 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMH-LVC: Multi-Hypothesis Temporal Prediction for Learned Conditional Residual Video Coding
Oct 14, 2025This work, termed MH-LVC, presents a multi-hypothesis temporal prediction scheme that employs long- and short-term reference frames in a conditional residual video coding framework. Recent temporal context mining approaches to conditional video coding offer superior coding performance. However, the need to store and access a large amount of implicit contextual information extracted from past decoded frames in decoding a video frame poses a challenge due to excessive memory access. Our MH-LVC overcomes this issue by storing multiple long- and short-term reference frames but limiting the number of reference frames used at a time for temporal prediction to two. Our decoded frame buffer management allows the encoder to flexibly utilize the long-term key frames to mitigate temporal cascading errors and the short-term reference frames to minimize prediction errors. Moreover, our buffering scheme enables the temporal prediction structure to be adapted to individual input videos. While this flexibility is common in traditional video codecs, it has not been fully explored for learned video codecs. Extensive experiments show that the proposed method outperforms VTM-17.0 under the low-delay B configuration in terms of PSNR-RGB across commonly used test datasets, and performs comparably to the state-of-the-art learned codecs (e.g.~DCVC-FM) while requiring less decoded frame buffer and similar decoding time.
Fast-OMRA: Fast Online Motion Resolution Adaptation for Neural B-Frame Coding
Oct 29, 2024Most learned B-frame codecs with hierarchical temporal prediction suffer from the domain shift issue caused by the discrepancy in the Group-of-Pictures (GOP) size used for training and test. As such, the motion estimation network may fail to predict large motion properly. One effective strategy to mitigate this domain shift issue is to downsample video frames for motion estimation. However, finding the optimal downsampling factor involves a time-consuming rate-distortion optimization process. This work introduces lightweight classifiers to determine the downsampling factor. To strike a good rate-distortion-complexity trade-off, our classifiers observe simple state signals, including only the coding and reference frames, to predict the best downsampling factor. We present two variants that adopt binary and multi-class classifiers, respectively. The binary classifier adopts the Focal Loss for training, classifying between motion estimation at high and low resolutions. Our multi-class classifier is trained with novel soft labels incorporating the knowledge of the rate-distortion costs of different downsampling factors. Both variants operate as add-on modules without the need to re-train the B-frame codec. Experimental results confirm that they achieve comparable coding performance to the brute-force search methods while greatly reducing computational complexity.
On the Rate-Distortion-Complexity Trade-offs of Neural Video Coding
Oct 04, 2024This paper aims to delve into the rate-distortion-complexity trade-offs of modern neural video coding. Recent years have witnessed much research effort being focused on exploring the full potential of neural video coding. Conditional autoencoders have emerged as the mainstream approach to efficient neural video coding. The central theme of conditional autoencoders is to leverage both spatial and temporal information for better conditional coding. However, a recent study indicates that conditional coding may suffer from information bottlenecks, potentially performing worse than traditional residual coding. To address this issue, recent conditional coding methods incorporate a large number of high-resolution features as the condition signal, leading to a considerable increase in the number of multiply-accumulate operations, memory footprint, and model size. Taking DCVC as the common code base, we investigate how the newly proposed conditional residual coding, an emerging new school of thought, and its variants may strike a better balance among rate, distortion, and complexity.
Transformer-based Learned Image Compression for Joint Decoding and Denoising
Feb 20, 2024



This work introduces a Transformer-based image compression system. It has the flexibility to switch between the standard image reconstruction and the denoising reconstruction from a single compressed bitstream. Instead of training separate decoders for these tasks, we incorporate two add-on modules to adapt a pre-trained image decoder from performing the standard image reconstruction to joint decoding and denoising. Our scheme adopts a two-pronged approach. It features a latent refinement module to refine the latent representation of a noisy input image for reconstructing a noise-free image. Additionally, it incorporates an instance-specific prompt generator that adapts the decoding process to improve on the latent refinement. Experimental results show that our method achieves a similar level of denoising quality to training a separate decoder for joint decoding and denoising at the expense of only a modest increase in the decoder's model size and computational complexity.
