 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALICE: A Multifaceted Evaluation Framework of Large Audio-Language Models' In-Context Learning Ability
Mar 20, 2026While Large Audio-Language Models (LALMs) have been shown to exhibit degraded instruction-following capabilities, their ability to infer task patterns from in-context examples under audio conditioning remains unstudied. To address this gap, we present ALICE, a three-stage framework that progressively reduces textual guidance to systematically evaluate LALMs' in-context learning ability under audio conditioning. Evaluating six LALMs across four audio understanding tasks under two output constraint categories, we uncover a consistent asymmetry across all stages and LALMs: in-context demonstrations reliably improve format compliance but fail to improve, and often degrade, the core task performance. This suggests that LALMs can glean surface-level formatting patterns from demonstrations but may struggle to leverage cross-modal semantic grounding to reliably infer task objectives from audio-conditioned examples, highlighting potential limitations in current cross-modal integration.
CSGaussian: Progressive Rate-Distortion Compression and Segmentation for 3D Gaussian Splatting
Jan 19, 2026We present the first unified framework for rate-distortion-optimized compression and segmentation of 3D Gaussian Splatting (3DGS). While 3DGS has proven effective for both real-time rendering and semantic scene understanding, prior works have largely treated these tasks independently, leaving their joint consideration unexplored. Inspired by recent advances in rate-distortion-optimized 3DGS compression, this work integrates semantic learning into the compression pipeline to support decoder-side applications--such as scene editing and manipulation--that extend beyond traditional scene reconstruction and view synthesis. Our scheme features a lightweight implicit neural representation-based hyperprior, enabling efficient entropy coding of both color and semantic attributes while avoiding costly grid-based hyperprior as seen in many prior works. To facilitate compression and segmentation, we further develop compression-guided segmentation learning, consisting of quantization-aware training to enhance feature separability and a quality-aware weighting mechanism to suppress unreliable Gaussian primitives. Extensive experiments on the LERF and 3D-OVS datasets demonstrate that our approach significantly reduces transmission cost while preserving high rendering quality and strong segmentation performance.
Filter Images First, Generate Instructions Later: Pre-Instruction Data Selection for Visual Instruction Tuning
Mar 10, 2025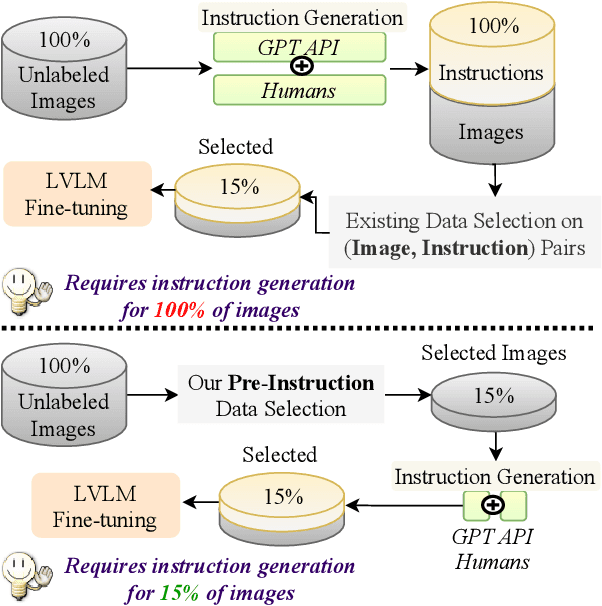



Visual instruction tuning (VIT) for large vision-language models (LVLMs) requires training on expansive datasets of image-instruction pairs, which can be costly. Recent efforts in VIT data selection aim to select a small subset of high-quality image-instruction pairs, reducing VIT runtime while maintaining performance comparable to full-scale training. However, a major challenge often overlooked is that generating instructions from unlabeled images for VIT is highly expensive. Most existing VIT datasets rely heavily on human