 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniDet: Surround View Cameras based Multi-task Visual Perception Network for Autonomous Driving
Feb 15, 2021
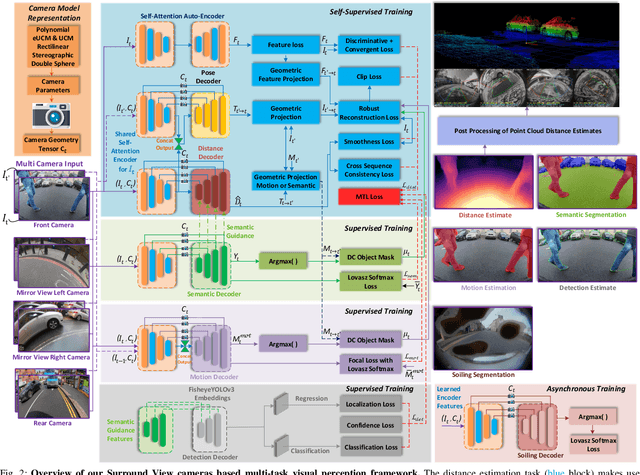
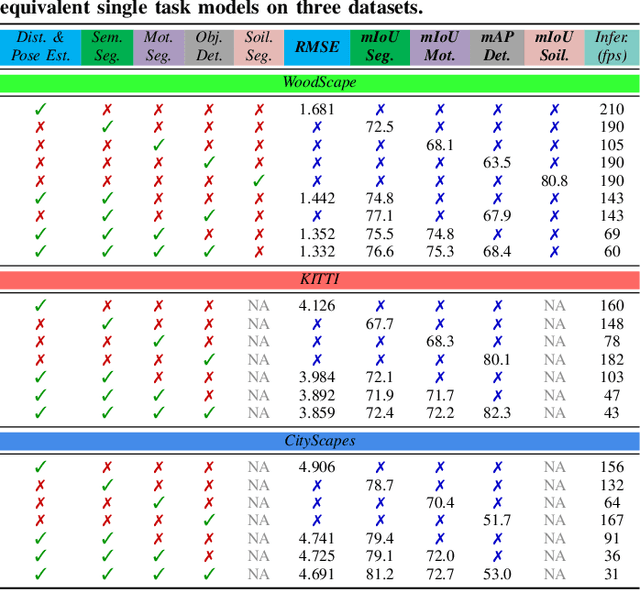
Surround View fisheye cameras are commonly deployed in automated driving for 360\deg{} near-field sensing around the vehicle. This work presents a multi-task visual perception network on unrectified fisheye images to enable the vehicle to sense its surrounding environment. It consists of six primary tasks necessary for an autonomous driving system: depth estimation, visual odometry, semantic segmentation, motion segmentation, object detection, and lens soiling detection. We demonstrate that the jointly trained model performs better than the respective single task versions. Our multi-task model has a shared encoder providing a significant computational advantage and has synergized decoders where tasks support each other. We propose a novel camera geometry based adaptation mechanism to encode the fisheye distortion model both at training and inference. This was crucial to enable training on the WoodScape dataset, comprised of data from different parts of the world collected by 12 different cameras mounted on three different cars with different intrinsics and viewpoints. Given that bounding boxes is not a good representation for distorted fisheye images, we also extend object detection to use a polygon with non-uniformly sampled vertices. We additionally evaluate our model on standard automotive datasets, namely KITTI and Cityscapes. We obtain the state-of-the-art results on KITTI for depth estimation and pose estimation tasks and competitive performance on the other tasks. We perform extensive ablation studies on various architecture choices and task weighting methodologies. A short video at https://youtu.be/xbSjZ5OfPes provides qualitative results.
