 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Pixel-Level Contrastive Learning-based Source-Free Domain Adaptation for Video Semantic Segmentation
Mar 25, 2023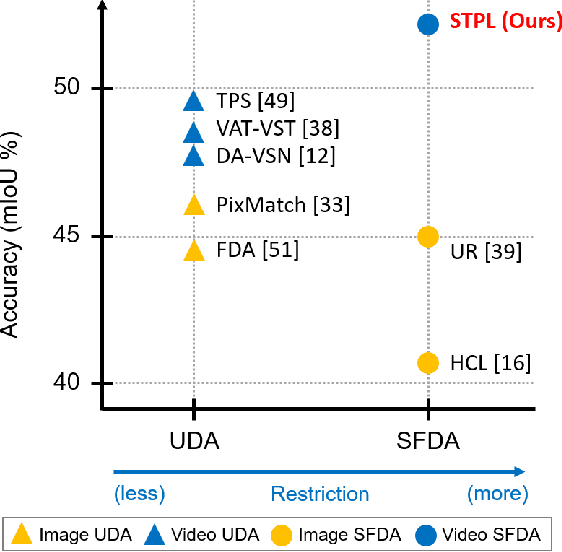
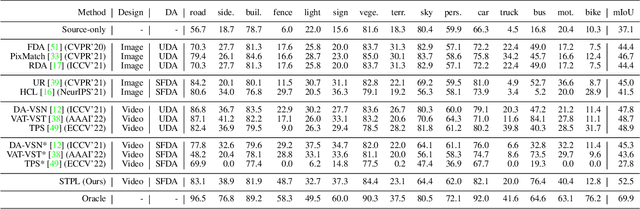
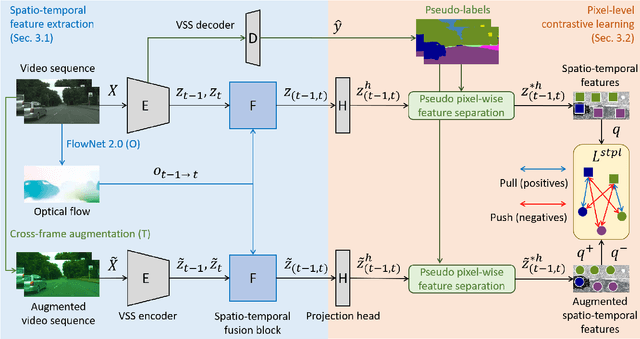
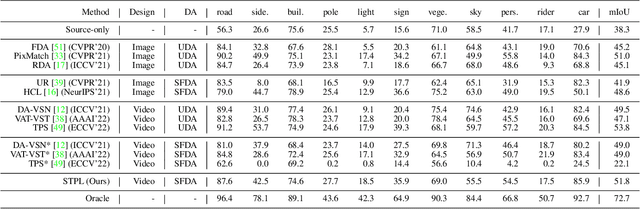
Unsupervised Domain Adaptation (UDA) of semantic segmentation transfers labeled source knowledge to an unlabeled target domain by relying on accessing both the source and target data. However, the access to source data is often restricted or infeasible in real-world scenarios. Under the source data restrictive circumstances, UDA is less practical. To address this, recent works have explored solutions under the Source-Free Domain Adaptation (SFDA) setup, which aims to adapt a source-trained model to the target domain without accessing source data. Still, existing SFDA approaches use only image-level information for adaptation, making them sub-optimal in video applications. This paper studies SFDA for Video Semantic Segmentation (VSS), where temporal information is leveraged to address video adaptation. Specifically, we propose Spatio-Temporal Pixel-Level (STPL) contrastive learning, a novel method that takes full advantage of spatio-temporal information to tackle the absence of source data better. STPL explicitly learns semantic correlations among pixels in the spatio-temporal space, providing strong self-supervision for adaptation to the unlabeled target domain. Extensive experiments show that STPL achieves state-of-the-art performance on VSS benchmarks compared to current UDA and SFDA approaches. Code is available at: https://github.com/shaoyuanlo/STPL
