 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJOMP: Jointly-Optimized Mixed-Precision Quantization Across Neural Video Coding Frameworks and Buffering Strategies
Jun 11, 2026Variational autoencoder-based neural video coding has demonstrated impressive rate-distortion performance. However, its adoption in real-world applications remains hindered by challenges, such as prohibitively high computational complexity and limited cross-platform interoperability. These issues are often overlooked, as most neural video codecs rely on floating-point arithmetic to fully explore their rate-distortion potential. Practical deployment, however, requires integer-based implementations. Converting floating-point implementations into integer-based networks is non-trivial, since it involves quantizing inter-dependent coding components, whose sensitivity to precision may vary across codec designs. This paper introduces a Jointly-Optimized Mixed-Precision (JOMP) framework, in which both quantization parameters and bit widths are treated as learnable variables during training. This enables different codec modules to operate at varying precision levels, thereby jointly optimizing the rate-distortion-complexity trade-off. To the best of our knowledge, JOMP is the first mixed-precision quantization framework for neural video codecs. Its effectiveness is validated through a systematic investigation of quantization across different coding frameworks and temporal buffering strategies. Our study marks the first attempt to a unified understanding of the combined effects of modern coding frameworks and temporal buffering strategies, with the aim of informing future development of neural video codecs from a practicality perspective. In addition, we develop a complete integerization pipeline to achieve deterministic decoding. Overall, when applied to our best-performing model, JOMP enables end-to-end mixed-precision learning for integer neural video codecs, achieving rate-distortion performance comparable to that of the state-of-the-art DCVC-FM while reducing bit operations by 87.6%.
Seeing What Matters: Perceptual Wrapper with Common Randomness for 3D Gaussian Splatting
Jun 10, 2026While 3D Gaussian Splatting (3DGS) achieves impressive real-time rendering, it frequently struggles to synthesize high-frequency textures, a limitation heavily exacerbated in memory-constrained and rate-distortion-optimized (RDO) pipelines. To address this, we propose a versatile 2D perceptual wrapper that enhances the rendered outputs of existing 3DGS representations in a content- and view-dependent manner. Our method leverages a lightweight synthesis network conditioned on pseudo-random Gaussian noise to synthesize perceptually plausible textures. Supervised by Wasserstein Distortion, the network learns to match local feature statistics rather than strictly enforcing pixel-wise reconstruction fidelity, effectively mitigating the blurriness inherent in standard frameworks. We demonstrate the broad applicability of our plug-and-play approach across vanilla, memory-constrained, and RDO 3DGS methods. Comprehensive subjective and objective experiments confirm that our method significantly improves over existing baselines, yielding superior perceptual quality at sharply reduced file or model sizes.
CSGaussian: Progressive Rate-Distortion Compression and Segmentation for 3D Gaussian Splatting
Jan 19, 2026We present the first unified framework for rate-distortion-optimized compression and segmentation of 3D Gaussian Splatting (3DGS). While 3DGS has proven effective for both real-time rendering and semantic scene understanding, prior works have largely treated these tasks independently, leaving their joint consideration unexplored. Inspired by recent advances in rate-distortion-optimized 3DGS compression, this work integrates semantic learning into the compression pipeline to support decoder-side applications--such as scene editing and manipulation--that extend beyond traditional scene reconstruction and view synthesis. Our scheme features a lightweight implicit neural representation-based hyperprior, enabling efficient entropy coding of both color and semantic attributes while avoiding costly grid-based hyperprior as seen in many prior works. To facilitate compression and segmentation, we further develop compression-guided segmentation learning, consisting of quantization-aware training to enhance feature separability and a quality-aware weighting mechanism to suppress unreliable Gaussian primitives. Extensive experiments on the LERF and 3D-OVS datasets demonstrate that our approach significantly reduces transmission cost while preserving high rendering quality and strong segmentation performance.
MEGA-PCC: A Mamba-based Efficient Approach for Joint Geometry and Attribute Point Cloud Compression
Dec 27, 2025Joint compression of point cloud geometry and attributes is essential for efficient 3D data representation. Existing methods often rely on post-hoc recoloring procedures and manually tuned bitrate allocation between geometry and attribute bitstreams in inference, which hinders end-to-end optimization and increases system complexity. To overcome these limitations, we propose MEGA-PCC, a fully end-to-end, learning-based framework featuring two specialized models for joint compression. The main compression model employs a shared encoder that encodes both geometry and attribute information into a unified latent representation, followed by dual decoders that sequentially reconstruct geometry and then attributes. Complementing this, the Mamba-based Entropy Model (MEM) enhances entropy coding by capturing spatial and channel-wise correlations to improve probability estimation. Both models are built on the Mamba architecture to effectively model long-range dependencies and rich contextual features. By eliminating the need for recoloring and heuristic bitrate tuning, MEGA-PCC enables data-driven bitrate allocation during training and simplifies the overall pipeline. Extensive experiments demonstrate that MEGA-PCC achieves superior rate-distortion performance and runtime efficiency compared to both traditional and learning-based baselines, offering a powerful solution for AI-driven point cloud compression.
milliMamba: Specular-Aware Human Pose Estimation via Dual mmWave Radar with Multi-Frame Mamba Fusion
Dec 23, 2025