Multi-Task Network Pruning and Embedded Optimization for Real-time Deployment in ADAS
Jan 19, 2021
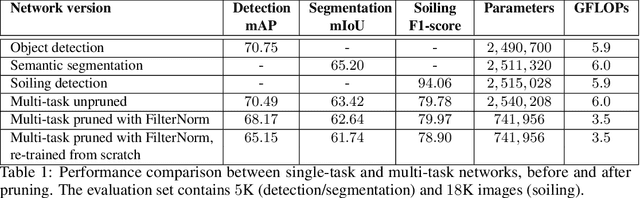
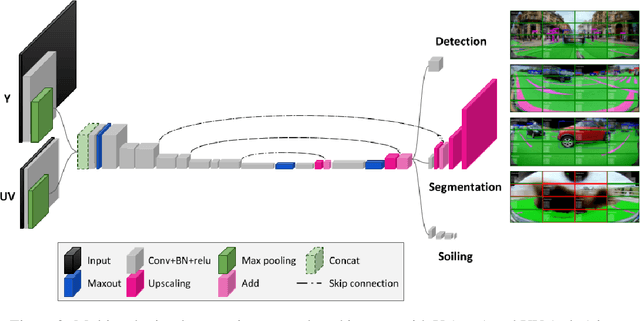
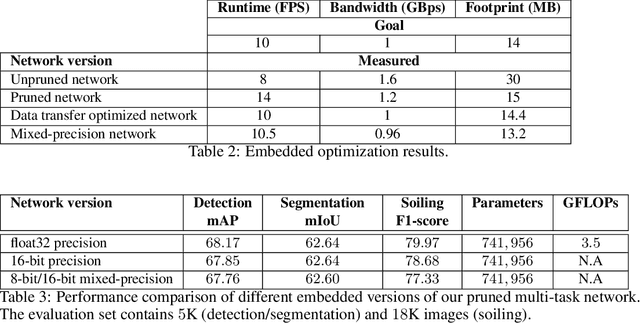
Camera-based Deep Learning algorithms are increasingly needed for perception in Automated Driving systems. However, constraints from the automotive industry challenge the deployment of CNNs by imposing embedded systems with limited computational resources. In this paper, we propose an approach to embed a multi-task CNN network under such conditions on a commercial prototype platform, i.e. a low power System on Chip (SoC) processing four surround-view fisheye cameras at 10 FPS. The first focus is on designing an efficient and compact multi-task network architecture. Secondly, a pruning method is applied to compress the CNN, helping to reduce the runtime and memory usage by a factor of 2 without lowering the performances significantly. Finally, several embedded optimization techniques such as mixed-quantization format usage and efficient data transfers between different memory areas are proposed to ensure real-time execution and avoid bandwidth bottlenecks. The approach is evaluated on the hardware platform, considering embedded detection performances, runtime and memory bandwidth. Unlike most works from the literature that focus on classification task, we aim here to study the effect of pruning and quantization on a compact multi-task network with object detection, semantic segmentation and soiling detection tasks.
Dynamic Task Weighting Methods for Multi-task Networks in Autonomous Driving Systems
Jan 07, 2020
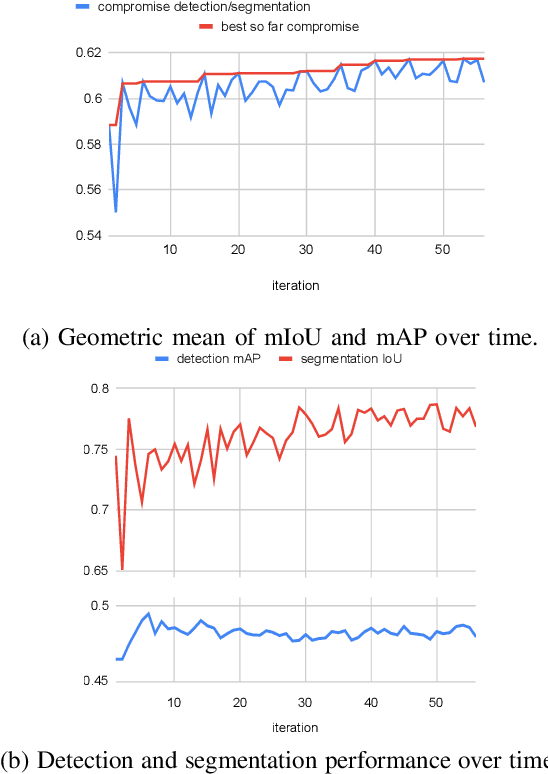
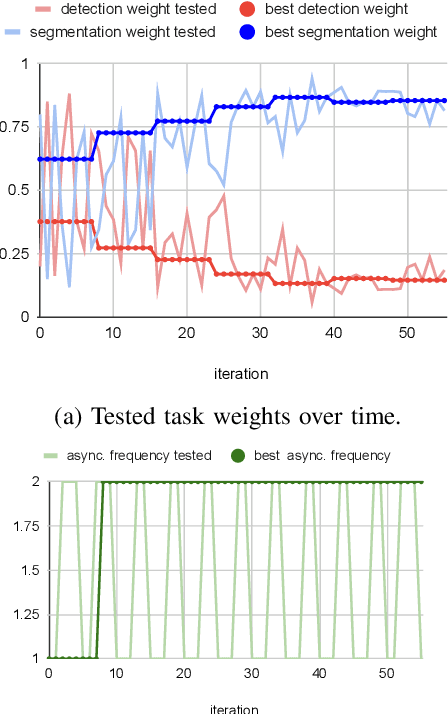
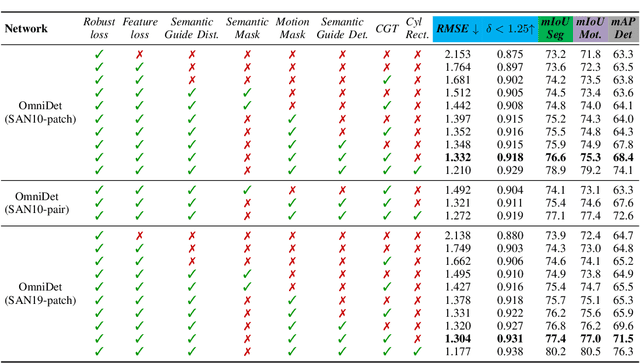