Adaptive Distillation: Aggregating Knowledge from Multiple Paths for Efficient Distillation
Oct 24, 2021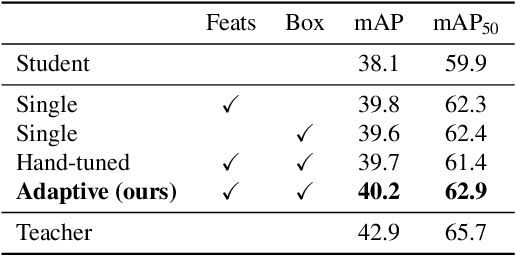
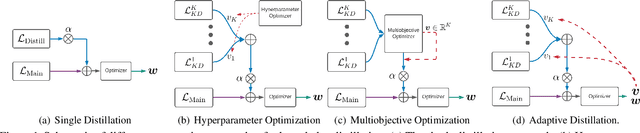
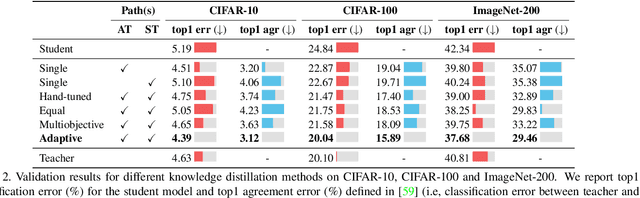
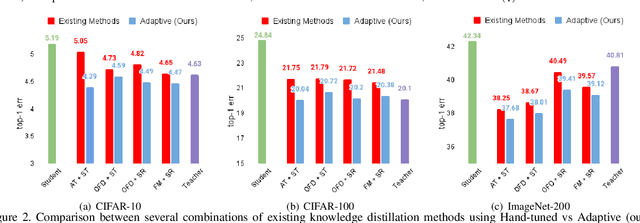
Knowledge Distillation is becoming one of the primary trends among neural network compression algorithms to improve the generalization performance of a smaller student model with guidance from a larger teacher model. This momentous rise in applications of knowledge distillation is accompanied by the introduction of numerous algorithms for distilling the knowledge such as soft targets and hint layers. Despite this advancement in different techniques for distilling the knowledge, the aggregation of different paths for distillation has not been studied comprehensively. This is of particular significance, not only because different paths have different importance, but also due to the fact that some paths might have negative effects on the generalization performance of the student model. Hence, we need to adaptively adjust the importance of each path to maximize the impact of distillation on the student model. In this paper, we explore different approaches for aggregating these different paths and introduce our proposed adaptive approach based on multitask learning methods. We empirically demonstrate the effectiveness of the proposed approach over other baselines on the applications of knowledge distillation in classification, semantic segmentation, and object detection tasks.
