 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Pixel-Level Contrastive Learning-based Source-Free Domain Adaptation for Video Semantic Segmentation
Mar 25, 2023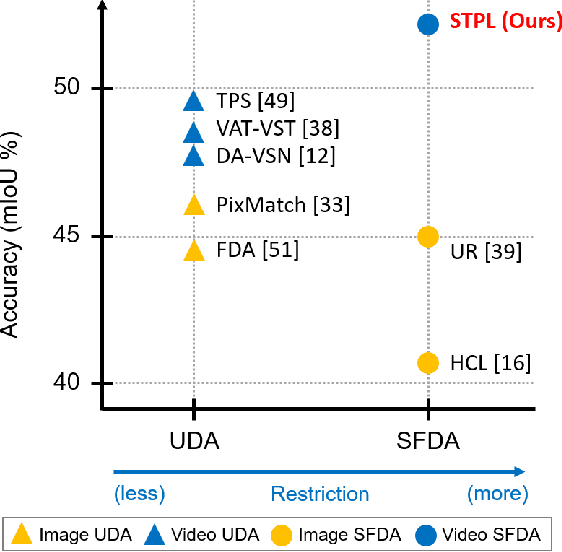
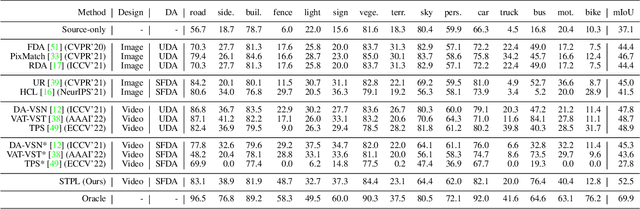
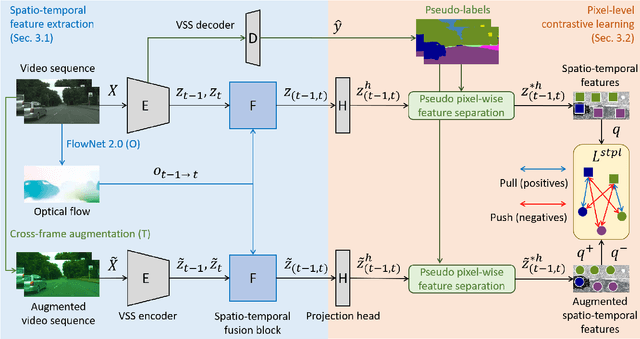
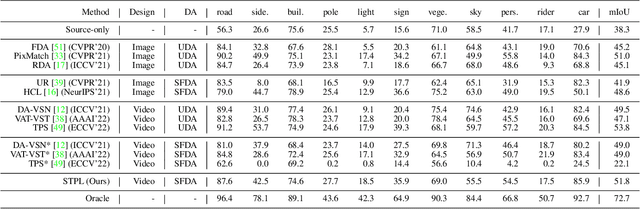
Unsupervised Domain Adaptation (UDA) of semantic segmentation transfers labeled source knowledge to an unlabeled target domain by relying on accessing both the source and target data. However, the access to source data is often restricted or infeasible in real-world scenarios. Under the source data restrictive circumstances, UDA is less practical. To address this, recent works have explored solutions under the Source-Free Domain Adaptation (SFDA) setup, which aims to adapt a source-trained model to the target domain without accessing source data. Still, existing SFDA approaches use only image-level information for adaptation, making them sub-optimal in video applications. This paper studies SFDA for Video Semantic Segmentation (VSS), where temporal information is leveraged to address video adaptation. Specifically, we propose Spatio-Temporal Pixel-Level (STPL) contrastive learning, a novel method that takes full advantage of spatio-temporal information to tackle the absence of source data better. STPL explicitly learns semantic correlations among pixels in the spatio-temporal space, providing strong self-supervision for adaptation to the unlabeled target domain. Extensive experiments show that STPL achieves state-of-the-art performance on VSS benchmarks compared to current UDA and SFDA approaches. Code is available at: https://github.com/shaoyuanlo/STPL
Towards Online Domain Adaptive Object Detection
Apr 11, 2022
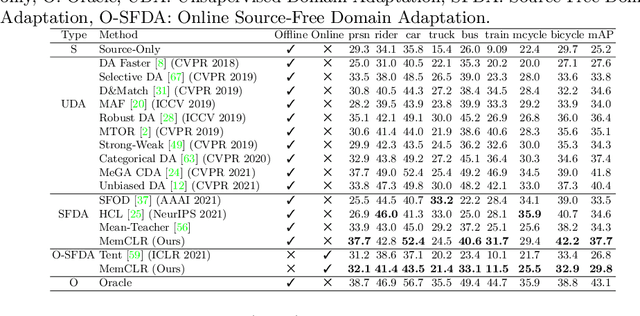
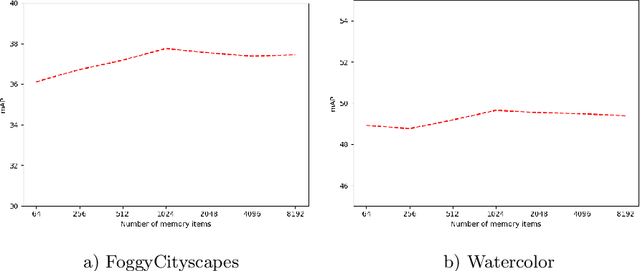
