 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGA-PCC: A Mamba-based Efficient Approach for Joint Geometry and Attribute Point Cloud Compression
Dec 27, 2025Joint compression of point cloud geometry and attributes is essential for efficient 3D data representation. Existing methods often rely on post-hoc recoloring procedures and manually tuned bitrate allocation between geometry and attribute bitstreams in inference, which hinders end-to-end optimization and increases system complexity. To overcome these limitations, we propose MEGA-PCC, a fully end-to-end, learning-based framework featuring two specialized models for joint compression. The main compression model employs a shared encoder that encodes both geometry and attribute information into a unified latent representation, followed by dual decoders that sequentially reconstruct geometry and then attributes. Complementing this, the Mamba-based Entropy Model (MEM) enhances entropy coding by capturing spatial and channel-wise correlations to improve probability estimation. Both models are built on the Mamba architecture to effectively model long-range dependencies and rich contextual features. By eliminating the need for recoloring and heuristic bitrate tuning, MEGA-PCC enables data-driven bitrate allocation during training and simplifies the overall pipeline. Extensive experiments demonstrate that MEGA-PCC achieves superior rate-distortion performance and runtime efficiency compared to both traditional and learning-based baselines, offering a powerful solution for AI-driven point cloud compression.
CAT-3DGS Pro: A New Benchmark for Efficient 3DGS Compression
Mar 17, 2025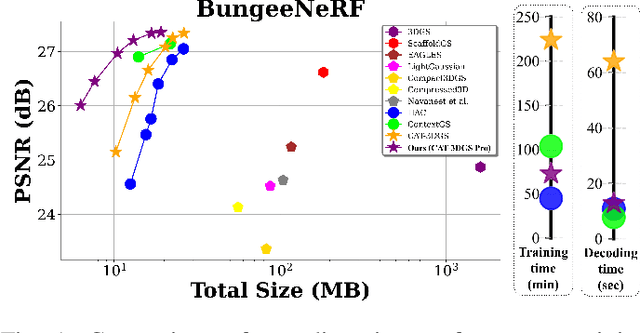



3D Gaussian Splatting (3DGS) has shown immense potential for novel view synthesis. However, achieving rate-distortion-optimized compression of 3DGS representations for transmission and/or storage applications remains a challenge. CAT-3DGS introduces a context-adaptive triplane hyperprior for end-to-end optimized compression, delivering state-of-the-art coding performance. Despite this, it requires prolonged training and decoding time. To address these limitations, we propose CAT-3DGS Pro, an enhanced version of CAT-3DGS that improves both compression performance and computational efficiency. First, we introduce a PCA-guided vector-matrix hyperprior, which replaces the triplane-based hyperprior to reduce redundant parameters. To achieve a more balanced rate-distortion trade-off and faster encoding, we propose an alternate optimization strategy (A-RDO). Additionally, we refine the sampling rate optimization method in CAT-3DGS, leading to significant improvements in rate-distortion performance. These enhancements result in a 46.6% BD-rate reduction and 3x speedup in training time on BungeeNeRF, while achieving 5x acceleration in decoding speed for the Amsterdam scene compared to CAT-3DGS.