Learning Panoptic Segmentation from Instance Contours
Oct 16, 2020
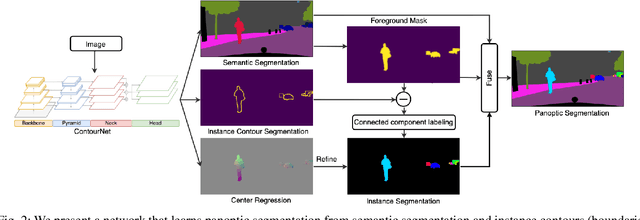
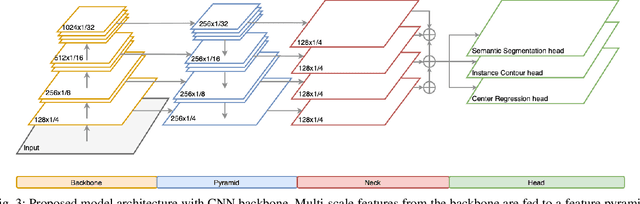
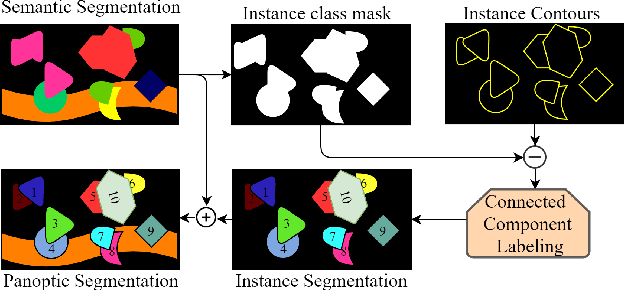
Panoptic Segmentation aims to provide an understanding of background (stuff) and instances of objects (things) at a pixel level. It combines the separate tasks of semantic segmentation (pixel-level classification) and instance segmentation to build a single unified scene understanding task. Typically, panoptic segmentation is derived by combining semantic and instance segmentation tasks that are learned separately or jointly (multi-task networks). In general, instance segmentation networks are built by adding a foreground mask estimation layer on top of object detectors or using instance clustering methods that assign a pixel to an instance center. In this work, we present a fully convolution neural network that learns instance segmentation from semantic segmentation and instance contours (boundaries of things). Instance contours along with semantic segmentation yield a boundary-aware semantic segmentation of things. Connected component labeling on these results produces instance segmentation. We merge semantic and instance segmentation results to output panoptic segmentation. We evaluate our proposed method on the CityScapes dataset to demonstrate qualitative and quantitative performances along with several ablation studies.
Adaptive Hierarchical Decomposition of Large Deep Networks
Jul 17, 2020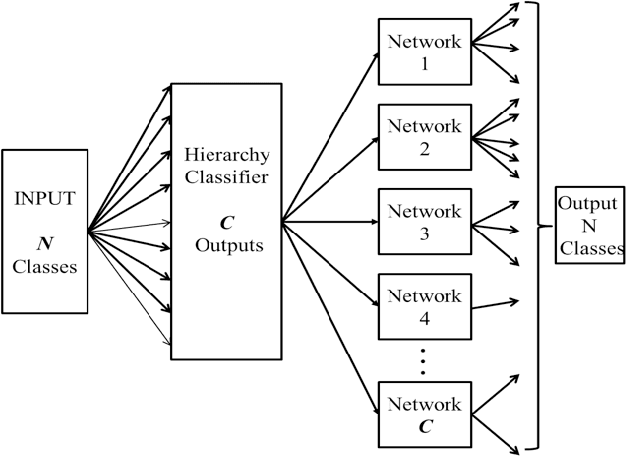
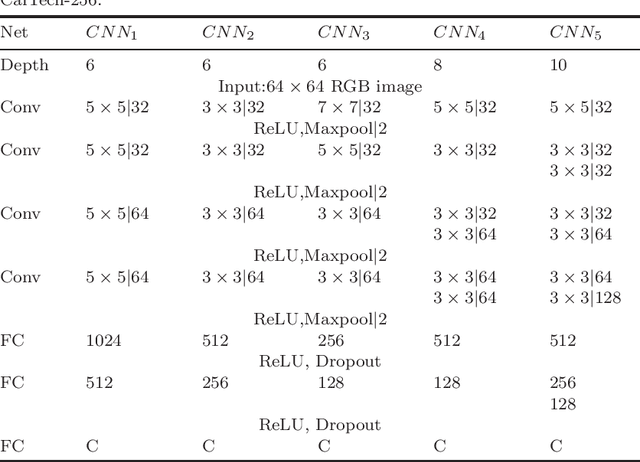

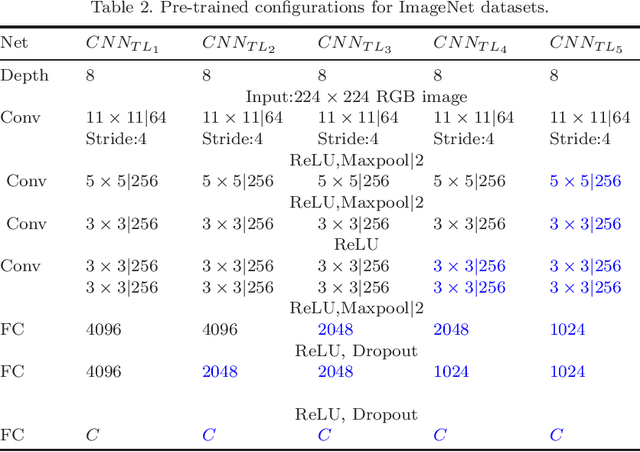
Deep learning has recently demonstrated its ability to rival the human brain for visual object recognition. As datasets get larger, a natural question to ask is if existing deep learning architectures can be extended to handle the 50+K classes thought to be perceptible by a typical human. Most deep learning architectures concentrate on splitting diverse categories, while ignoring the similarities amongst them. This paper introduces