 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandscape-Awareness for Geometric View Diffusion Model
May 19, 2026Accurate camera viewpoint estimation under sparse-view conditions remains challenging, particularly in two-view scenarios. Recent approaches leverage diffusion models such as Zero123 to synthesize novel views conditioned on relative viewpoint, showing promising results when repurposed for viewpoint estimation via optimization with MSE loss. However, existing methods often suffer from nonconvex loss landscape with numerous local minima, making them sensitive to initialization and reliant on naive multistart strategies. We analyze these optimization challenges and visualize failure cases, showing that geometric ambiguities, such as symmetry and self-similarity, can mislead gradient-based updates toward incorrect viewpoints. To address these limitations, we propose a score-based method that reshapes the optimization landscape to guide updates toward the ground-truth viewpoint, followed by a refinement stage using a viewpoint-conditioned diffusion model. Experiments show that our method improves convergence, reduces reliance on brute-force sampling, and achieves competitive accuracy with higher sample-efficiency.
Precise Pick-and-Place using Score-Based Diffusion Networks
Sep 15, 2024



In this paper, we propose a novel coarse-to-fine continuous pose diffusion method to enhance the precision of pick-and-place operations within robotic manipulation tasks. Leveraging the capabilities of diffusion networks, we facilitate the accurate perception of object poses. This accurate perception enhances both pick-and-place success rates and overall manipulation precision. Our methodology utilizes a top-down RGB image projected from an RGB-D camera and adopts a coarse-to-fine architecture. This architecture enables efficient learning of coarse and fine models. A distinguishing feature of our approach is its focus on continuous pose estimation, which enables more precise object manipulation, particularly concerning rotational angles. In addition, we employ pose and color augmentation techniques to enable effective training with limited data. Through extensive experiments in simulated and real-world scenarios, as well as an ablation study, we comprehensively evaluate our proposed methodology. Taken together, the findings validate its effectiveness in achieving high-precision pick-and-place tasks.
Confronting Ambiguity in 6D Object Pose Estimation via Score-Based Diffusion on SE(3)
May 25, 2023



Addressing accuracy limitations and pose ambiguity in 6D object pose estimation from single RGB images presents a significant challenge, particularly due to object symmetries or occlusions. In response, we introduce a novel score-based diffusion method applied to the $SE(3)$ group, marking the first application of diffusion models to $SE(3)$ within the image domain, specifically tailored for pose estimation tasks. Extensive evaluations demonstrate the method's efficacy in handling pose ambiguity, mitigating perspective-induced ambiguity, and showcasing the robustness of our surrogate Stein score formulation on $SE(3)$. This formulation not only improves the convergence of Langevin dynamics but also enhances computational efficiency. Thus, we pioneer a promising strategy for 6D object pose estimation.
Vision based Virtual Guidance for Navigation
Mar 05, 2023