Millimeter-wave radar offers a privacy-preserving and lighting-invariant alternative to RGB sensors for Human Pose Estimation (HPE) task. However, the radar signals are often sparse due to specular reflection, making the extraction of robust features from radar signals highly challenging. To address this, we present milliMamba, a radar-based 2D human pose estimation framework that jointly models spatio-temporal dependencies across both the feature extraction and decoding stages. Specifically, given the high dimensionality of radar inputs, we adopt a Cross-View Fusion Mamba encoder to efficiently extract spatio-temporal features from longer sequences with linear complexity. A Spatio-Temporal-Cross Attention decoder then predicts joint coordinates across multiple frames. Together, this spatio-temporal modeling pipeline enables the model to leverage contextual cues from neighboring frames and joints to infer missing joints caused by specular reflections. To reinforce motion smoothness, we incorporate a velocity loss alongside the standard keypoint loss during training. Experiments on the TransHuPR and HuPR datasets demonstrate that our method achieves significant performance improvements, exceeding the baselines by 11.0 AP and 14.6 AP, respectively, while maintaining reasonable complexity. Code: https://github.com/NYCU-MAPL/milliMamba
MH-LVC: Multi-Hypothesis Temporal Prediction for Learned Conditional Residual Video Coding
Oct 14, 2025This work, termed MH-LVC, presents a multi-hypothesis temporal prediction scheme that employs long- and short-term reference frames in a conditional residual video coding framework. Recent temporal context mining approaches to conditional video coding offer superior coding performance. However, the need to store and access a large amount of implicit contextual information extracted from past decoded frames in decoding a video frame poses a challenge due to excessive memory access. Our MH-LVC overcomes this issue by storing multiple long- and short-term reference frames but limiting the number of reference frames used at a time for temporal prediction to two. Our decoded frame buffer management allows the encoder to flexibly utilize the long-term key frames to mitigate temporal cascading errors and the short-term reference frames to minimize prediction errors. Moreover, our buffering scheme enables the temporal prediction structure to be adapted to individual input videos. While this flexibility is common in traditional video codecs, it has not been fully explored for learned video codecs. Extensive experiments show that the proposed method outperforms VTM-17.0 under the low-delay B configuration in terms of PSNR-RGB across commonly used test datasets, and performs comparably to the state-of-the-art learned codecs (e.g.~DCVC-FM) while requiring less decoded frame buffer and similar decoding time.
Exploring Autoregressive Vision Foundation Models for Image Compression
Sep 05, 2025



This work presents the first attempt to repurpose vision foundation models (VFMs) as image codecs, aiming to explore their generation capability for low-rate image compression. VFMs are widely employed in both conditional and unconditional generation scenarios across diverse downstream tasks, e.g., physical AI applications. Many VFMs employ an encoder-decoder architecture similar to that of end-to-end learned image codecs and learn an autoregressive (AR) model to perform next-token prediction. To enable compression, we repurpose the AR model in VFM for entropy coding the next token based on previously coded tokens. This approach deviates from early semantic compression efforts that rely solely on conditional generation for reconstructing input images. Extensive experiments and analysis are conducted to compare VFM-based codec to current SOTA codecs optimized for distortion or perceptual quality. Notably, certain pre-trained, general-purpose VFMs demonstrate superior perceptual quality at extremely low bitrates compared to specialized learned image codecs. This finding paves the way for a promising research direction that leverages VFMs for low-rate, semantically rich image compression.
A Rate-Quality Model for Learned Video Coding
May 05, 2025

