 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBotson: An Accessible and Low-Cost Platform for Social Robotics Research
Feb 23, 2026Trust remains a critical barrier to the effective integration of Artificial Intelligence (AI) into human-centric domains. Disembodied agents, such as voice assistants, often fail to establish trust due to their inability to convey non-verbal social cues. This paper introduces the architecture of Botson: an anthropomorphic social robot powered by a large language model (LLM). Botson was created as a low-cost and accessible platform for social robotics research.
Vehicular Applications of Koopman Operator Theory -- A Survey
Mar 21, 2023Koopman operator theory has proven to be a promising approach to nonlinear system identification and global linearization. For nearly a century, there had been no efficient means of calculating the Koopman operator for applied engineering purposes. The introduction of a recent computationally efficient method in the context of fluid dynamics, which is based on the system dynamics decomposition to a set of normal modes in descending order, has overcome this long-lasting computational obstacle. The purely data-driven nature of Koopman operators holds the promise of capturing unknown and complex dynamics for reduced-order model generation and system identification, through which the rich machinery of linear control techniques can be utilized. Given the ongoing development of this research area and the many existing open problems in the fields of smart mobility and vehicle engineering, a survey of techniques and open challenges of applying Koopman operator theory to this vibrant area is warranted. This review focuses on the various solutions of the Koopman operator which have emerged in recent years, particularly those focusing on mobility applications, ranging from characterization and component-level control operations to vehicle performance and fleet management. Moreover, this comprehensive review of over 100 research papers highlights the breadth of ways Koopman operator theory has been applied to various vehicular applications with a detailed categorization of the applied Koopman operator-based algorithm type. Furthermore, this review paper discusses theoretical aspects of Koopman operator theory that have been largely neglected by the smart mobility and vehicle engineering community and yet have large potential for contributing to solving open problems in these areas.
* Following a fruitful discussion with Professor Igor Mezic, the authors are providing a more detailed account of the roots of the modern-day engineering applications of the Koopman Operator Theory in this arXiv version
High-temporal-resolution event-based vehicle detection and tracking
Jan 02, 2023Event-based vision has been rapidly growing in recent years justified by the unique characteristics it presents such as its high temporal resolutions (~1us), high dynamic range (>120dB), and output latency of only a few microseconds. This work further explores a hybrid, multi-modal, approach for object detection and tracking that leverages state-of-the-art frame-based detectors complemented by hand-crafted event-based methods to improve the overall tracking performance with minimal computational overhead. The methods presented include event-based bounding box (BB) refinement that improves the precision of the resulting BBs, as well as a continuous event-based object detection method, to recover missed detections and generate inter-frame detections that enable a high-temporal-resolution tracking output. The advantages of these methods are quantitatively verified by an ablation study using the higher order tracking accuracy (HOTA) metric. Results show significant performance gains resembled by an improvement in the HOTA from 56.6%, using only frames, to 64.1% and 64.9%, for the event and edge-based mask configurations combined with the two methods proposed, at the baseline framerate of 24Hz. Likewise, incorporating these methods with the same configurations has improved HOTA from 52.5% to 63.1%, and from 51.3% to 60.2% at the high-temporal-resolution tracking rate of 384Hz. Finally, a validation experiment is conducted to analyze the real-world single-object tracking performance using high-speed LiDAR. Empirical evidence shows that our approaches provide significant advantages compared to using frame-based object detectors at the baseline framerate of 24Hz and higher tracking rates of up to 500Hz.
* 38 pages, 9 figures, 4 tables
RMOPP: Robust Multi-Objective Post-Processing for Effective Object Detection
Feb 09, 2021

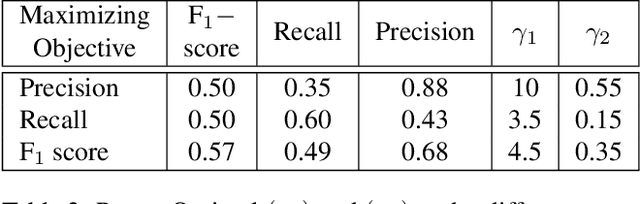
Over the last few decades, many architectures have been developed that harness the power of neural networks to detect objects in near real-time. Training such systems requires substantial time across multiple GPUs and massive labeled training datasets. Although the goal of these systems is generalizability, they are often impractical in real-life applications due to flexibility, robustness, or speed issues. This paper proposes RMOPP: A robust multi-objective post-processing algorithm to boost the performance of fast pre-trained object detectors with a negligible impact on their speed. Specifically, RMOPP is a statistically driven, post-processing algorithm that allows for simultaneous optimization of precision and recall. A unique feature of RMOPP is the Pareto frontier that identifies dominant possible post-processed detectors to optimize for both precision and recall. RMOPP explores the full potential of a pre-trained object detector and is deployable for near real-time predictions. We also provide a compelling test case on YOLOv2 using the MS-COCO dataset.