This paper explores the impact of virtual guidance on mid-level representation-based navigation, where an agent performs navigation tasks based solely on visual observations. Instead of providing distance measures or numerical directions to guide the agent, which may be difficult for it to interpret visually, the paper investigates the potential of different forms of virtual guidance schemes on navigation performance. Three schemes of virtual guidance signals are explored: virtual navigation path, virtual waypoints, and a combination of both. The experiments were conducted using a virtual city built with the Unity engine to train the agents while avoiding obstacles. The results show that virtual guidance provides the agent with more meaningful navigation information and achieves better performance in terms of path completion rates and navigation efficiency. In addition, a set of analyses were provided to investigate the failure cases and the navigated trajectories, and a pilot study was conducted for the real-world scenarios.
Investigation of Factorized Optical Flows as Mid-Level Representations
Mar 10, 2022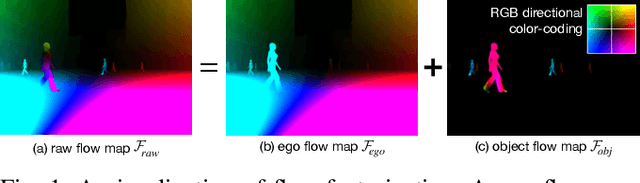
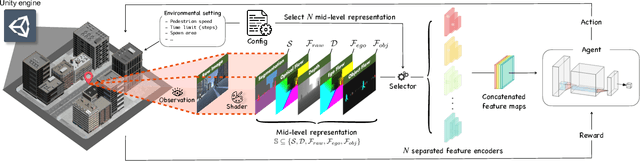
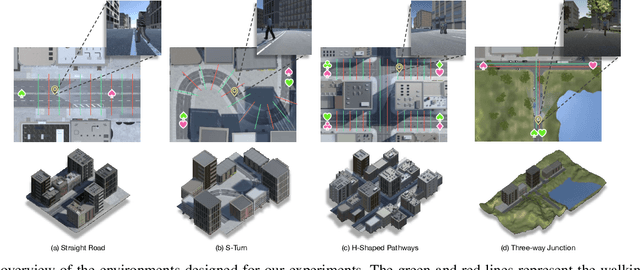
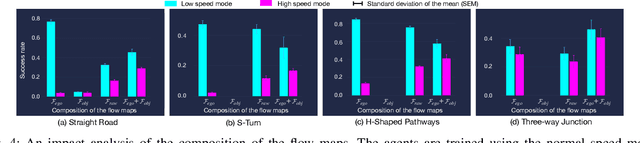
In this paper, we introduce a new concept of incorporating factorized flow maps as mid-level representations, for bridging the perception and the control modules in modular learning based robotic frameworks. To investigate the advantages of factorized flow maps and examine their interplay with the other types of mid-level representations, we further develop a configurable framework, along with four different environments that contain both static and dynamic objects, for analyzing the impacts of factorized optical flow maps on the performance of deep reinforcement learning agents. Based on this framework, we report our experimental results on various scenarios, and offer a set of analyses to justify our hypothesis. Finally, we validate flow factorization in real world scenarios.
Virtual-to-Real: Learning to Control in Visual Semantic Segmentation
Oct 28, 2018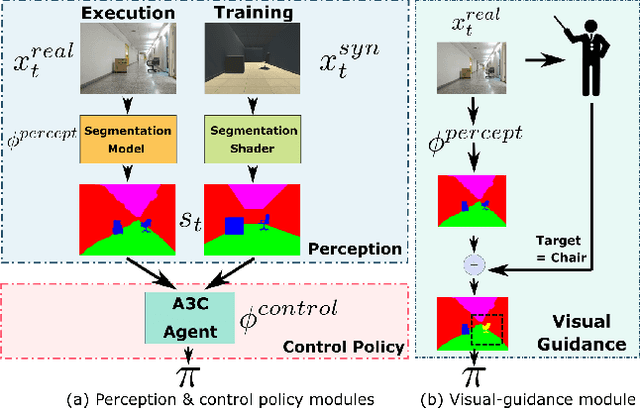



Collecting training data from the physical world is usually time-consuming and even dangerous for fragile robots, and thus, recent advances in robot learning advocate the use of simulators as the training platform. Unfortunately, the reality gap between synthetic and real visual data prohibits direct migration of the models trained in virtual worlds to the real world. This paper proposes a modular architecture for tackling the virtual-to-real problem. The proposed architecture separates the learning model into a perception module and a control policy module, and uses semantic image segmentation as the meta representation for relating these two modules. The perception module translates the perceived RGB image to semantic image segmentation. The control policy module is implemented as a deep reinforcement learning agent, which performs actions based on the translated image segmentation. Our architecture is evaluated in an obstacle avoidance task and a target following task. Experimental results show that our architecture significantly outperforms all of the baseline methods in both virtual and real environments, and demonstrates a faster learning curve than them. We also present a detailed analysis for a variety of variant configurations, and validate the transferability of our modular architecture.