 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Masked and Unmasked: Discrete Diffusion Models via Partial Masking
May 24, 2025Masked diffusion models (MDM) are powerful generative models for discrete data that generate samples by progressively unmasking tokens in a sequence. Each token can take one of two states: masked or unmasked. We observe that token sequences often remain unchanged between consecutive sampling steps; consequently, the model repeatedly processes identical inputs, leading to redundant computation. To address this inefficiency, we propose the Partial masking scheme (Prime), which augments MDM by allowing tokens to take intermediate states interpolated between the masked and unmasked states. This design enables the model to make predictions based on partially observed token information, and facilitates a fine-grained denoising process. We derive a variational training objective and introduce a simple architectural design to accommodate intermediate-state inputs. Our method demonstrates superior performance across a diverse set of generative modeling tasks. On text data, it achieves a perplexity of 15.36 on OpenWebText, outperforming previous MDM (21.52), autoregressive models (17.54), and their hybrid variants (17.58), without relying on an autoregressive formulation. On image data, it attains competitive FID scores of 3.26 on CIFAR-10 and 6.98 on ImageNet-32, comparable to leading continuous generative models.
HoliSDiP: Image Super-Resolution via Holistic Semantics and Diffusion Prior
Nov 27, 2024Text-to-image diffusion models have emerged as powerful priors for real-world image super-resolution (Real-ISR). However, existing methods may produce unintended results due to noisy text prompts and their lack of spatial information. In this paper, we present HoliSDiP, a framework that leverages semantic segmentation to provide both precise textual and spatial guidance for diffusion-based Real-ISR. Our method employs semantic labels as concise text prompts while introducing dense semantic guidance through segmentation masks and our proposed Segmentation-CLIP Map. Extensive experiments demonstrate that HoliSDiP achieves significant improvement in image quality across various Real-ISR scenarios through reduced prompt noise and enhanced spatial control.
Fine-Grained Alignment in Vision-and-Language Navigation through Bayesian Optimization
Nov 22, 2024



This paper addresses the challenge of fine-grained alignment in Vision-and-Language Navigation (VLN) tasks, where robots navigate realistic 3D environments based on natural language instructions. Current approaches use contrastive learning to align language with visual trajectory sequences. Nevertheless, they encounter difficulties with fine-grained vision negatives. To enhance cross-modal embeddings, we introduce a novel Bayesian Optimization-based adversarial optimization framework for creating fine-grained contrastive vision samples. To validate the proposed methodology, we conduct a series of experiments to assess the effectiveness of the enriched embeddings on fine-grained vision negatives. We conduct experiments on two common VLN benchmarks R2R and REVERIE, experiments on the them demonstrate that these embeddings benefit navigation, and can lead to a promising performance enhancement. Our source code and trained models are available at: https://anonymous.4open.science/r/FGVLN.