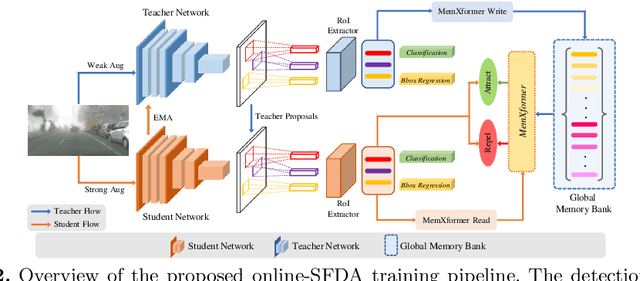
Existing object detection models assume both the training and test data are sampled from the same source domain. This assumption does not hold true when these detectors are deployed in real-world applications, where they encounter new visual domain. Unsupervised Domain Adaptation (UDA) methods are generally employed to mitigate the adverse effects caused by domain shift. Existing UDA methods operate in an offline manner where the model is first adapted towards the target domain and then deployed in real-world applications. However, this offline adaptation strategy is not suitable for real-world applications as the model frequently encounters new domain shifts. Hence, it becomes critical to develop a feasible UDA method that generalizes to these domain shifts encountered during deployment time in a continuous online manner. To this end, we propose a novel unified adaptation framework that adapts and improves generalization on the target domain in online settings. In particular, we introduce MemXformer - a cross-attention transformer-based memory module where items in the memory take advantage of domain shifts and record prototypical patterns of the target distribution. Further, MemXformer produces strong positive and negative pairs to guide a novel contrastive loss, which enhances target specific representation learning. Experiments on diverse detection benchmarks show that the proposed strategy can produce state-of-the-art performance in both online and offline settings. To the best of our knowledge, this is the first work to address online and offline adaptation settings for object detection. Code at https://github.com/Vibashan/online-od
Instance Relation Graph Guided Source-Free Domain Adaptive Object Detection
Apr 01, 2022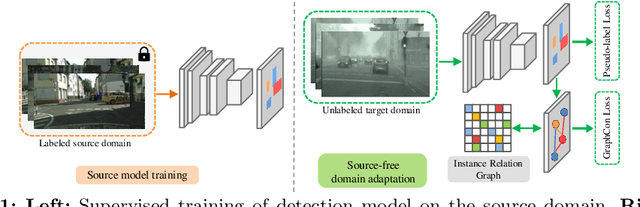