NeurAll: Towards a Unified Model for Visual Perception in Automated Driving
Feb 10, 2019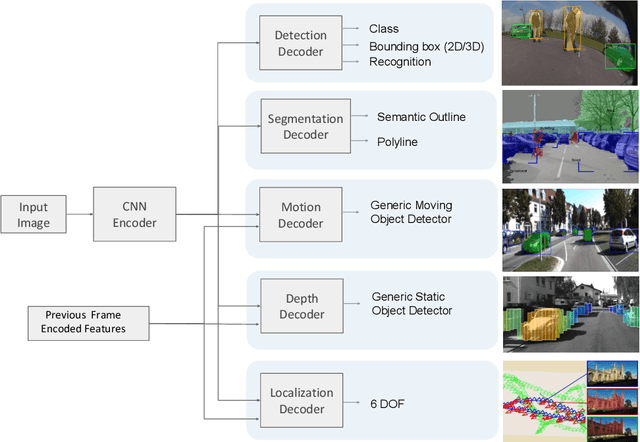
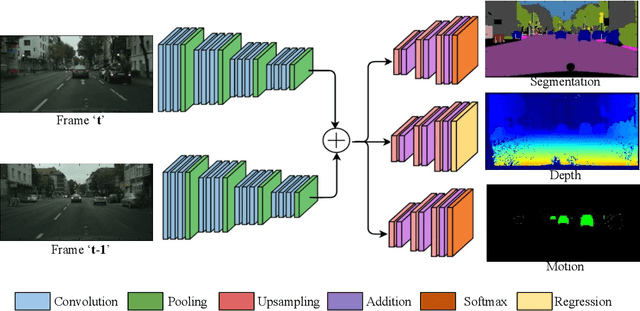

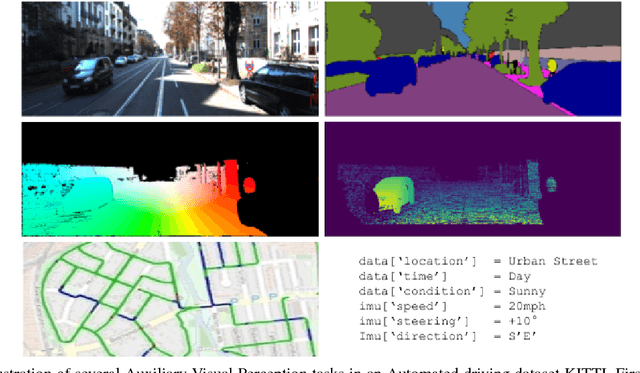
Convolutional Neural Networks (CNNs) are successfully used for the important automotive visual perception tasks including object recognition, motion and depth estimation, visual SLAM, etc. However, these tasks are independently explored and modeled. In this paper, we propose a joint multi-task network design called NeurAll for learning all tasks simultaneously. Our main motivation is the computational efficiency achieved by sharing the expensive initial convolutional layers between all tasks. Indeed, the main bottleneck in automated driving systems is the limited processing power available on deployment hardware. There could be other benefits in improving accuracy for some tasks and it eases development effort. It also offers scalability to add more tasks leveraging existing features and achieving better generalization. We survey various CNN based solutions for visual perception tasks in automated driving. Then we propose a unified CNN model for the important tasks and discuss several advanced optimization and architecture design techniques to improve the baseline model. The paper is partly review and partly positional with demonstration of several preliminary results promising for future research. Firstly, we show that an efficient two-task model performing semantic segmentation and object detection achieves similar accuracies compared to separate models on various datasets with minimized runtime. We then illustrate that using depth regression as auxiliary task improves semantic segmentation and using multi-stream semantic segmentation outperforms one-stream semantic segmentation. The two-task network achieves 30 fps on an automotive grade low power SOC for 1280x384 image resolution
AuxNet: Auxiliary tasks enhanced Semantic Segmentation for Automated Driving
Jan 17, 2019
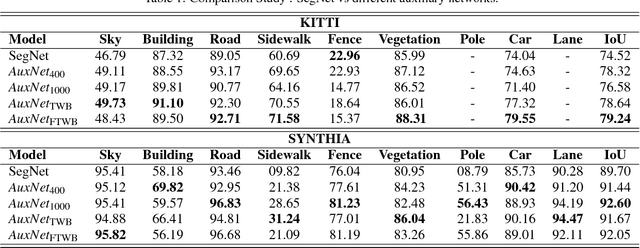
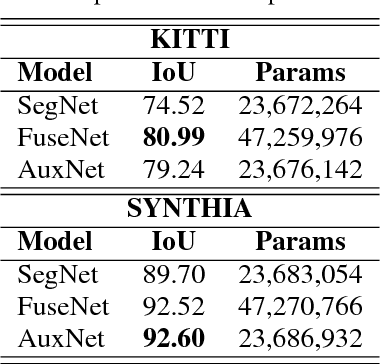
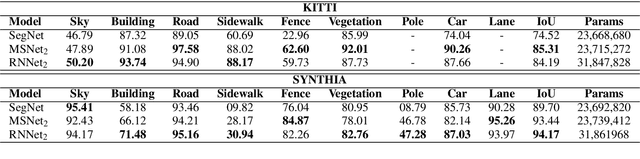
Decision making in automated driving is highly specific to the environment and thus semantic segmentation plays a key role in recognizing the objects in the environment around the car. Pixel level classification once considered a challenging task which is now becoming mature to be productized in a car. However, semantic annotation is time consuming and quite expensive. Synthetic datasets with domain adaptation techniques have been used to alleviate the lack of large annotated datasets. In this work, we explore an alternate approach of leveraging the annotations of other tasks to improve semantic segmentation. Recently, multi-task learning became a popular paradigm in automated driving which demonstrates joint learning of multiple tasks improves overall performance of each tasks. Motivated by this, we use auxiliary tasks like depth estimation to improve the performance of semantic segmentation task. We propose adaptive task loss weighting techniques to address scale issues in multi-task loss functions which become more crucial in auxiliary tasks. We experimented on automotive datasets including SYNTHIA and KITTI and obtained 3% and 5% improvement in accuracy respectively.