a framework that automatically analyzes and configures a family of smaller deep networks as a replacement to a singular, larger network. Class similarities guide the creation of a family from course to fine classifiers which solve categorical problems more effectively than a single large classifier. The resulting smaller networks are highly scalable, parallel and more practical to train, and achieve higher classification accuracy. This paper also proposes a method to adaptively select the configuration of the hierarchical family of classifiers using linkage statistics from overall and sub-classification confusion matrices. Depending on the number of classes and the complexity of the problem, a deep learning model is selected and the complexity is determined. Numerous experiments on network classes, layers, and architecture configurations validate our results.
FisheyeMultiNet: Real-time Multi-task Learning Architecture for Surround-view Automated Parking System
Dec 23, 2019
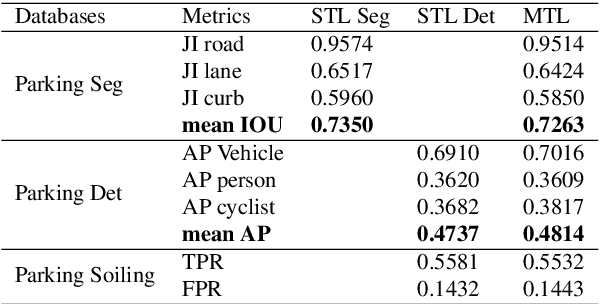
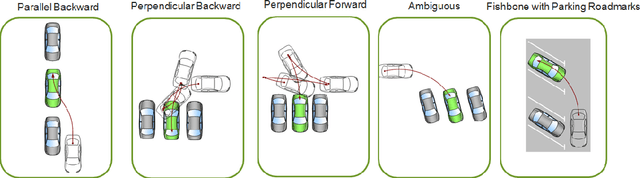
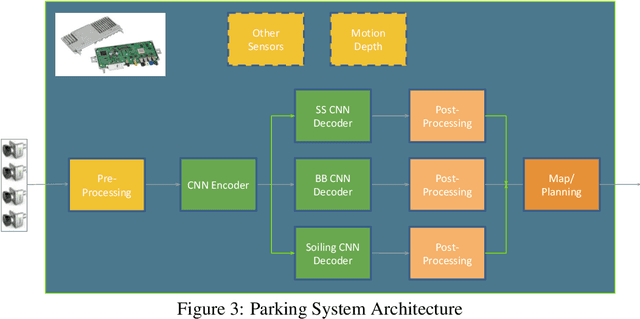
Automated Parking is a low speed manoeuvring scenario which is quite unstructured and complex, requiring full 360{\deg} near-field sensing around the vehicle. In this paper, we discuss the design and implementation of an automated parking system from the perspective of camera based deep learning algorithms. We provide a holistic overview of an industrial system covering the embedded system, use cases and the deep learning architecture. We demonstrate a real-time multi-task deep learning network called FisheyeMultiNet, which detects all the necessary objects for parking on a low-power embedded system. FisheyeMultiNet runs at 15 fps for 4 cameras and it has three tasks namely object detection, semantic segmentation and soiling detection. To encourage further research, we release a partial dataset of 5,000 images containing semantic segmentation and bounding box detection ground truth via WoodScape project \cite{yogamani2019woodscape}.