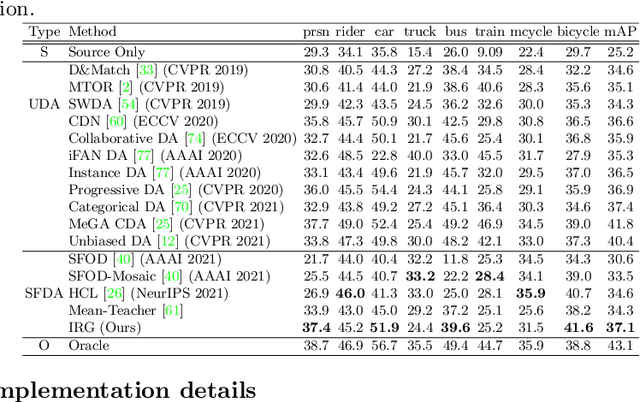
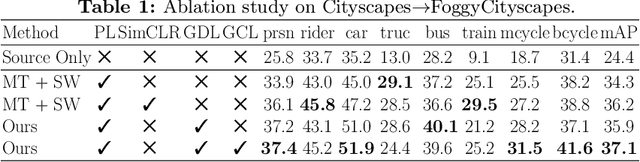
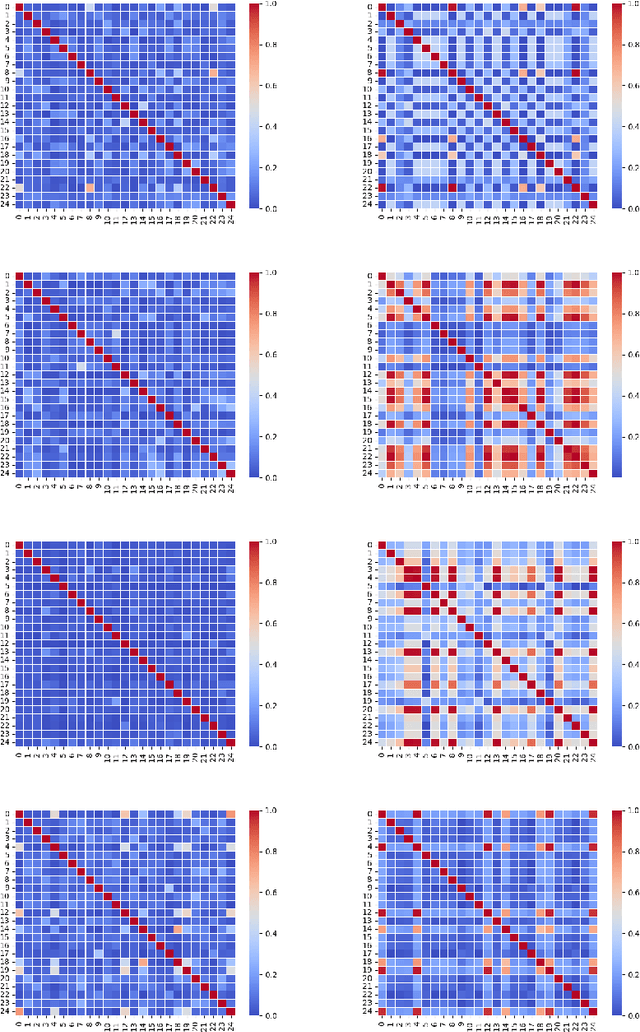
Unsupervised Domain Adaptation (UDA) is an effective approach to tackle the issue of domain shift. Specifically, UDA methods try to align the source and target representations to improve the generalization on the target domain. Further, UDA methods work under the assumption that the source data is accessible during the adaptation process. However, in real-world scenarios, the labelled source data is often restricted due to privacy regulations, data transmission constraints, or proprietary data concerns. The Source-Free Domain Adaptation (SFDA) setting aims to alleviate these concerns by adapting a source-trained model for the target domain without requiring access to the source data. In this paper, we explore the SFDA setting for the task of adaptive object detection. To this end, we propose a novel training strategy for adapting a source-trained object detector to the target domain without source data. More precisely, we design a novel contrastive loss to enhance the target representations by exploiting the objects relations for a given target domain input. These object instance relations are modelled using an Instance Relation Graph (IRG) network, which are then used to guide the contrastive representation learning. In addition, we utilize a student-teacher based knowledge distillation strategy to avoid overfitting to the noisy pseudo-labels generated by the source-trained model. Extensive experiments on multiple object detection benchmark datasets show that the proposed approach is able to efficiently adapt source-trained object detectors to the target domain, outperforming previous state-of-the-art domain adaptive detection methods. Code is available at https://github.com/Vibashan/irg-sfda.