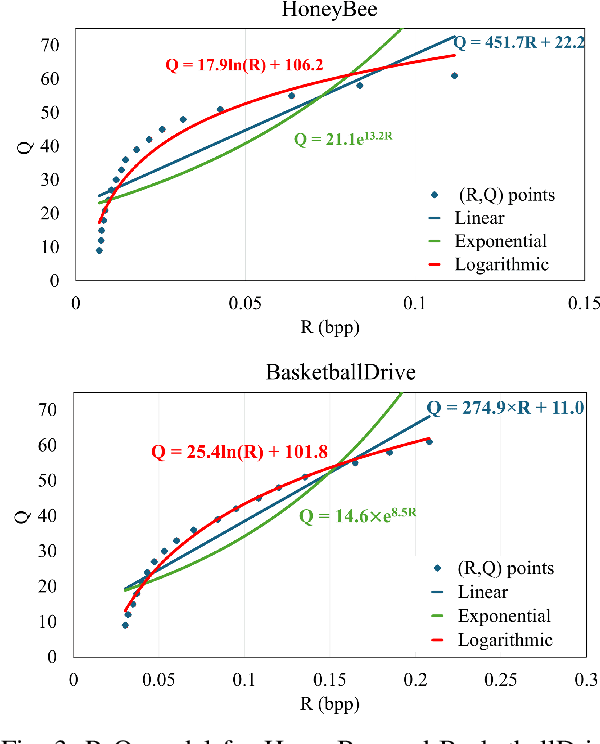

Learned video coding (LVC) has recently achieved superior coding performance. In this paper, we model the rate-quality (R-Q) relationship for learned video coding by a parametric function. We learn a neural network, termed RQNet, to characterize the relationship between the bitrate and quality level according to video content and coding context. The predicted (R,Q) results are further integrated with those from previously coded frames using the least-squares method to determine the parameters of our R-Q model on-the-fly. Compared to the conventional approaches, our method accurately estimates the R-Q relationship, enabling the online adaptation of model parameters to enhance both flexibility and precision. Experimental results show that our R-Q model achieves significantly smaller bitrate deviations than the baseline method on commonly used datasets with minimal additional complexity.
CAT-3DGS Pro: A New Benchmark for Efficient 3DGS Compression
Mar 17, 2025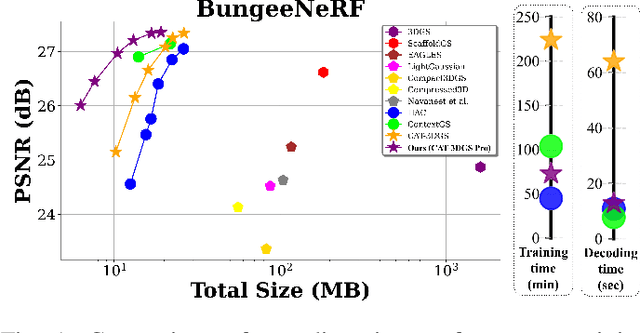



3D Gaussian Splatting (3DGS) has shown immense potential for novel view synthesis. However, achieving rate-distortion-optimized compression of 3DGS representations for transmission and/or storage applications remains a challenge. CAT-3DGS introduces a context-adaptive triplane hyperprior for end-to-end optimized compression, delivering state-of-the-art coding performance. Despite this, it requires prolonged training and decoding time. To address these limitations, we propose CAT-3DGS Pro, an enhanced version of CAT-3DGS that improves both compression performance and computational efficiency. First, we introduce a PCA-guided vector-matrix hyperprior, which replaces the triplane-based hyperprior to reduce redundant parameters. To achieve a more balanced rate-distortion trade-off and faster encoding, we propose an alternate optimization strategy (A-RDO). Additionally, we refine the sampling rate optimization method in CAT-3DGS, leading to significant improvements in rate-distortion performance. These enhancements result in a 46.6% BD-rate reduction and 3x speedup in training time on BungeeNeRF, while achieving 5x acceleration in decoding speed for the Amsterdam scene compared to CAT-3DGS.
Learning Optimal Linear Block Transform by Rate Distortion Minimization
Nov 27, 2024



Linear block transform coding remains a fundamental component of image and video compression. Although the Discrete Cosine Transform (DCT) is widely employed in all current compression standards, its sub-optimality has sparked ongoing research into discovering more efficient alternative transforms even for fields where it represents a consolidated tool. In this paper, we introduce a novel linear block transform called the Rate Distortion Learned Transform (RDLT), a data-driven transform specifically designed to minimize the rate-distortion (RD) cost when approximating residual blocks. Our approach builds on the latest end-to-end learned compression frameworks, adopting back-propagation and stochastic gradient descent for optimization. However, unlike the nonlinear transforms used in variational autoencoder (VAE)-based methods, the goal is to create a simpler yet optimal linear block transform, ensuring practical integration into existing image and video compression standards. Differently from existing data-driven methods that design transforms based on sample covariance matrices, such as the Karhunen-Lo\`eve Transform (KLT), the proposed RDLT is directly optimized from an RD perspective. Experimental results show that this transform significantly outperforms the DCT or other existing data-driven transforms. Additionally, it is shown that when simulating the integration of our RDLT into a VVC-like image compression framework, the proposed transform brings substantial improvements. All the code used in our experiments has been made publicly available at [1].