Never Forget: Balancing Exploration and Exploitation via Learning Optical Flow
Jan 24, 2019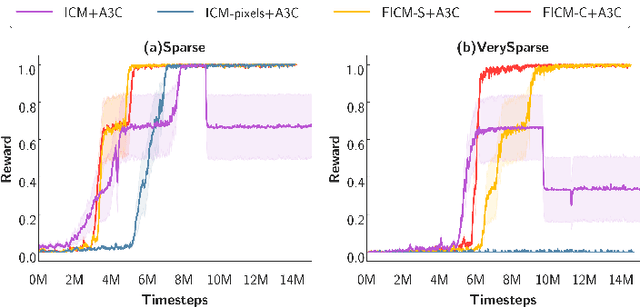

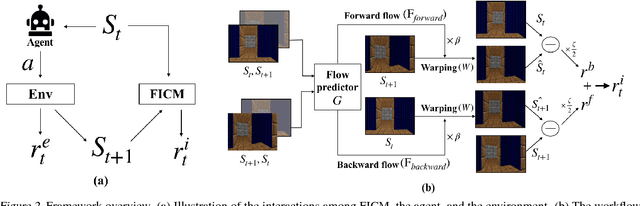
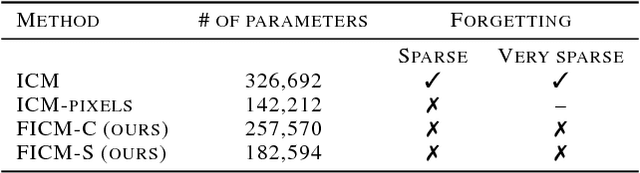
Exploration bonus derived from the novelty of the states in an environment has become a popular approach to motivate exploration for deep reinforcement learning agents in the past few years. Recent methods such as curiosity-driven exploration usually estimate the novelty of new observations by the prediction errors of their system dynamics models. Due to the capacity limitation of the models and difficulty of performing next-frame prediction, however, these methods typically fail to balance between exploration and exploitation in high-dimensional observation tasks, resulting in the agents forgetting the visited paths and exploring those states repeatedly. Such inefficient exploration behavior causes significant performance drops, especially in large environments with sparse reward signals. In this paper, we propose to introduce the concept of optical flow estimation from the field of computer vision to deal with the above issue. We propose to employ optical flow estimation errors to examine the novelty of new observations, such that agents are able to memorize and understand the visited states in a more comprehensive fashion. We compare our method against the previous approaches in a number of experimental experiments. Our results indicate that the proposed method appears to deliver superior and long-lasting performance than the previous methods. We further provide a set of comprehensive ablative analysis of the proposed method, and investigate the impact of optical flow estimation on the learning curves of the DRL agents.
Visual Relationship Prediction via Label Clustering and Incorporation of Depth Information
Sep 09, 2018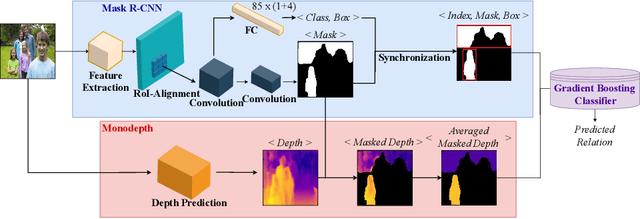
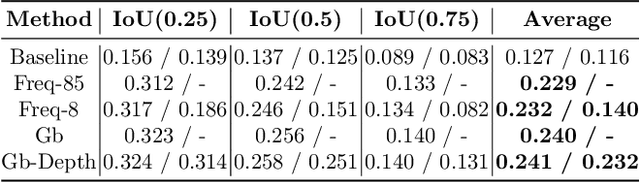
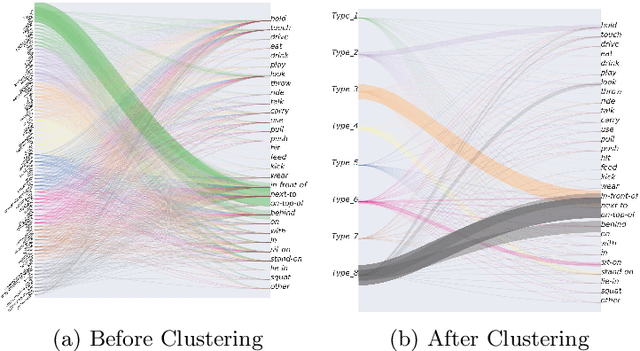
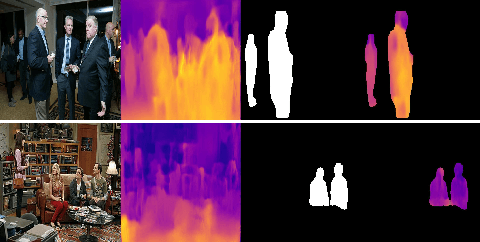
In this paper, we investigate the use of an unsupervised label clustering technique and demonstrate that it enables substantial improvements in visual relationship prediction accuracy on the Person in Context (PIC) dataset. We propose to group object labels with similar patterns of relationship distribution in the dataset into fewer categories. Label clustering not only mitigates both the large classification space and class imbalance issues, but also potentially increases data samples for each clustered category. We further propose to incorporate depth information as an additional feature into the instance segmentation model. The additional depth prediction path supplements the relationship prediction model in a way that bounding boxes or segmentation masks are unable to deliver. We have rigorously evaluated the proposed techniques and performed various ablation analysis to validate the benefits of them.