Adversarially Robust One-class Novelty Detection
Aug 25, 2021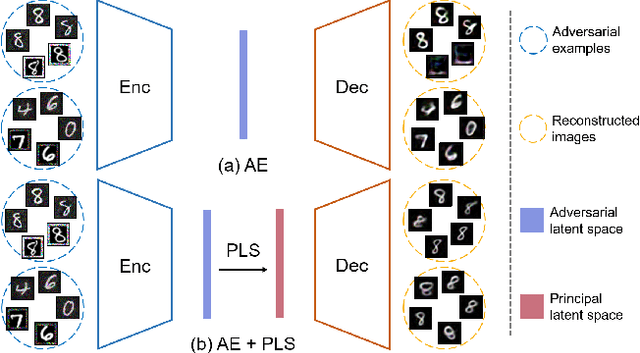
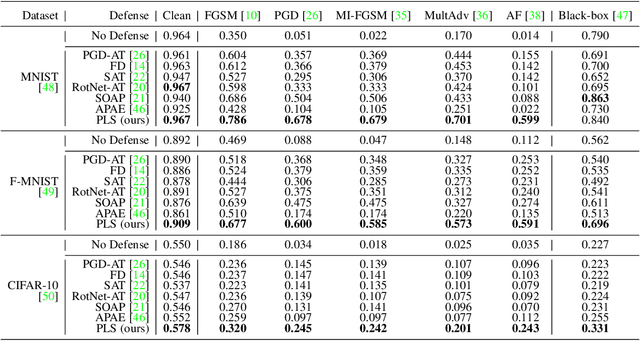
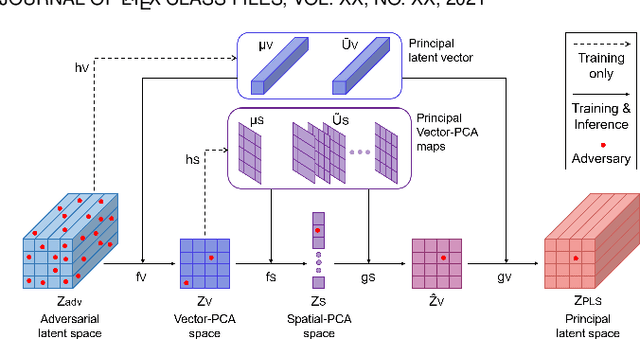
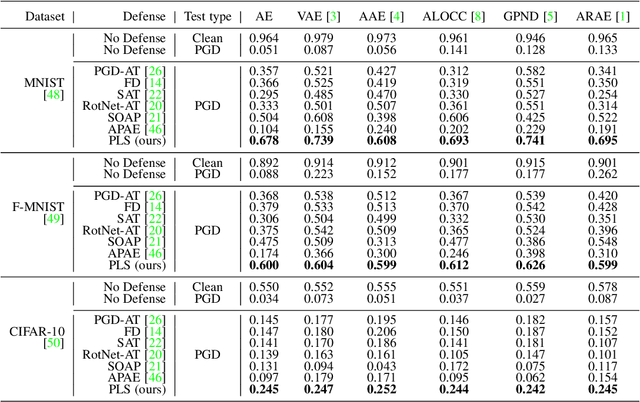
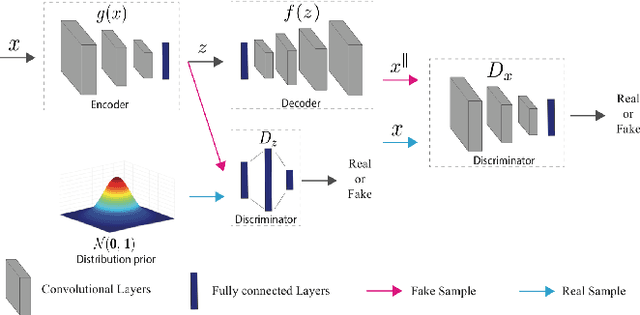
One-class novelty detectors are trained with examples of a particular class and are tasked with identifying whether a query example belongs to the same known class. Most recent advances adopt a deep auto-encoder style architecture to compute novelty scores for detecting novel class data. Deep networks have shown to be vulnerable to adversarial attacks, yet little focus is devoted to studying the adversarial robustness of deep novelty detectors. In this paper, we first show that existing novelty detectors are susceptible to adversarial examples. We further demonstrate that commonly-used defense approaches for classification tasks have limited effectiveness in one-class novelty detection. Hence, we need a defense specifically designed for novelty detection. To this end, we propose a defense strategy that manipulates the latent space of novelty detectors to improve the robustness against adversarial examples. The proposed method, referred to as Principal Latent Space (PLS), learns the incrementally-trained cascade principal components in the latent space to robustify novelty detectors. PLS can purify latent space against adversarial examples and constrain latent space to exclusively model the known class distribution. We conduct extensive experiments on multiple attacks, datasets and novelty detectors, showing that PLS consistently enhances the adversarial robustness of novelty detection models.
