 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniDet: Surround View Cameras based Multi-task Visual Perception Network for Autonomous Driving
Paper and Code
Feb 15, 2021
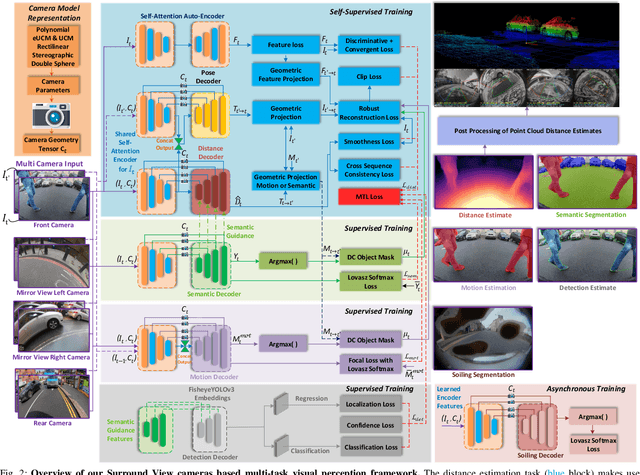
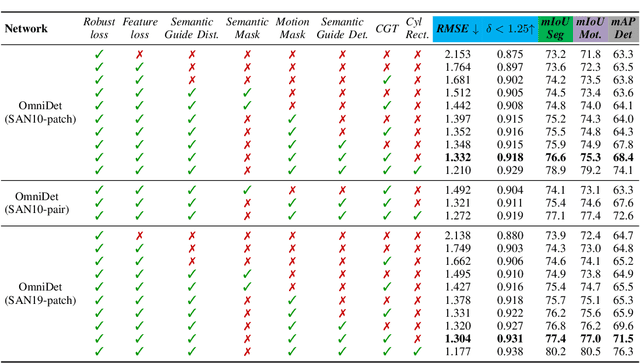
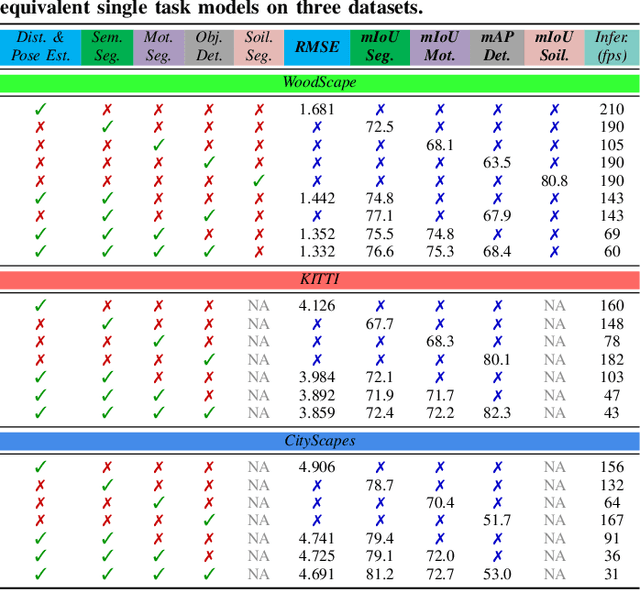
Surround View fisheye cameras are commonly deployed in automated driving for 360\deg{} near-field sensing around the vehicle. This work presents a multi-task visual perception network on unrectified fisheye images to enable the vehicle to sense its surrounding environment. It consists of six primary tasks necessary for an autonomous driving system: depth estimation, visual odometry, semantic segmentation, motion segmentation, object detection, and lens soiling detection. We demonstrate that the jointly trained model performs better than the respective single task versions. Our multi-task model has a shared encoder providing a significant computational advantage and has synergized decoders where tasks support each other. We propose a novel camera geometry based adaptation mechanism to encode the fisheye distortion model both at training and inference. This was crucial to enable training on the WoodScape dataset, comprised of data from different parts of the world collected by 12 different cameras mounted on three different cars with different intrinsics and viewpoints. Given that bounding boxes is not a good representation for distorted fisheye images, we also extend object detection to use a polygon with non-uniformly sampled vertices. We additionally evaluate our model on standard automotive datasets, namely KITTI and Cityscapes. We obtain the state-of-the-art results on KITTI for depth estimation and pose estimation tasks and competitive performance on the other tasks. We perform extensive ablation studies on various architecture choices and task weighting methodologies. A short video at https://youtu.be/xbSjZ5OfPes provides qualitative results.