WoodScape: A multi-task, multi-camera fisheye dataset for autonomous driving
May 04, 2019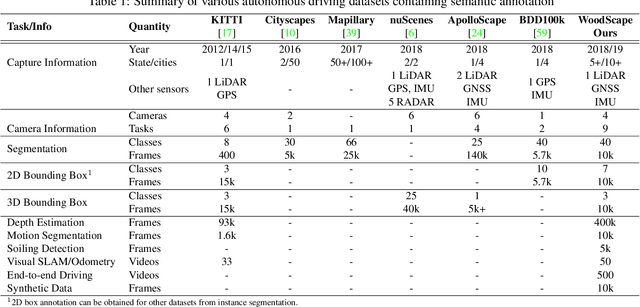
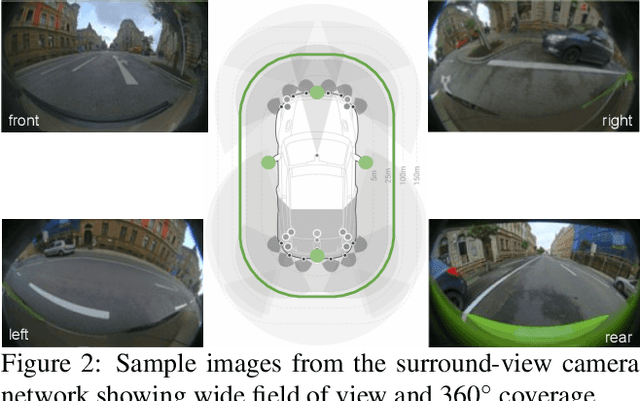
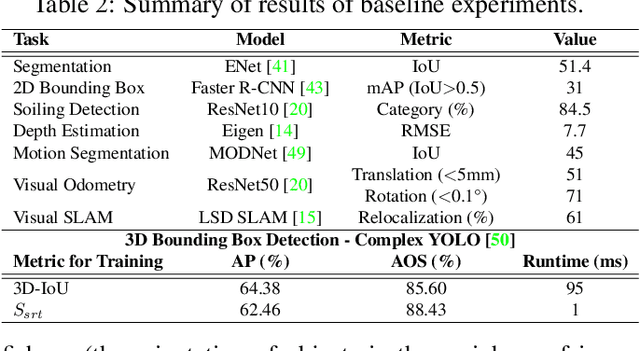
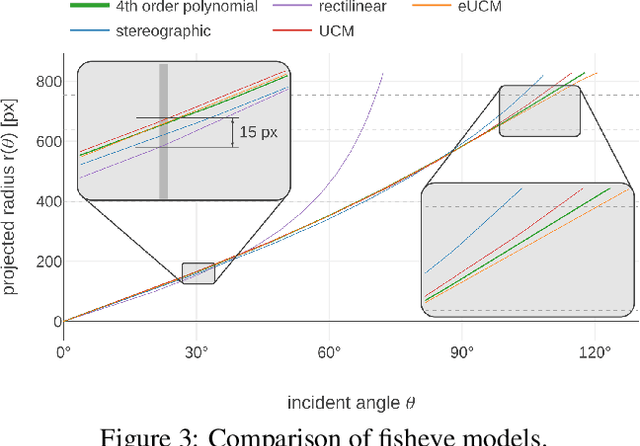
Fisheye cameras are commonly employed for obtaining a large field of view in surveillance, augmented reality and in particular automotive applications. In spite of its prevalence, there are few public datasets for detailed evaluation of computer vision algorithms on fisheye images. We release the first extensive fisheye automotive dataset, WoodScape, named after Robert Wood who invented the fisheye camera in 1906. WoodScape comprises of four surround view cameras and nine tasks including segmentation, depth estimation, 3D bounding box detection and soiling detection. Semantic annotation of 40 classes at the instance level is provided for over 10,000 images and annotation for other tasks are provided for over 100,000 images. We would like to encourage the community to adapt computer vision models for fisheye camera instead of naive rectification.