Image Fusion Transformer
Aug 05, 2021
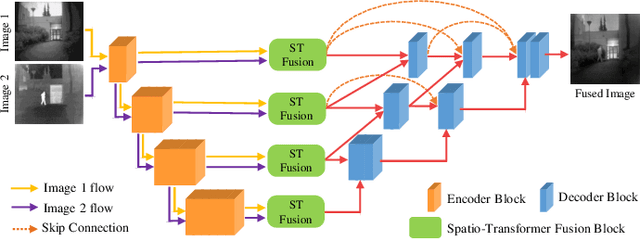
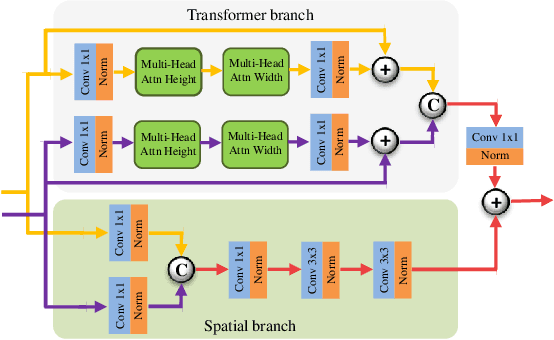
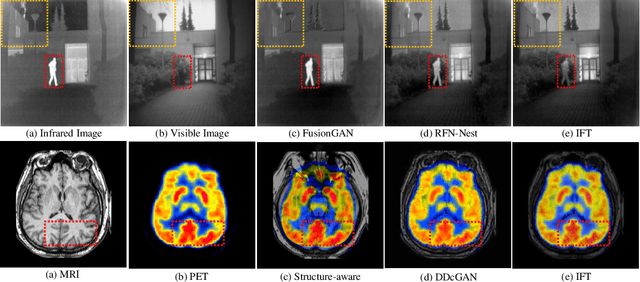
In image fusion, images obtained from different sensors are fused to generate a single image with enhanced information. In recent years, state-of-the-art methods have adopted Convolution Neural Networks (CNNs) to encode meaningful features for image fusion. Specifically, CNN-based methods perform image fusion by fusing local features. However, they do not consider long-range dependencies that are present in the image. Transformer-based models are designed to overcome this by modeling the long-range dependencies with the help of self-attention mechanism. This motivates us to propose a novel Image Fusion Transformer (IFT) where we develop a transformer-based multi-scale fusion strategy that attends to both local and long-range information (or global context). The proposed method follows a two-stage training approach. In the first stage, we train an auto-encoder to extract deep features at multiple scales. In the second stage, multi-scale features are fused using a Spatio-Transformer (ST) fusion strategy. The ST fusion blocks are comprised of a CNN and a transformer branch which capture local and long-range features, respectively. Extensive experiments on multiple benchmark datasets show that the proposed method performs better than many competitive fusion algorithms. Furthermore, we show the effectiveness of the proposed ST fusion strategy with an ablation analysis. The source code is available at: https://github.com/Vibashan/Image-Fusion-Transformer.
Unsupervised Domain Adaption of Object Detectors: A Survey
May 27, 2021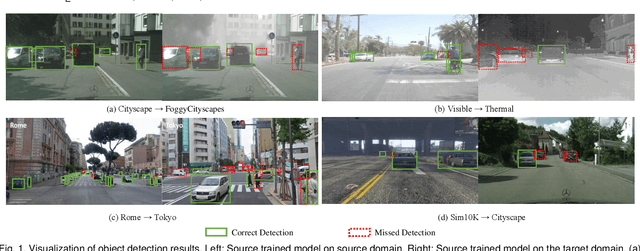
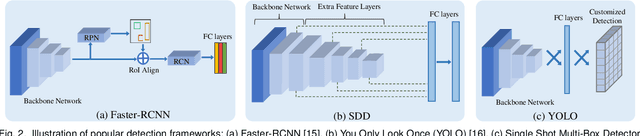
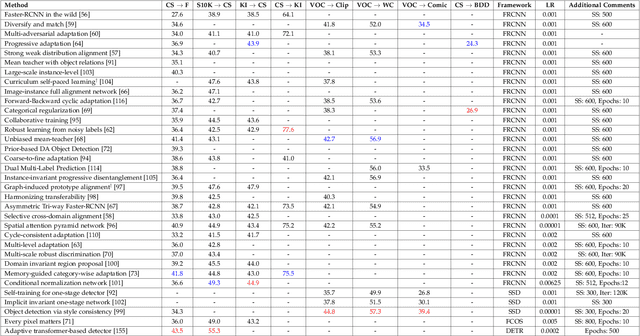
Recent advances in deep learning have led to the development of accurate and efficient models for various computer vision applications such as object classification, semantic segmentation, and object detection. However, learning highly accurate models relies on the availability of datasets with a large number of annotated images. Due to this, model performance drops drastically when evaluated on label-scarce datasets having visually distinct images. This issue is commonly referred to as covariate shift or dataset bias. Domain adaptation attempts to address this problem by leveraging domain shift characteristics from labeled data in a related domain when learning a classifier for label-scarce target dataset. There are a plethora of works to adapt object classification and semantic segmentation models to label-scarce target dataset through unsupervised domain adaptation. Considering that object detection is a fundamental task in computer vision, many recent works have recently