Retraining-Free Merging of Sparse Mixture-of-Experts via Hierarchical Clustering
Oct 11, 2024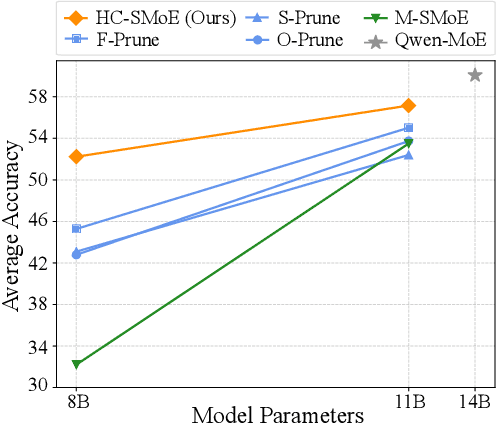

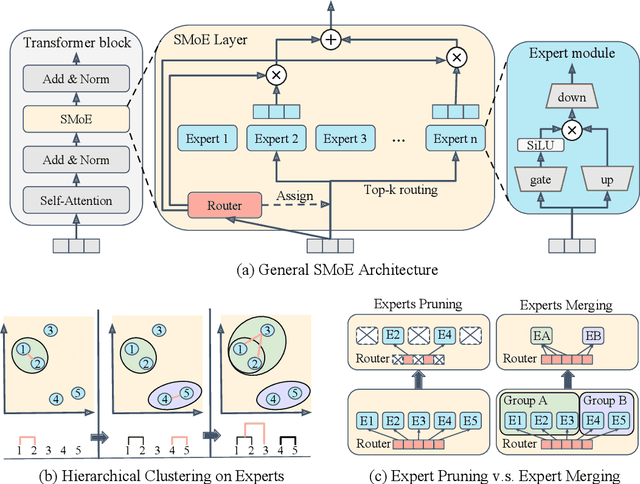
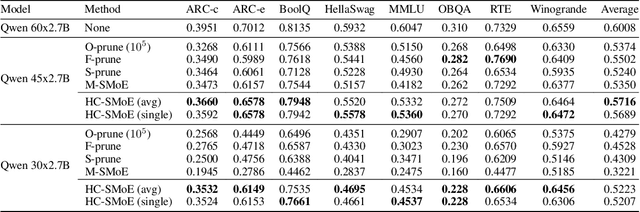
Sparse Mixture-of-Experts (SMoE) models represent a significant breakthrough in large language model development. These models enable performance improvements without a proportional increase in inference costs. By selectively activating a small set of parameters during task execution, SMoEs enhance model capacity. However, their deployment remains challenging due to the substantial memory footprint required to accommodate the growing number of experts. This constraint renders them less feasible in environments with limited hardware resources. To address this challenge, we propose Hierarchical Clustering for Sparsely activated Mixture of Experts (HC-SMoE), a task-agnostic expert merging framework that reduces SMoE model parameters without retraining. Unlike previous methods, HC-SMoE employs hierarchical clustering based on expert outputs. This approach ensures that the merging process remains unaffected by routing decisions. The output-based clustering strategy captures functional similarities between experts, offering an adaptable solution for models with numerous experts. We validate our approach through extensive experiments on eight zero-shot language tasks and demonstrate its effectiveness in large-scale SMoE models such as Qwen and Mixtral. Our comprehensive results demonstrate that HC-SMoE consistently achieves strong performance, which highlights its potential for real-world deployment.
Precise Pick-and-Place using Score-Based Diffusion Networks
Sep 15, 2024



In this paper, we propose a novel coarse-to-fine continuous pose diffusion method to enhance the precision of pick-and-place operations within robotic manipulation tasks. Leveraging the capabilities of diffusion networks, we facilitate the accurate perception of object poses. This accurate perception enhances both pick-and-place success rates and overall manipulation precision. Our methodology utilizes a top-down RGB image projected from an RGB-D camera and adopts a coarse-to-fine architecture. This architecture enables efficient learning of coarse and fine models. A distinguishing feature of our approach is its focus on continuous pose estimation, which enables more precise object manipulation, particularly concerning rotational angles. In addition, we employ pose and color augmentation techniques to enable effective training with limited data. Through extensive experiments in simulated and real-world scenarios, as well as an ablation study, we comprehensively evaluate our proposed methodology. Taken together, the findings validate its effectiveness in achieving high-precision pick-and-place tasks.