MultiNet++: Multi-Stream Feature Aggregation and Geometric Loss Strategy for Multi-Task Learning
Apr 22, 2019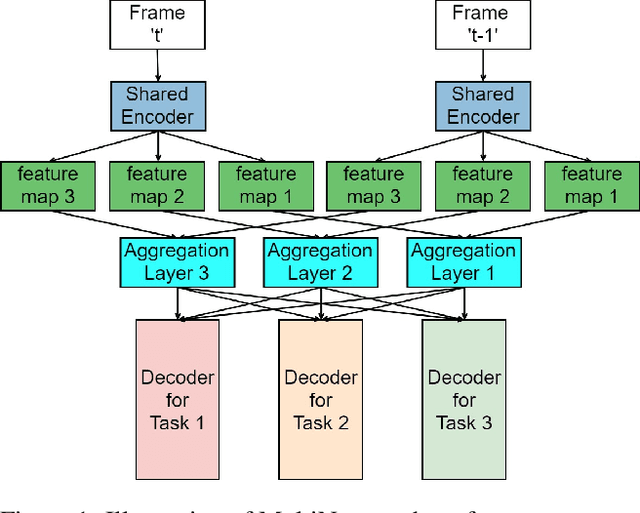

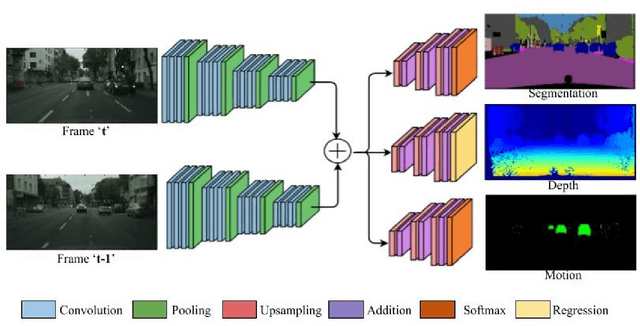
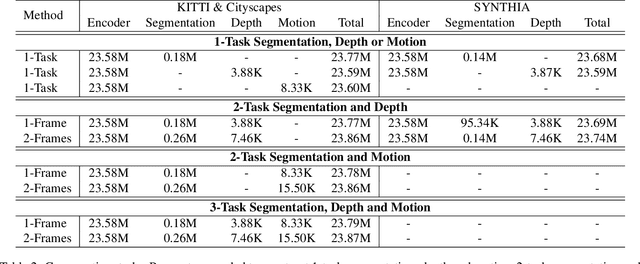
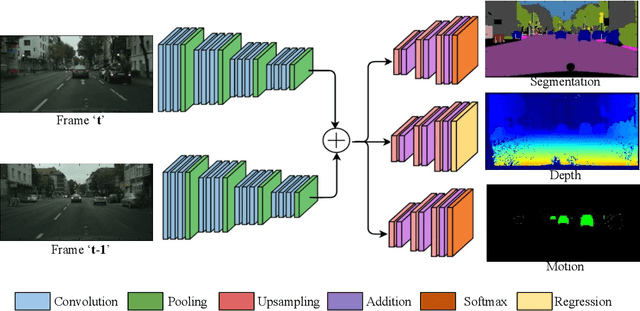
Multi-task learning is commonly used in autonomous driving for solving various visual perception tasks. It offers significant benefits in terms of both performance and computational complexity. Current work on multi-task learning networks focus on processing a single input image and there is no known implementation of multi-task learning handling a sequence of images. In this work, we propose a multi-stream multi-task network to take advantage of using feature representations from preceding frames in a video sequence for joint learning of segmentation, depth, and motion. The weights of the current and previous encoder are shared so that features computed in the previous frame can be leveraged without additional computation. In addition, we propose to use the geometric mean of task losses as a better alternative to the weighted average of task losses. The proposed loss function facilitates better handling of the difference in convergence rates of different tasks. Experimental results on KITTI, Cityscapes and SYNTHIA datasets demonstrate that the proposed strategies outperform various existing multi-task learning solutions.