focused on addressing the domain adaptation issue for object detection as well. In this paper, we provide a brief introduction to the domain adaptation problem for object detection and present an overview of various methods proposed to date for addressing this problem. Furthermore, we highlight strategies proposed for this problem and the associated shortcomings. Subsequently, we identify multiple aspects of the unsupervised domain adaptive detection problem that are most promising for future research in the area. We believe that this survey shall be valuable to the pattern recognition experts working in the fields of computer vision, biometrics, medical imaging, and autonomous navigation by introducing them to the problem, getting them familiar with the current status of the progress, and providing them with promising direction for future research.
Federated Learning-based Active Authentication on Mobile Devices
Apr 14, 2021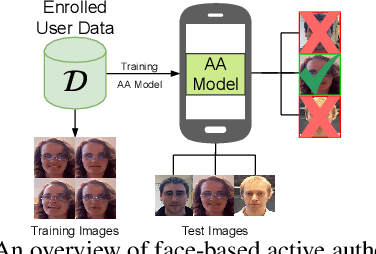
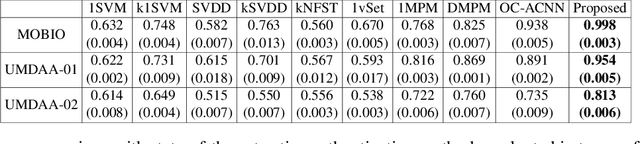
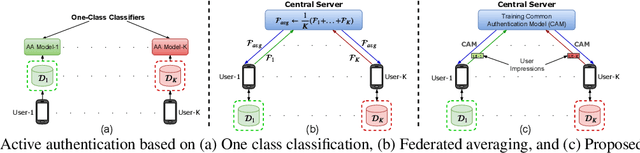
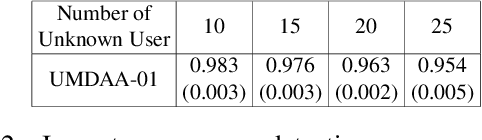
User active authentication on mobile devices aims to learn a model that can correctly recognize the enrolled user based on device sensor information. Due to lack of negative class data, it is often modeled as a one-class classification problem. In practice, mobile devices are connected to a central server, e.g, all android-based devices are connected to Google server through internet. This device-server structure can be exploited by recently proposed Federated Learning (FL) and Split Learning (SL) frameworks to perform collaborative learning over the data distributed among multiple devices. Using FL/SL frameworks, we can alleviate the lack of negative data problem by training a user authentication model over multiple user data distributed across devices. To this end, we propose a novel user active authentication training, termed as Federated Active Authentication (FAA), that utilizes the principles of FL/SL. We first show that existing FL/SL methods are suboptimal for FAA as they rely on the data to be distributed homogeneously (i.e. IID) across devices, which is not true in the case of FAA. Subsequently, we propose a novel method that is able to tackle heterogeneous/non-IID distribution of data in FAA. Specifically, we first extract feature statistics such as mean and variance corresponding to data from each user which are later combined in a central server to learn a multi-class classifier and sent back to the individual devices. We conduct extensive experiments using three active authentication benchmark datasets (MOBIO, UMDAA-01, UMDAA-02) and show that such approach performs better than state-of-the-art one-class based FAA methods and is also able to outperform traditional FL/SL methods.