Deep multi-task networks are of particular interest for autonomous driving systems. They can potentially strike an excellent trade-off between predictive performance, hardware constraints and efficient use of information from multiple types of annotations and modalities. However, training such models is non-trivial and requires balancing the learning of all tasks as their respective losses display different scales, ranges and dynamics across training. Multiple task weighting methods that adjust the losses in an adaptive way have been proposed recently on different datasets and combinations of tasks, making it difficult to compare them. In this work, we review and systematically evaluate nine task weighting strategies on common grounds on three automotive datasets (KITTI, Cityscapes and WoodScape). We then propose a novel method combining evolutionary meta-learning and task-based selective backpropagation, for finding the task weights and training the network reliably. Our method outperforms state-of-the-art methods by $3\%$ on a two-task application.
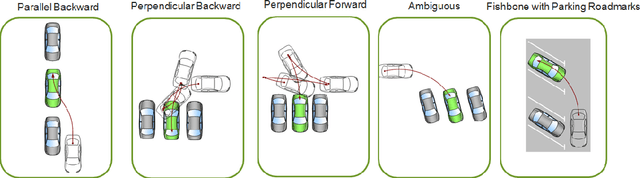
FisheyeMultiNet: Real-time Multi-task Learning Architecture for Surround-view Automated Parking System
Dec 23, 2019
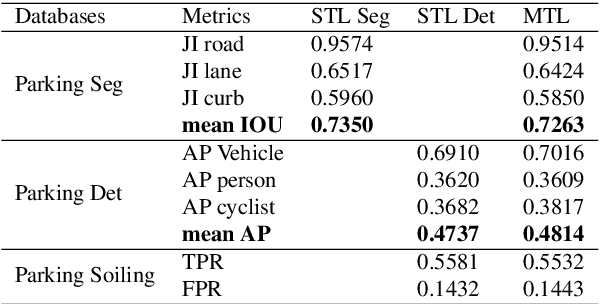
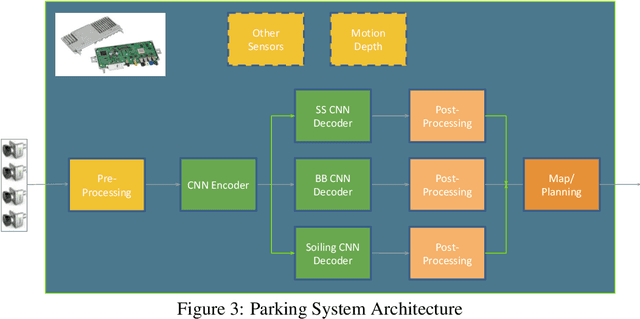
Automated Parking is a low speed manoeuvring scenario which is quite unstructured and complex, requiring full 360{\deg} near-field sensing around the vehicle. In this paper, we discuss the design and implementation of an automated parking system from the perspective of camera based deep learning algorithms. We provide a holistic overview of an industrial system covering the embedded system, use cases and the deep learning architecture. We demonstrate a real-time multi-task deep learning network called FisheyeMultiNet, which detects all the necessary objects for parking on a low-power embedded system. FisheyeMultiNet runs at 15 fps for 4 cameras and it has three tasks namely object detection, semantic segmentation and soiling detection. To encourage further research, we release a partial dataset of 5,000 images containing semantic segmentation and bounding box detection ground truth via WoodScape project \cite{yogamani2019woodscape}.