NeurAll: Towards a Unified Model for Visual Perception in Automated Driving
Feb 10, 2019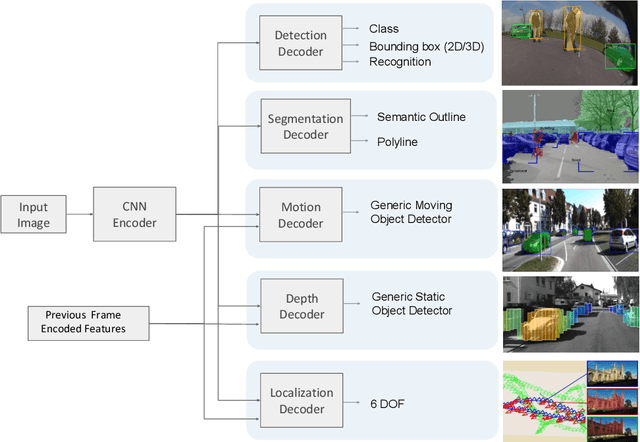

Convolutional Neural Networks (CNNs) are successfully used for the important automotive visual perception tasks including object recognition, motion and depth estimation, visual SLAM, etc. However, these tasks are independently explored and modeled. In this paper, we propose a joint multi-task network design called NeurAll for learning all tasks simultaneously. Our main motivation is the computational efficiency achieved by sharing the expensive initial convolutional layers between all tasks. Indeed, the main bottleneck in automated driving systems is the limited processing power available on deployment hardware. There could be other benefits in improving accuracy for some tasks and it eases development effort. It also offers scalability to add more tasks leveraging existing features and achieving better generalization. We survey various CNN based solutions for visual perception tasks in automated driving. Then we propose a unified CNN model for the important tasks and discuss several advanced optimization and architecture design techniques to improve the baseline model. The paper is partly review and partly positional with demonstration of several preliminary results promising for future research. Firstly, we show that an efficient two-task model performing semantic segmentation and object detection achieves similar accuracies compared to separate models on various datasets with minimized runtime. We then illustrate that using depth regression as auxiliary task improves semantic segmentation and using multi-stream semantic segmentation outperforms one-stream semantic segmentation. The two-task network achieves 30 fps on an automotive grade low power SOC for 1280x384 image resolution
AuxNet: Auxiliary tasks enhanced Semantic Segmentation for Automated Driving
Jan 17, 2019
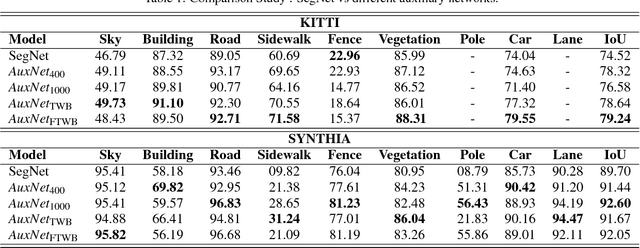
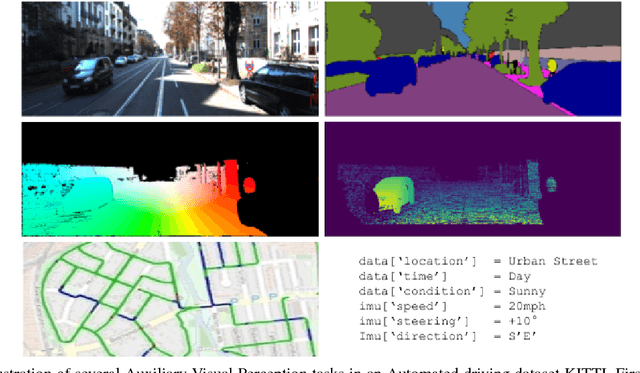
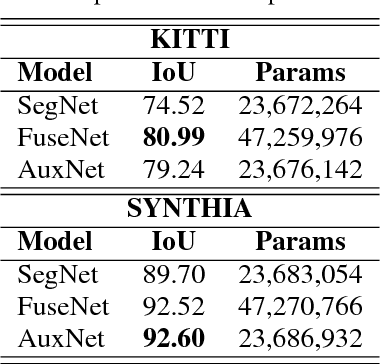
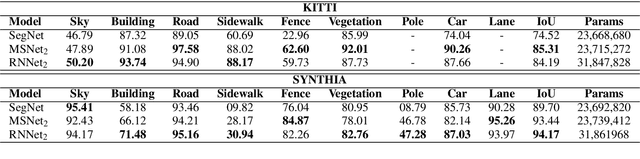