MeGA-CDA: Memory Guided Attention for Category-Aware Unsupervised Domain Adaptive Object Detection
Apr 03, 2021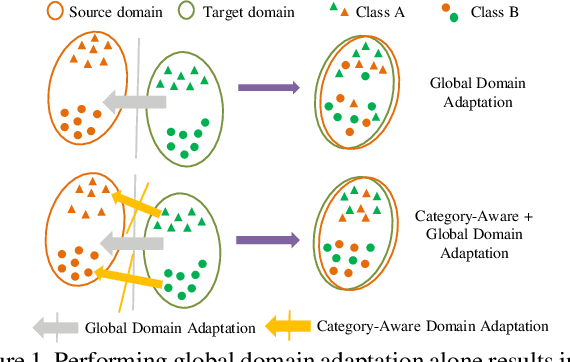
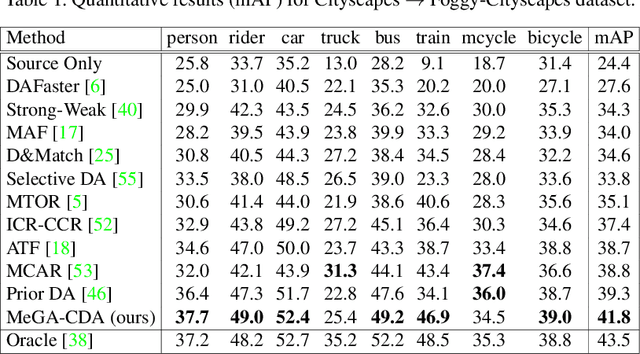
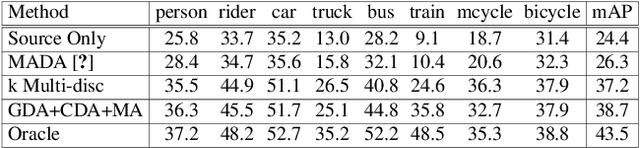
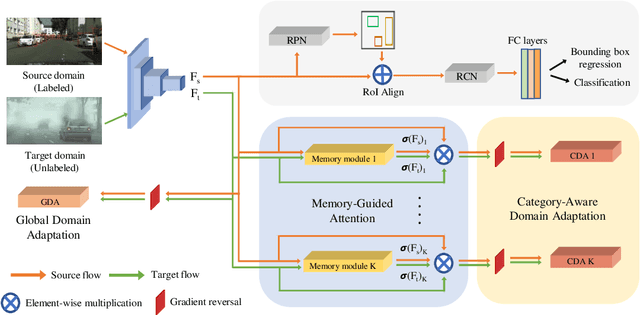
Existing approaches for unsupervised domain adaptive object detection perform feature alignment via adversarial training. While these methods achieve reasonable improvements in performance, they typically perform category-agnostic domain alignment, thereby resulting in negative transfer of features. To overcome this issue, in this work, we attempt to incorporate category information into the domain adaptation process by proposing Memory Guided Attention for Category-Aware Domain Adaptation (MeGA-CDA). The proposed method consists of employing category-wise discriminators to ensure category-aware feature alignment for learning domain-invariant discriminative features. However, since the category information is not available for the target samples, we propose to generate memory-guided category-specific attention maps which are then used to route the features appropriately to the corresponding category discriminator. The proposed method is evaluated on several benchmark datasets and is shown to outperform existing approaches.