Reprojection Errors as Prompts for Efficient Scene Coordinate Regression
Sep 06, 2024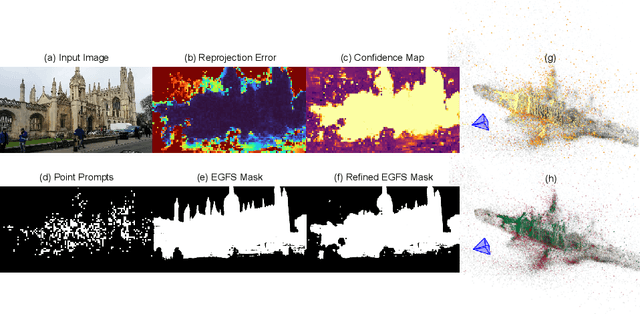
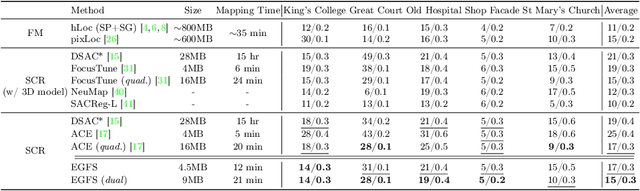
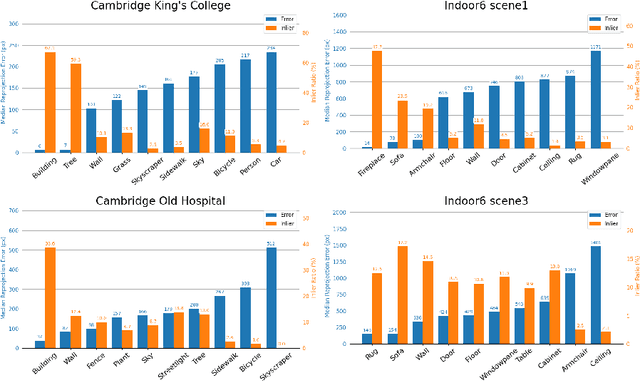
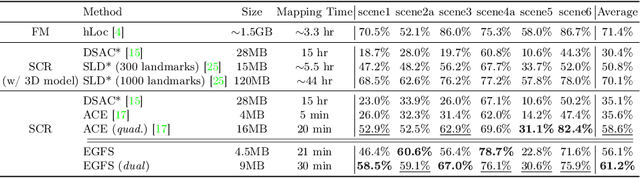
Scene coordinate regression (SCR) methods have emerged as a promising area of research due to their potential for accurate visual localization. However, many existing SCR approaches train on samples from all image regions, including dynamic objects and texture-less areas. Utilizing these areas for optimization during training can potentially hamper the overall performance and efficiency of the model. In this study, we first perform an in-depth analysis to validate the adverse impacts of these areas. Drawing inspiration from our analysis, we then introduce an error-guided feature selection (EGFS) mechanism, in tandem with the use of the Segment Anything Model (SAM). This mechanism seeds low reprojection areas as prompts and expands them into error-guided masks, and then utilizes these masks to sample points and filter out problematic areas in an iterative manner. The experiments demonstrate that our method outperforms existing SCR approaches that do not rely on 3D information on the Cambridge Landmarks and Indoor6 datasets.
Maximum Entropy Reinforcement Learning via Energy-Based Normalizing Flow
May 22, 2024
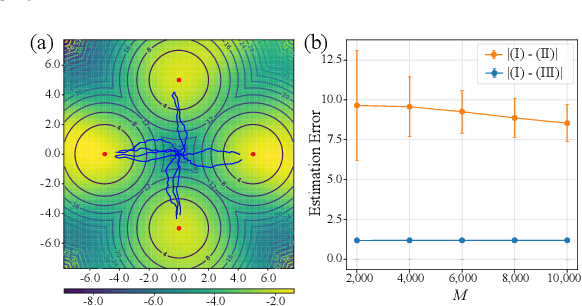
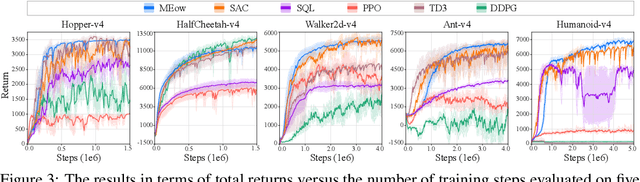
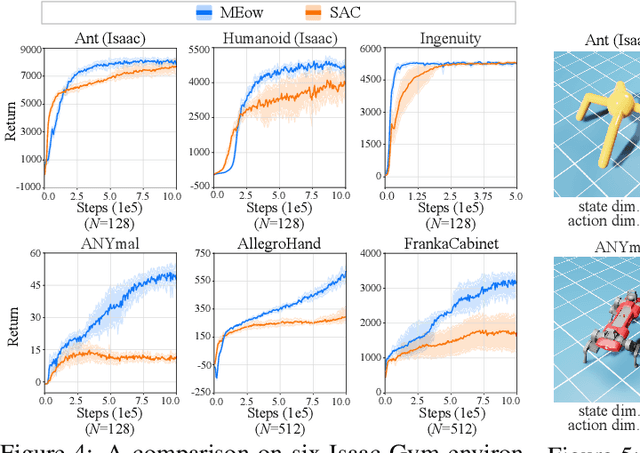
Existing Maximum-Entropy (MaxEnt) Reinforcement Learning (RL) methods for continuous action spaces are typically formulated based on actor-critic frameworks and optimized through alternating steps of policy evaluation and policy improvement. In the policy evaluation steps, the critic is updated to capture the soft Q-function. In the policy improvement steps, the actor is adjusted in accordance with the updated soft Q-function. In this paper, we introduce a new MaxEnt RL framework modeled using Energy-Based Normalizing Flows (EBFlow). This framework integrates the policy evaluation steps and the policy improvement steps, resulting in a single objective training process. Our method enables the calculation of the soft value function used in the policy evaluation target without Monte Carlo approximation. Moreover, this design supports the modeling of multi-modal action distributions while facilitating efficient action sampling. To evaluate the performance of our method, we conducted experiments on the MuJoCo benchmark suite and a number of high-dimensional robotic tasks simulated by Omniverse Isaac Gym. The evaluation results demonstrate that our method achieves superior performance compared to widely-adopted representative baselines.
