 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoliSDiP: Image Super-Resolution via Holistic Semantics and Diffusion Prior
Nov 27, 2024Text-to-image diffusion models have emerged as powerful priors for real-world image super-resolution (Real-ISR). However, existing methods may produce unintended results due to noisy text prompts and their lack of spatial information. In this paper, we present HoliSDiP, a framework that leverages semantic segmentation to provide both precise textual and spatial guidance for diffusion-based Real-ISR. Our method employs semantic labels as concise text prompts while introducing dense semantic guidance through segmentation masks and our proposed Segmentation-CLIP Map. Extensive experiments demonstrate that HoliSDiP achieves significant improvement in image quality across various Real-ISR scenarios through reduced prompt noise and enhanced spatial control.
Toward Fairness via Maximum Mean Discrepancy Regularization on Logits Space
Feb 20, 2024Fairness has become increasingly pivotal in machine learning for high-risk applications such as machine learning in healthcare and facial recognition. However, we see the deficiency in the previous logits space constraint methods. Therefore, we propose a novel framework, Logits-MMD, that achieves the fairness condition by imposing constraints on output logits with Maximum Mean Discrepancy. Moreover, quantitative analysis and experimental results show that our framework has a better property that outperforms previous methods and achieves state-of-the-art on two facial recognition datasets and one animal dataset. Finally, we show experimental results and demonstrate that our debias approach achieves the fairness condition effectively.
Toward Fairness Through Fair Multi-Exit Framework for Dermatological Disease Diagnosis
Jul 01, 2023Fairness has become increasingly pivotal in medical image recognition. However, without mitigating bias, deploying unfair medical AI systems could harm the interests of underprivileged populations. In this paper, we observe that while features extracted from the deeper layers of neural networks generally offer higher accuracy, fairness conditions deteriorate as we extract features from deeper layers. This phenomenon motivates us to extend the concept of multi-exit frameworks. Unlike existing works mainly focusing on accuracy, our multi-exit framework is fairness-oriented; the internal classifiers are trained to be more accurate and fairer, with high extensibility to apply to most existing fairness-aware frameworks. During inference, any instance with high confidence from an internal classifier is allowed to exit early. Experimental results show that the proposed framework can improve the fairness condition over the state-of-the-art in two dermatological disease datasets.
Fair Multi-Exit Framework for Facial Attribute Classification
Jan 08, 2023



Fairness has become increasingly pivotal in facial recognition. Without bias mitigation, deploying unfair AI would harm the interest of the underprivileged population. In this paper, we observe that though the higher accuracy that features from the deeper layer of a neural networks generally offer, fairness conditions deteriorate as we extract features from deeper layers. This phenomenon motivates us to extend the concept of multi-exit framework. Unlike existing works mainly focusing on accuracy, our multi-exit framework is fairness-oriented, where the internal classifiers are trained to be more accurate and fairer. During inference, any instance with high confidence from an internal classifier is allowed to exit early. Moreover, our framework can be applied to most existing fairness-aware frameworks. Experiment results show that the proposed framework can largely improve the fairness condition over the state-of-the-art in CelebA and UTK Face datasets.
Representative Image Feature Extraction via Contrastive Learning Pretraining for Chest X-ray Report Generation
Sep 04, 2022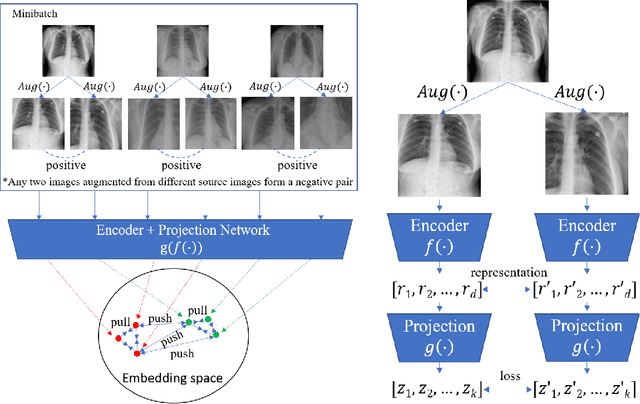
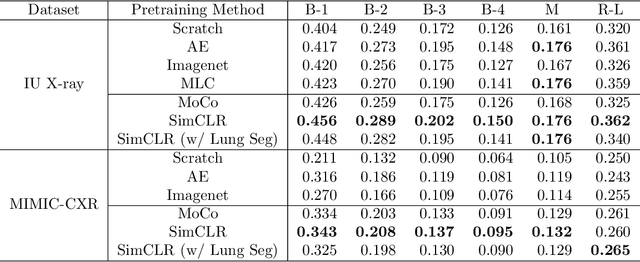

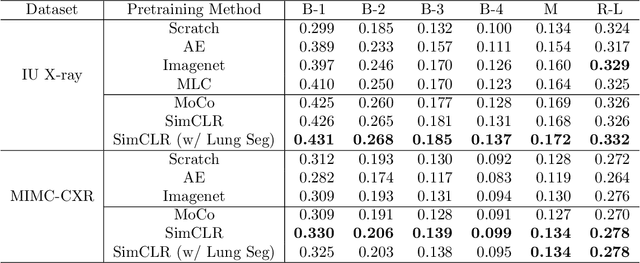
Medical report generation is a challenging task since it is time-consuming and requires expertise from experienced radiologists. The goal of medical report generation is to accurately capture and describe the image findings. Previous works pretrain their visual encoding neural networks with large datasets in different domains, which cannot learn general visual representation in the specific medical domain. In this work, we propose a medical report generation framework that uses a contrastive learning approach to pretrain the visual encoder and requires no additional meta information. In addition, we adopt lung segmentation as an augmentation method in the contrastive learning framework. This segmentation guides the network to focus on encoding the visual feature within the lung region. Experimental results show that the proposed framework improves the performance and the quality of the generated medical reports both quantitatively and qualitatively.