Medical Transformer: Gated Axial-Attention for Medical Image Segmentation
Feb 21, 2021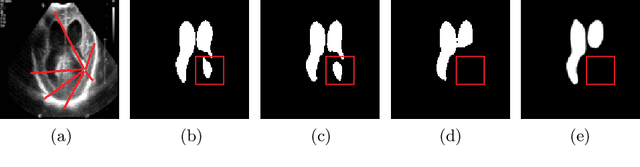
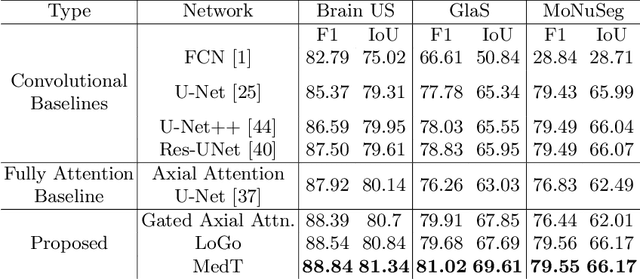
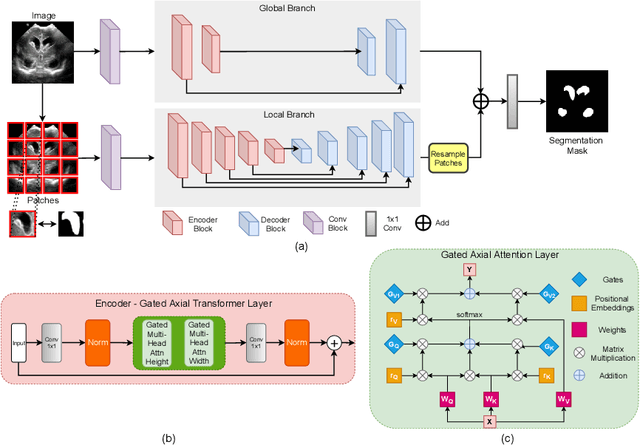

Over the past decade, Deep Convolutional Neural Networks have been widely adopted for medical image segmentation and shown to achieve adequate performance. However, due to the inherent inductive biases present in the convolutional architectures, they lack understanding of long-range dependencies in the image. Recently proposed Transformer-based architectures that leverage self-attention mechanism encode long-range dependencies and learn representations that are highly expressive. This motivates us to explore Transformer-based solutions and study the feasibility of using Transformer-based network architectures for medical image segmentation tasks. Majority of existing Transformer-based network architectures proposed for vision applications require large-scale datasets to train properly. However, compared to the datasets for vision applications, for medical imaging the number of data samples is relatively low, making it difficult to efficiently train transformers for medical applications. To this end, we propose a Gated Axial-Attention model which extends the existing architectures by introducing an additional control mechanism in the self-attention module. Furthermore, to train the model effectively on medical images, we propose a Local-Global training strategy (LoGo) which further improves the performance. Specifically, we operate on the whole image and patches to learn global and local features, respectively. The proposed Medical Transformer (MedT) is evaluated on three different medical image segmentation datasets and it is shown that it achieves better performance than the convolutional and other related transformer-based architectures. Code: https://github.com/jeya-maria-jose/Medical-Transformer
One-Class Classification: A Survey
Jan 08, 2021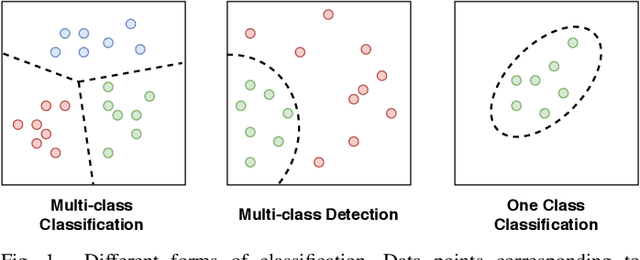
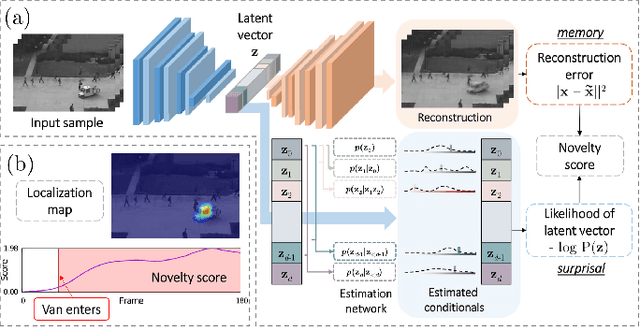
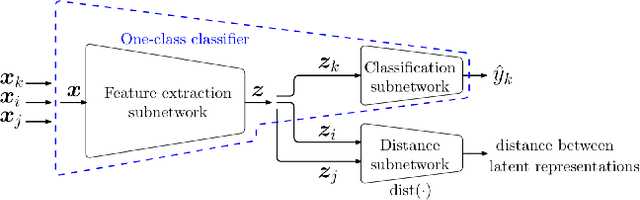
One-Class Classification (OCC) is a special case of multi-class classification, where data observed during training is from a single positive class. The goal of OCC is to learn a representation and/or a classifier that enables recognition of positively labeled queries during inference. This topic has received considerable amount of interest in the computer vision, machine learning and biometrics communities in recent years. In this article, we provide a survey of classical statistical and recent deep learning-based OCC methods for visual recognition. We discuss the merits and drawbacks of existing OCC approaches and identify promising avenues for research in this field. In addition, we present a discussion of commonly used datasets and evaluation metrics for OCC.