AdaIR: Exploiting Underlying Similarities of Image Restoration Tasks with Adapters
Apr 17, 2024Existing image restoration approaches typically employ extensive networks specifically trained for designated degradations. Despite being effective, such methods inevitably entail considerable storage costs and computational overheads due to the reliance on task-specific networks. In this work, we go beyond this well-established framework and exploit the inherent commonalities among image restoration tasks. The primary objective is to identify components that are shareable across restoration tasks and augment the shared components with modules specifically trained for individual tasks. Towards this goal, we propose AdaIR, a novel framework that enables low storage cost and efficient training without sacrificing performance. Specifically, a generic restoration network is first constructed through self-supervised pre-training using synthetic degradations. Subsequent to the pre-training phase, adapters are trained to adapt the pre-trained network to specific degradations. AdaIR requires solely the training of lightweight, task-specific modules, ensuring a more efficient storage and training regimen. We have conducted extensive experiments to validate the effectiveness of AdaIR and analyze the influence of the pre-training strategy on discovering shareable components. Extensive experimental results show that AdaIR achieves outstanding results on multi-task restoration while utilizing significantly fewer parameters (1.9 MB) and less training time (7 hours) for each restoration task. The source codes and trained models will be released.
Boosting Flow-based Generative Super-Resolution Models via Learned Prior
Mar 30, 2024



Flow-based super-resolution (SR) models have demonstrated astonishing capabilities in generating high-quality images. However, these methods encounter several challenges during image generation, such as grid artifacts, exploding inverses, and suboptimal results due to a fixed sampling temperature. To overcome these issues, this work introduces a conditional learned prior to the inference phase of a flow-based SR model. This prior is a latent code predicted by our proposed latent module conditioned on the low-resolution image, which is then transformed by the flow model into an SR image. Our framework is designed to seamlessly integrate with any contemporary flow-based SR model without modifying its architecture or pre-trained weights. We evaluate the effectiveness of our proposed framework through extensive experiments and ablation analyses. The proposed framework successfully addresses all the inherent issues in flow-based SR models and enhances their performance in various SR scenarios. Our code is available at: https://github.com/liyuantsao/FlowSR-LP
DriveEnv-NeRF: Exploration of A NeRF-Based Autonomous Driving Environment for Real-World Performance Validation
Mar 23, 2024In this study, we introduce the DriveEnv-NeRF framework, which leverages Neural Radiance Fields (NeRF) to enable the validation and faithful forecasting of the efficacy of autonomous driving agents in a targeted real-world scene. Standard simulator-based rendering often fails to accurately reflect real-world performance due to the sim-to-real gap, which represents the disparity between virtual simulations and real-world conditions. To mitigate this gap, we propose a workflow for building a high-fidelity simulation environment of the targeted real-world scene using NeRF. This approach is capable of rendering realistic images from novel viewpoints and constructing 3D meshes for emulating collisions. The validation of these capabilities through the comparison of success rates in both simulated and real environments demonstrates the benefits of using DriveEnv-NeRF as a real-world performance indicator. Furthermore, the DriveEnv-NeRF framework can serve as a training environment for autonomous driving agents under various lighting conditions. This approach enhances the robustness of the agents and reduces performance degradation when deployed to the target real scene, compared to agents fully trained using the standard simulator rendering pipeline.