 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoliSDiP: Image Super-Resolution via Holistic Semantics and Diffusion Prior
Nov 27, 2024Text-to-image diffusion models have emerged as powerful priors for real-world image super-resolution (Real-ISR). However, existing methods may produce unintended results due to noisy text prompts and their lack of spatial information. In this paper, we present HoliSDiP, a framework that leverages semantic segmentation to provide both precise textual and spatial guidance for diffusion-based Real-ISR. Our method employs semantic labels as concise text prompts while introducing dense semantic guidance through segmentation masks and our proposed Segmentation-CLIP Map. Extensive experiments demonstrate that HoliSDiP achieves significant improvement in image quality across various Real-ISR scenarios through reduced prompt noise and enhanced spatial control.
Boosting Flow-based Generative Super-Resolution Models via Learned Prior
Mar 30, 2024



Flow-based super-resolution (SR) models have demonstrated astonishing capabilities in generating high-quality images. However, these methods encounter several challenges during image generation, such as grid artifacts, exploding inverses, and suboptimal results due to a fixed sampling temperature. To overcome these issues, this work introduces a conditional learned prior to the inference phase of a flow-based SR model. This prior is a latent code predicted by our proposed latent module conditioned on the low-resolution image, which is then transformed by the flow model into an SR image. Our framework is designed to seamlessly integrate with any contemporary flow-based SR model without modifying its architecture or pre-trained weights. We evaluate the effectiveness of our proposed framework through extensive experiments and ablation analyses. The proposed framework successfully addresses all the inherent issues in flow-based SR models and enhances their performance in various SR scenarios. Our code is available at: https://github.com/liyuantsao/FlowSR-LP
Local Implicit Normalizing Flow for Arbitrary-Scale Image Super-Resolution
Mar 09, 2023



Flow-based methods have demonstrated promising results in addressing the ill-posed nature of super-resolution (SR) by learning the distribution of high-resolution (HR) images with the normalizing flow. However, these methods can only perform a predefined fixed-scale SR, limiting their potential in real-world applications. Meanwhile, arbitrary-scale SR has gained more attention and achieved great progress. Nonetheless, previous arbitrary-scale SR methods ignore the ill-posed problem and train the model with per-pixel L1 loss, leading to blurry SR outputs. In this work, we propose "Local Implicit Normalizing Flow" (LINF) as a unified solution to the above problems. LINF models the distribution of texture details under different scaling factors with normalizing flow. Thus, LINF can generate photo-realistic HR images with rich texture details in arbitrary scale factors. We evaluate LINF with extensive experiments and show that LINF achieves the state-of-the-art perceptual quality compared with prior arbitrary-scale SR methods.
ELDA: Using Edges to Have an Edge on Semantic Segmentation Based UDA
Nov 16, 2022



Many unsupervised domain adaptation (UDA) methods have been proposed to bridge the domain gap by utilizing domain invariant information. Most approaches have chosen depth as such information and achieved remarkable success. Despite their effectiveness, using depth as domain invariant information in UDA tasks may lead to multiple issues, such as excessively high extraction costs and difficulties in achieving a reliable prediction quality. As a result, we introduce Edge Learning based Domain Adaptation (ELDA), a framework which incorporates edge information into its training process to serve as a type of domain invariant information. In our experiments, we quantitatively and qualitatively demonstrate that the incorporation of edge information is indeed beneficial and effective and enables ELDA to outperform the contemporary state-of-the-art methods on two commonly adopted benchmarks for semantic segmentation based UDA tasks. In addition, we show that ELDA is able to better separate the feature distributions of different classes. We further provide an ablation analysis to justify our design decisions.
Investigation of Factorized Optical Flows as Mid-Level Representations
Mar 10, 2022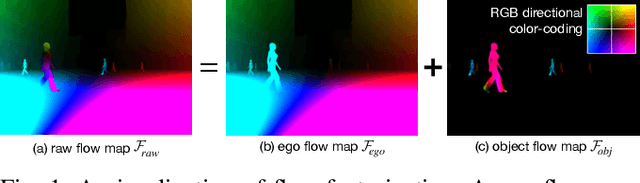
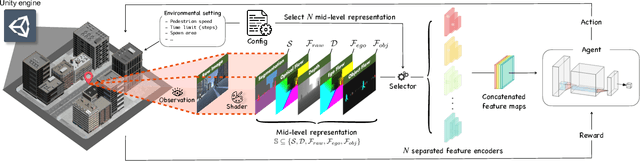
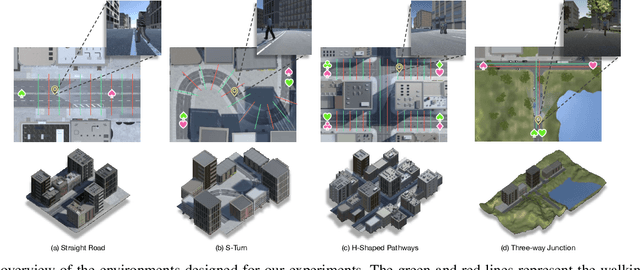
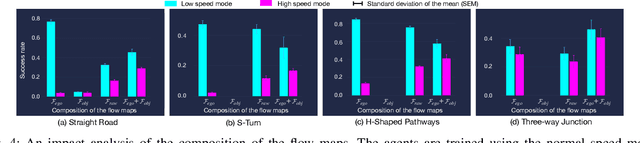
In this paper, we introduce a new concept of incorporating factorized flow maps as mid-level representations, for bridging the perception and the control modules in modular learning based robotic frameworks. To investigate the advantages of factorized flow maps and examine their interplay with the other types of mid-level representations, we further develop a configurable framework, along with four different environments that contain both static and dynamic objects, for analyzing the impacts of factorized optical flow maps on the performance of deep reinforcement learning agents. Based on this framework, we report our experimental results on various scenarios, and offer a set of analyses to justify our hypothesis. Finally, we validate flow factorization in real world scenarios.