annotations or paid services like the GPT API, which limits users with constrained resources from creating VIT datasets for custom applications. To address this, we introduce Pre-Instruction Data Selection (PreSel), a more practical data selection paradigm that directly selects the most beneficial unlabeled images and generates instructions only for the selected images. PreSel first estimates the relative importance of each vision task within VIT datasets to derive task-wise sampling budgets. It then clusters image features within each task, selecting the most representative images with the budget. This approach reduces computational overhead for both instruction generation during VIT data formation and LVLM fine-tuning. By generating instructions for only 15% of the images, PreSel achieves performance comparable to full-data VIT on the LLaVA-1.5 and Vision-Flan datasets. The link to our project page: https://bardisafa.github.io/PreSel
Towards Zero-Shot Anomaly Detection and Reasoning with Multimodal Large Language Models
Feb 11, 2025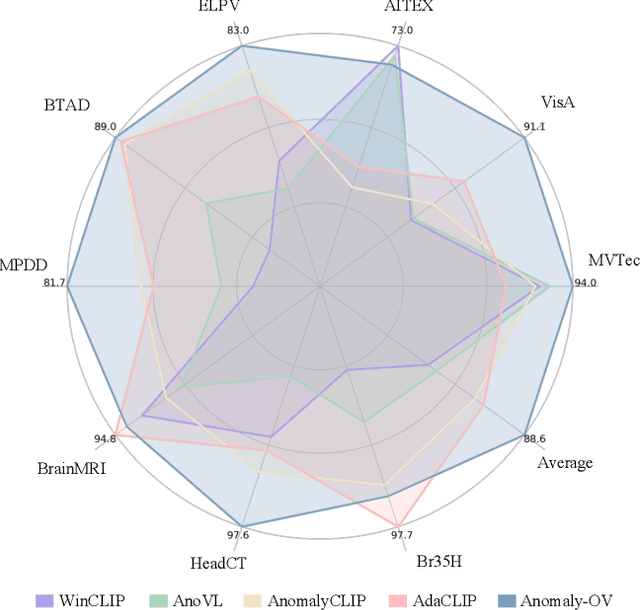
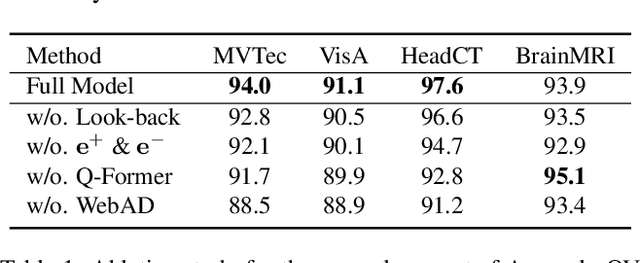

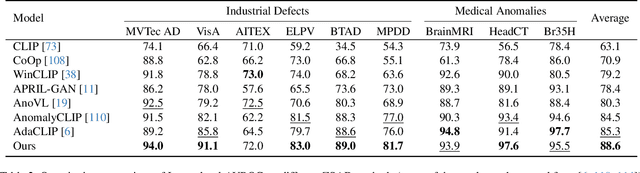
Zero-Shot Anomaly Detection (ZSAD) is an emerging AD paradigm. Unlike the traditional unsupervised AD setting that requires a large number of normal samples to train a model, ZSAD is more practical for handling data-restricted real-world scenarios. Recently, Multimodal Large Language Models (MLLMs) have shown revolutionary reasoning capabilities in various vision tasks. However, the reasoning of image abnormalities remains underexplored due to the lack of corresponding datasets and benchmarks. To facilitate research in AD & reasoning, we establish the first visual instruction tuning dataset, Anomaly-Instruct-125k, and the evaluation benchmark, VisA-D&R. Through investigation with our benchmark, we reveal that current MLLMs like GPT-4o cannot accurately detect and describe fine-grained anomalous details in images. To address this, we propose Anomaly-OneVision (Anomaly-OV), the first specialist visual assistant for ZSAD and reasoning. Inspired by human behavior in visual inspection, Anomaly-OV leverages a Look-Twice Feature Matching (LTFM) mechanism to adaptively select and emphasize abnormal visual tokens. Extensive experiments demonstrate that Anomaly-OV achieves significant improvements over advanced generalist models in both detection and reasoning. Extensions to medical and 3D AD are provided for future study. The link to our project page: https://xujiacong.github.io/Anomaly-OV/
Exocentric To Egocentric Transfer For Action Recognition: A Short Survey
Oct 27, 2024



Egocentric vision captures the scene from the point of view of the camera wearer while exocentric vision captures the overall scene context. Jointly modeling ego and exo views is crucial to developing next-generation AI agents. The community has regained interest in the field of egocentric vision. While the third-person view and first-person have been thoroughly investigated, very few works aim to study both synchronously. Exocentric videos contain many relevant signals that are transferrable to egocentric videos. In this paper, we provide a broad overview of works combining egocentric and exocentric visions.
