 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccuBench: Evaluating AI Agents on Real-World Professional Tasks via Language World Models
Apr 13, 2026AI agents are expected to perform professional work across hundreds of occupational domains (from emergency department triage to nuclear reactor safety monitoring to customs import processing), yet existing benchmarks can only evaluate agents in the few domains where public environments exist. We introduce OccuBench, a benchmark covering 100 real-world professional task scenarios across 10 industry categories and 65 specialized domains, enabled by Language World Models (LWMs) that simulate domain-specific environments through LLM-driven tool response generation. Our multi-agent synthesis pipeline automatically produces evaluation instances with guaranteed solvability, calibrated difficulty, and document-grounded diversity. OccuBench evaluates agents along two complementary dimensions: task completion across professional domains and environmental robustness under controlled fault injection (explicit errors, implicit data degradation, and mixed faults). We evaluate 15 frontier models across 8 model families and find that: (1) no single model dominates all industries, as each has a distinct occupational capability profile; (2) implicit faults (truncated data, missing fields) are harder than both explicit errors (timeouts, 500s) and mixed faults, because they lack overt error signals and require the agent to independently detect data degradation; (3) larger models, newer generations, and higher reasoning effort consistently improve performance. GPT-5.2 improves by 27.5 points from minimal to maximum reasoning effort; and (4) strong agents are not necessarily strong environment simulators. Simulator quality is critical for LWM-based evaluation reliability. OccuBench provides the first systematic cross-industry evaluation of AI agents on professional occupational tasks.
OrgAgent: Organize Your Multi-Agent System like a Company
Apr 01, 2026While large language model-based multi-agent systems have shown strong potential for complex reasoning, how to effectively organize multiple agents remains an open question. In this paper, we introduce OrgAgent, a company-style hierarchical multi-agent framework that separates collaboration into governance, execution, and compliance layers. OrgAgent decomposes multi-agent reasoning into three layers: a governance layer for planning and resource allocation, an execution layer for task solving and review, and a compliance layer for final answer control. By evaluating the framework across reasoning tasks, LLMs, execution modes, and execution policies, we find that multi-agent systems organized in a company-style hierarchy generally outperform other organizational structures. Besides, hierarchical coordination also reduces token consumption relative to flat collaboration in most settings. For example, for GPT-OSS-120B, the hierarchical setting improves performance over flat multi-agent system by 102.73% while reducing token usage by 74.52% on SQuAD 2.0. Further analysis shows that hierarchy helps most when tasks benefit from stable skill assignment, controlled information flow, and layered verification. Overall, our findings highlight organizational structure as an important factor in multi-agent reasoning, shaping not only effectiveness and cost, but also coordination behavior.
KCLNet: Electrically Equivalence-Oriented Graph Representation Learning for Analog Circuits
Mar 25, 2026Digital circuits representation learning has made remarkable progress in the electronic design automation domain, effectively supporting critical tasks such as testability analysis and logic reasoning. However, representation learning for analog circuits remains challenging due to their continuous electrical characteristics compared to the discrete states of digital circuits. This paper presents a direct current (DC) electrically equivalent-oriented analog representation learning framework, named \textbf{KCLNet}. It comprises an asynchronous graph neural network structure with electrically-simulated message passing and a representation learning method inspired by Kirchhoff's Current Law (KCL). This method maintains the orderliness of the circuit embedding space by enforcing the equality of the sum of outgoing and incoming current embeddings at each depth, which significantly enhances the generalization ability of circuit embeddings. KCLNet offers a novel and effective solution for analog circuit representation learning with electrical constraints preserved. Experimental results demonstrate that our method achieves significant performance in a variety of downstream tasks, e.g., analog circuit classification, subcircuit detection, and circuit edit distance prediction.