Decision making in automated driving is highly specific to the environment and thus semantic segmentation plays a key role in recognizing the objects in the environment around the car. Pixel level classification once considered a challenging task which is now becoming mature to be productized in a car. However, semantic annotation is time consuming and quite expensive. Synthetic datasets with domain adaptation techniques have been used to alleviate the lack of large annotated datasets. In this work, we explore an alternate approach of leveraging the annotations of other tasks to improve semantic segmentation. Recently, multi-task learning became a popular paradigm in automated driving which demonstrates joint learning of multiple tasks improves overall performance of each tasks. Motivated by this, we use auxiliary tasks like depth estimation to improve the performance of semantic segmentation task. We propose adaptive task loss weighting techniques to address scale issues in multi-task loss functions which become more crucial in auxiliary tasks. We experimented on automotive datasets including SYNTHIA and KITTI and obtained 3% and 5% improvement in accuracy respectively.
Multi-stream CNN based Video Semantic Segmentation for Automated Driving
Jan 08, 2019
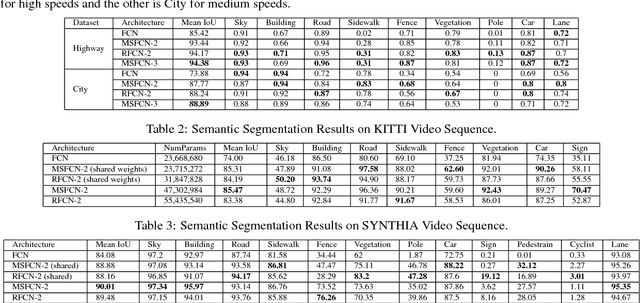

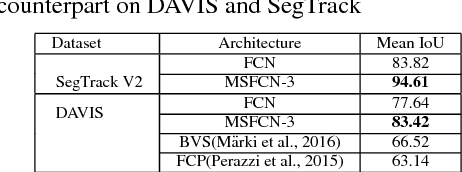
Majority of semantic segmentation algorithms operate on a single frame even in the case of videos. In this work, the goal is to exploit temporal information within the algorithm model for leveraging motion cues and temporal consistency. We propose two simple high-level architectures based on Recurrent FCN (RFCN) and Multi-Stream FCN (MSFCN) networks. In case of RFCN, a recurrent network namely LSTM is inserted between the encoder and decoder. MSFCN combines the encoders of different frames into a fused encoder via 1x1 channel-wise convolution. We use a ResNet50 network as the baseline encoder and construct three networks namely MSFCN of order 2 & 3 and RFCN of order 2. MSFCN-3 produces the best results with an accuracy improvement of 9% and 15% for Highway and New York-like city scenarios in the SYNTHIA-CVPR'16 dataset using mean IoU metric. MSFCN-3 also produced 11% and 6% for SegTrack V2 and DAVIS datasets over the baseline FCN network. We also designed an efficient version of MSFCN-2 and RFCN-2 using weight sharing among the two encoders. The efficient MSFCN-2 provided an improvement of 11% and 5% for KITTI and SYNTHIA with negligible increase in computational complexity compared to the baseline version.