NeurAll: Towards a Unified Model for Visual Perception in Automated Driving
Feb 10, 2019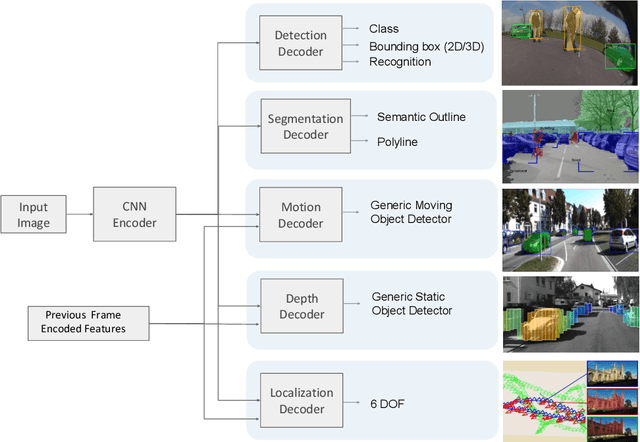
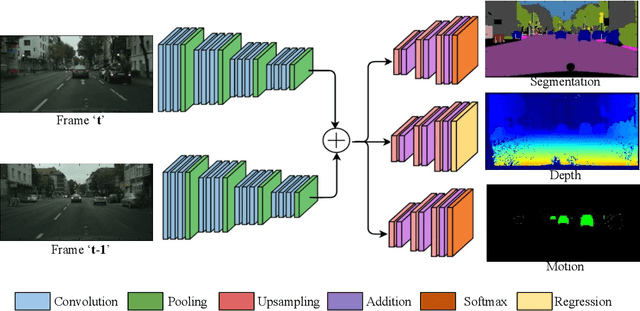

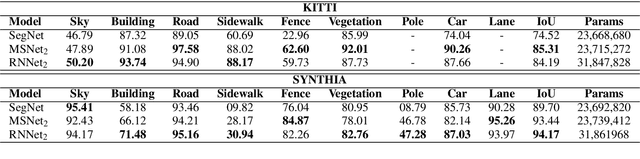
Convolutional Neural Networks (CNNs) are successfully used for the important automotive visual perception tasks including object recognition, motion and depth estimation, visual SLAM, etc. However, these tasks are independently explored and modeled. In this paper, we propose a joint multi-task network design called NeurAll for learning all tasks simultaneously. Our main motivation is the computational efficiency achieved by sharing the expensive initial convolutional layers between all tasks. Indeed, the main bottleneck in automated driving systems is the limited processing power available on deployment hardware. There could be other benefits in improving accuracy for some tasks and it eases development effort. It also offers scalability to add more tasks leveraging existing features and achieving better generalization. We survey various CNN based solutions for visual perception tasks in automated driving. Then we propose a unified CNN model for the important tasks and discuss several advanced optimization and architecture design techniques to improve the baseline model. The paper is partly review and partly positional with demonstration of several preliminary results promising for future research. Firstly, we show that an efficient two-task model performing semantic segmentation and object detection achieves similar accuracies compared to separate