Steering Externalities: Benign Activation Steering Unintentionally Increases Jailbreak Risk for Large Language Models
Feb 03, 2026Activation steering is a practical post-training model alignment technique to enhance the utility of Large Language Models (LLMs). Prior to deploying a model as a service, developers can steer a pre-trained model toward specific behavioral objectives, such as compliance or instruction adherence, without the need for retraining. This process is as simple as adding a steering vector to the model's internal representations. However, this capability unintentionally introduces critical and under-explored safety risks. We identify a phenomenon termed Steering Externalities, where steering vectors derived from entirely benign datasets-such as those enforcing strict compliance or specific output formats like JSON-inadvertently erode safety guardrails. Experiments reveal that these interventions act as a force multiplier, creating new vulnerabilities to jailbreaks and increasing attack success rates to over 80% on standard benchmarks by bypassing the initial safety alignment. Ultimately, our results expose a critical blind spot in deployment: benign activation steering systematically erodes the "safety margin," rendering models more vulnerable to black-box attacks and proving that inference-time utility improvements must be rigorously audited for unintended safety externalities.
Optimization-Free Universal Watermark Forgery with Regenerative Diffusion Models
Jun 06, 2025Watermarking becomes one of the pivotal solutions to trace and verify the origin of synthetic images generated by artificial intelligence models, but it is not free of risks. Recent studies demonstrate the capability to forge watermarks from a target image onto cover images via adversarial optimization without knowledge of the target generative model and watermark schemes. In this paper, we uncover a greater risk of an optimization-free and universal watermark forgery that harnesses existing regenerative diffusion models. Our proposed forgery attack, PnP (Plug-and-Plant), seamlessly extracts and integrates the target watermark via regenerating the image, without needing any additional optimization routine. It allows for universal watermark forgery that works independently of the target image's origin or the watermarking model used. We explore the watermarked latent extracted from the target image and visual-textual context of cover images as priors to guide sampling of the regenerative process. Extensive evaluation on 24 scenarios of model-data-watermark combinations demonstrates that PnP can successfully forge the watermark (up to 100% detectability and user attribution), and maintain the best visual perception. By bypassing model retraining and enabling adaptability to any image, our approach significantly broadens the scope of forgery attacks, presenting a greater challenge to the security of current watermarking techniques for diffusion models and the authority of watermarking schemes in synthetic data generation and governance.
Hey, That's My Data! Label-Only Dataset Inference in Large Language Models
Jun 06, 2025Large Language Models (LLMs) have revolutionized Natural Language Processing by excelling at interpreting, reasoning about, and generating human language. However, their reliance on large-scale, often proprietary datasets poses a critical challenge: unauthorized usage of such data can lead to copyright infringement and significant financial harm. Existing dataset-inference methods typically depend on log probabilities to detect suspicious training material, yet many leading LLMs have begun withholding or obfuscating these signals. This reality underscores the pressing need for label-only approaches capable of identifying dataset membership without relying on internal model logits. We address this gap by introducing CatShift, a label-only dataset-inference framework that capitalizes on catastrophic forgetting: the tendency of an LLM to overwrite previously learned knowledge when exposed to new data. If a suspicious dataset was previously seen by the model, fine-tuning on a portion of it triggers a pronounced post-tuning shift in the model's outputs; conversely, truly novel data elicits more modest changes. By comparing the model's output shifts for a suspicious dataset against those for a known non-member validation set, we statistically determine whether the suspicious set is likely to have been part of the model's original training corpus. Extensive experiments on both open-source and API-based LLMs validate CatShift's effectiveness in logit-inaccessible settings, offering a robust and practical solution for safeguarding proprietary data.
Why LLM Safety Guardrails Collapse After Fine-tuning: A Similarity Analysis Between Alignment and Fine-tuning Datasets
Jun 05, 2025Recent advancements in large language models (LLMs) have underscored their vulnerability to safety alignment jailbreaks, particularly when subjected to downstream fine-tuning. However, existing mitigation strategies primarily focus on reactively addressing jailbreak incidents after safety guardrails have been compromised, removing harmful gradients during fine-tuning, or continuously reinforcing safety alignment throughout fine-tuning. As such, they tend to overlook a critical upstream factor: the role of the original safety-alignment data. This paper therefore investigates the degradation of safety guardrails through the lens of representation similarity between upstream alignment datasets and downstream fine-tuning tasks. Our experiments demonstrate that high similarity between these datasets significantly weakens safety guardrails, making models more susceptible to jailbreaks. Conversely, low similarity between these two types of datasets yields substantially more robust models and thus reduces harmfulness score by up to 10.33%. By highlighting the importance of upstream dataset design in the building of durable safety guardrails and reducing real-world vulnerability to jailbreak attacks, these findings offer actionable insights for fine-tuning service providers.
