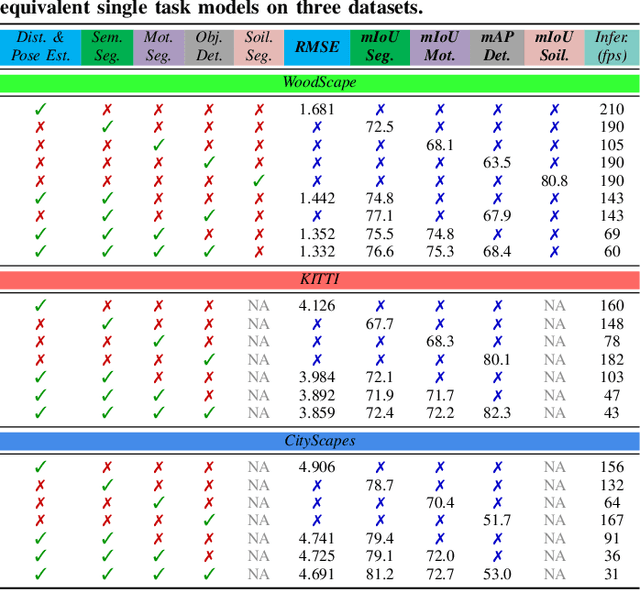
State-of-the-art self-supervised learning approaches for monocular depth estimation usually suffer from scale ambiguity. They do not generalize well when applied on distance estimation for complex projection models such as in fisheye and omnidirectional cameras. In this paper, we introduce a novel multi-task learning strategy to improve self-supervised monocular distance estimation on fisheye and pinhole camera images. Our contribution to this work is threefold: Firstly, we introduce a novel distance estimation network architecture using a self-attention based encoder coupled with robust semantic feature guidance to the decoder that can be trained in a one-stage fashion. Secondly, we integrate a generalized robust loss function, which improves performance significantly while removing the need for hyperparameter tuning with the reprojection loss. Finally, we reduce the artifacts caused by dynamic objects violating static world assumption by using a semantic masking strategy. We significantly improve upon the RMSE of previous work on fisheye by 25% reduction in RMSE. As there is limited work on fisheye cameras, we evaluated the proposed method on KITTI using a pinhole model.We achieved state-of-the-art performance among self-supervised methods without requiring an external scale estimation.
UnRectDepthNet: Self-Supervised Monocular Depth Estimation using a Generic Framework for Handling Common Camera Distortion Models
Jul 26, 2020

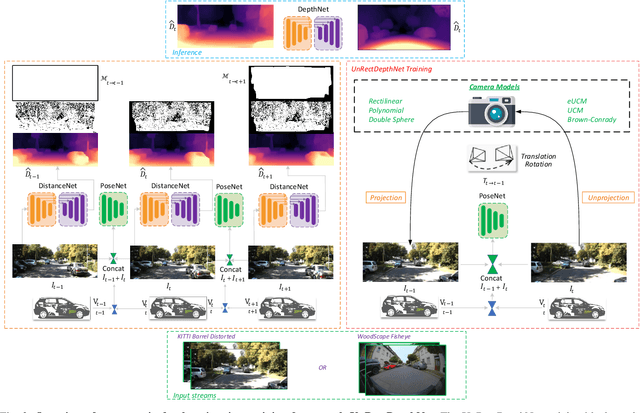

In classical computer vision, rectification is an integral part of multi-view depth estimation. It typically includes epipolar rectification and lens distortion correction. This process simplifies the depth estimation significantly, and thus it has been adopted in CNN approaches. However, rectification has several side effects, including a reduced field of view (FOV), resampling distortion, and sensitivity to calibration errors. The effects are particularly pronounced in case of significant distortion (e.g., wide-angle fisheye cameras). In this paper, we propose a generic scale-aware self-supervised pipeline for estimating depth, euclidean distance, and visual odometry from unrectified monocular videos. We demonstrate a similar level of precision on the unrectified KITTI dataset with barrel distortion comparable to the rectified KITTI dataset. The intuition being that the rectification step can be implicitly absorbed within the CNN model, which learns the distortion model without increasing complexity. Our approach does not suffer from a reduced field of view and avoids computational costs for rectification at inference time. To further illustrate the general applicability of the proposed framework, we apply it to wide-angle fisheye cameras with 190$^\circ$ horizontal field of view. The training framework UnRectDepthNet takes in the camera distortion model as an argument and adapts projection and unprojection functions accordingly. The proposed algorithm is evaluated further on the KITTI rectified dataset, and we achieve state-of-the-art results that improve upon our previous work FisheyeDistanceNet. Qualitative results on a distorted test scene video sequence indicate excellent performance https://youtu.be/K6pbx3bU4Ss.