StimuVAR: Spatiotemporal Stimuli-aware Video Affective Reasoning with Multimodal Large Language Models
Aug 31, 2024Predicting and reasoning how a video would make a human feel is crucial for developing socially intelligent systems. Although Multimodal Large Language Models (MLLMs) have shown impressive video understanding capabilities, they tend to focus more on the semantic content of videos, often overlooking emotional stimuli. Hence, most existing MLLMs fall short in estimating viewers' emotional reactions and providing plausible explanations. To address this issue, we propose StimuVAR, a spatiotemporal Stimuli-aware framework for Video Affective Reasoning (VAR) with MLLMs. StimuVAR incorporates a two-level stimuli-aware mechanism: frame-level awareness and token-level awareness. Frame-level awareness involves sampling video frames with events that are most likely to evoke viewers' emotions. Token-level awareness performs tube selection in the token space to make the MLLM concentrate on emotion-triggered spatiotemporal regions. Furthermore, we create VAR instruction data to perform affective training, steering MLLMs' reasoning strengths towards emotional focus and thereby enhancing their affective reasoning ability. To thoroughly assess the effectiveness of VAR, we provide a comprehensive evaluation protocol with extensive metrics. StimuVAR is the first MLLM-based method for viewer-centered VAR. Experiments demonstrate its superiority in understanding viewers' emotional responses to videos and providing coherent and insightful explanations.
ComNeck: Bridging Compressed Image Latents and Multimodal LLMs via Universal Transform-Neck
Jul 29, 2024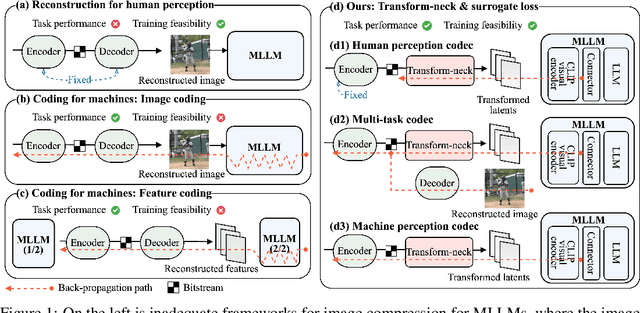

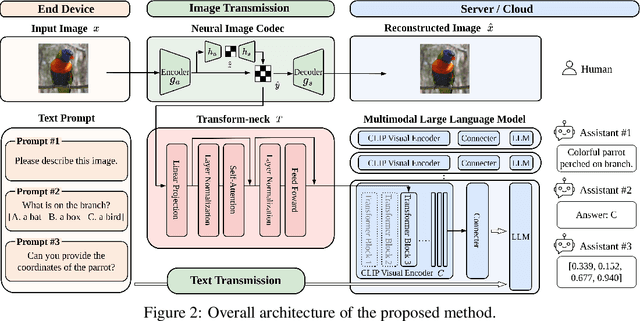
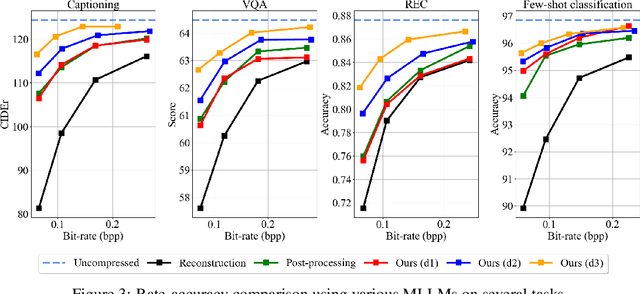
This paper presents the first-ever study of adapting compressed image latents to suit the needs of downstream vision tasks that adopt Multimodal Large Language Models (MLLMs). MLLMs have extended the success of large language models to modalities (e.g. images) beyond text, but their billion scale hinders deployment on resource-constrained end devices. While cloud-hosted MLLMs could be available, transmitting raw, uncompressed images captured by end devices to the cloud requires an efficient image compression system. To address this, we focus on emerging neural image compression and propose a novel framework with a lightweight transform-neck and a surrogate loss to adapt compressed image latents for MLLM-based vision tasks. The proposed framework is generic and applicable to multiple application scenarios, where the neural image codec can be (1) pre-trained for human perception without updating, (2) fully updated for joint human and machine perception, or (3) fully updated for only machine perception. The transform-neck trained with the surrogate loss is universal, for it can serve various downstream vision tasks enabled by a variety of MLLMs that share the same visual encoder. Our framework has the striking feature of excluding the downstream MLLMs from training the transform-neck, and potentially the neural image codec as well. This stands out from most existing coding for machine approaches that involve downstream networks in training and thus could be impractical when the networks are MLLMs. Extensive experiments on different neural image codecs and various MLLM-based vision tasks show that our method achieves great rate-accuracy performance with much less complexity, demonstrating its effectiveness.