models on various datasets with minimized runtime. We then illustrate that using depth regression as auxiliary task improves semantic segmentation and using multi-stream semantic segmentation outperforms one-stream semantic segmentation. The two-task network achieves 30 fps on an automotive grade low power SOC for 1280x384 image resolution
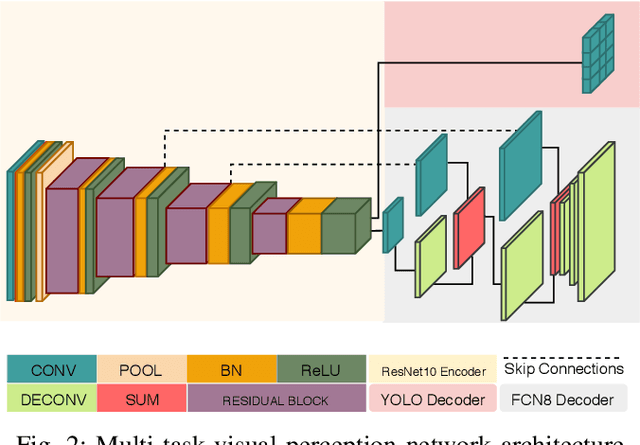
Real-time Joint Object Detection and Semantic Segmentation Network for Automated Driving
Jan 12, 2019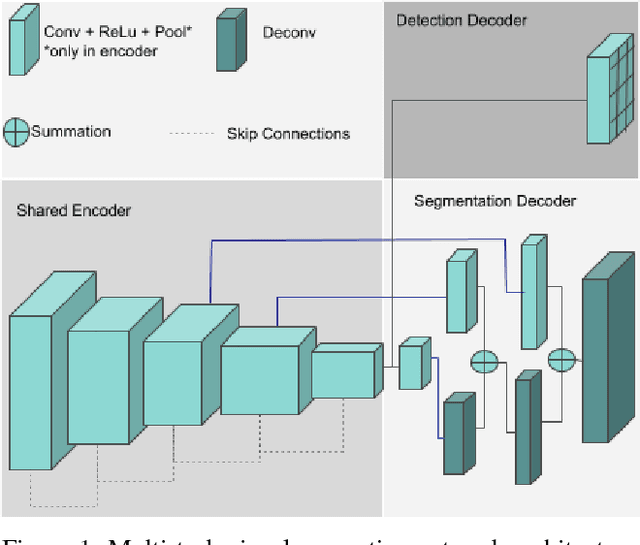
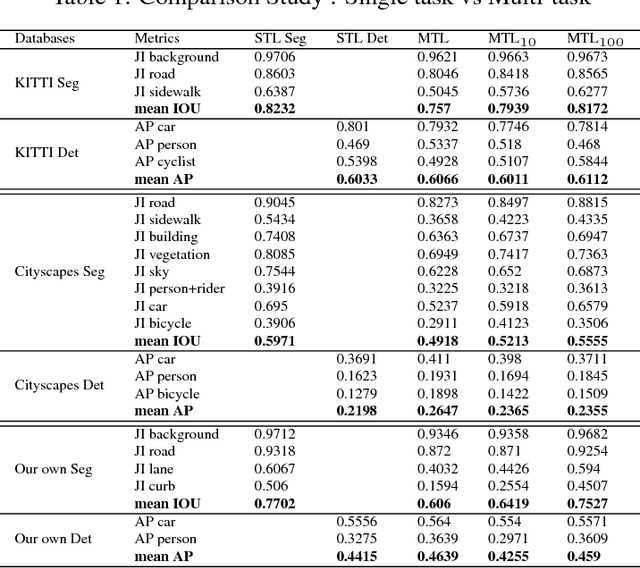

Convolutional Neural Networks (CNN) are successfully used for various visual perception tasks including bounding box object detection, semantic segmentation, optical flow, depth estimation and visual SLAM. Generally these tasks are independently explored and modeled. In this paper, we present a joint multi-task network design for learning object detection and semantic segmentation simultaneously. The main motivation is to achieve real-time performance on a low power embedded SOC by sharing of encoder for both the tasks. We construct an efficient architecture using a small ResNet10 like encoder which is shared for both decoders. Object detection uses YOLO v2 like decoder and semantic segmentation uses FCN8 like decoder. We evaluate the proposed network in two public datasets (KITTI, Cityscapes) and in our private fisheye camera dataset, and demonstrate that joint network provides the same accuracy as that of separate networks. We further optimize the network to achieve 30 fps for 1280x384 resolution image.