Follow the Rules: Reasoning for Video Anomaly Detection with Large Language Models
Jul 14, 2024Video Anomaly Detection (VAD) is crucial for applications such as security surveillance and autonomous driving. However, existing VAD methods provide little rationale behind detection, hindering public trust in real-world deployments. In this paper, we approach VAD with a reasoning framework. Although Large Language Models (LLMs) have shown revolutionary reasoning ability, we find that their direct use falls short of VAD. Specifically, the implicit knowledge pre-trained in LLMs focuses on general context and thus may not apply to every specific real-world VAD scenario, leading to inflexibility and inaccuracy. To address this, we propose AnomalyRuler, a novel rule-based reasoning framework for VAD with LLMs. AnomalyRuler comprises two main stages: induction and deduction. In the induction stage, the LLM is fed with few-shot normal reference samples and then summarizes these normal patterns to induce a set of rules for detecting anomalies. The deduction stage follows the induced rules to spot anomalous frames in test videos. Additionally, we design rule aggregation, perception smoothing, and robust reasoning strategies to further enhance AnomalyRuler's robustness. AnomalyRuler is the first reasoning approach for the one-class VAD task, which requires only few-normal-shot prompting without the need for full-shot training, thereby enabling fast adaption to various VAD scenarios. Comprehensive experiments across four VAD benchmarks demonstrate AnomalyRuler's state-of-the-art detection performance and reasoning ability.
Can't make an Omelette without Breaking some Eggs: Plausible Action Anticipation using Large Video-Language Models
May 30, 2024



We introduce PlausiVL, a large video-language model for anticipating action sequences that are plausible in the real-world. While significant efforts have been made towards anticipating future actions, prior approaches do not take into account the aspect of plausibility in an action sequence. To address this limitation, we explore the generative capability of a large video-language model in our work and further, develop the understanding of plausibility in an action sequence by introducing two objective functions, a counterfactual-based plausible action sequence learning loss and a long-horizon action repetition loss. We utilize temporal logical constraints as well as verb-noun action pair logical constraints to create implausible/counterfactual action sequences and use them to train the model with plausible action sequence learning loss. This loss helps the model to differentiate between plausible and not plausible action sequences and also helps the model to learn implicit temporal cues crucial for the task of action anticipation. The long-horizon action repetition loss puts a higher penalty on the actions that are more prone to repetition over a longer temporal window. With this penalization, the model is able to generate diverse, plausible action sequences. We evaluate our approach on two large-scale datasets, Ego4D and EPIC-Kitchens-100, and show improvements on the task of action anticipation.
Adaptive Batch Normalization Networks for Adversarial Robustness
May 20, 2024Deep networks are vulnerable to adversarial examples. Adversarial Training (AT) has been a standard foundation of modern adversarial defense approaches due to its remarkable effectiveness. However, AT is extremely time-consuming, refraining it from wide deployment in practical applications. In this paper, we aim at a non-AT defense: How to design a defense method that gets rid of AT but is still robust against strong adversarial attacks? To answer this question, we resort to adaptive Batch Normalization (BN), inspired by the recent advances in test-time domain adaptation. We propose a novel defense accordingly, referred to as the Adaptive Batch Normalization Network (ABNN). ABNN employs a pre-trained substitute model to generate clean BN statistics and sends them to the target model. The target model is exclusively trained on clean data and learns to align the substitute model's BN statistics. Experimental results show that ABNN consistently improves adversarial robustness against both digital and physically realizable attacks on both image and video datasets. Furthermore, ABNN can achieve higher clean data performance and significantly lower training time complexity compared to AT-based approaches.