Unsupervised Out-of-Distribution Detection in Medical Imaging Using Multi-Exit Class Activation Maps and Feature Masking
May 13, 2025Out-of-distribution (OOD) detection is essential for ensuring the reliability of deep learning models in medical imaging applications. This work is motivated by the observation that class activation maps (CAMs) for in-distribution (ID) data typically emphasize regions that are highly relevant to the model's predictions, whereas OOD data often lacks such focused activations. By masking input images with inverted CAMs, the feature representations of ID data undergo more substantial changes compared to those of OOD data, offering a robust criterion for differentiation. In this paper, we introduce a novel unsupervised OOD detection framework, Multi-Exit Class Activation Map (MECAM), which leverages multi-exit CAMs and feature masking. By utilizing mult-exit networks that combine CAMs from varying resolutions and depths, our method captures both global and local feature representations, thereby enhancing the robustness of OOD detection. We evaluate MECAM on multiple ID datasets, including ISIC19 and PathMNIST, and test its performance against three medical OOD datasets, RSNA Pneumonia, COVID-19, and HeadCT, and one natural image OOD dataset, iSUN. Comprehensive comparisons with state-of-the-art OOD detection methods validate the effectiveness of our approach. Our findings emphasize the potential of multi-exit networks and feature masking for advancing unsupervised OOD detection in medical imaging, paving the way for more reliable and interpretable models in clinical practice.
Retention Score: Quantifying Jailbreak Risks for Vision Language Models
Dec 23, 2024The emergence of Vision-Language Models (VLMs) is a significant advancement in integrating computer vision with Large Language Models (LLMs) to enhance multi-modal machine learning capabilities. However, this progress has also made VLMs vulnerable to sophisticated adversarial attacks, raising concerns about their reliability. The objective of this paper is to assess the resilience of VLMs against jailbreak attacks that can compromise model safety compliance and result in harmful outputs. To evaluate a VLM's ability to maintain its robustness against adversarial input perturbations, we propose a novel metric called the \textbf{Retention Score}. Retention Score is a multi-modal evaluation metric that includes Retention-I and Retention-T scores for quantifying jailbreak risks in visual and textual components of VLMs. Our process involves generating synthetic image-text pairs using a conditional diffusion model. These pairs are then predicted for toxicity score by a VLM alongside a toxicity judgment classifier. By calculating the margin in toxicity scores, we can quantify the robustness of the VLM in an attack-agnostic manner. Our work has four main contributions. First, we prove that Retention Score can serve as a certified robustness metric. Second, we demonstrate that most VLMs with visual components are less robust against jailbreak attacks than the corresponding plain VLMs. Additionally, we evaluate black-box VLM APIs and find that the security settings in Google Gemini significantly affect the score and robustness. Moreover, the robustness of GPT4V is similar to the medium settings of Gemini. Finally, our approach offers a time-efficient alternative to existing adversarial attack methods and provides consistent model robustness rankings when evaluated on VLMs including MiniGPT-4, InstructBLIP, and LLaVA.
* 14 pages, 8 figures, AAAI 2025
Echo: Simulating Distributed Training At Scale
Dec 17, 2024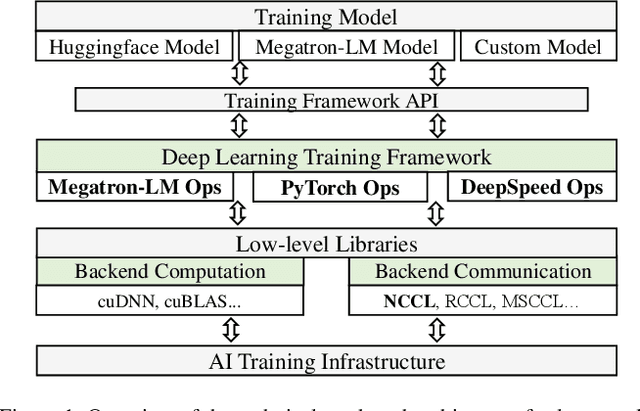


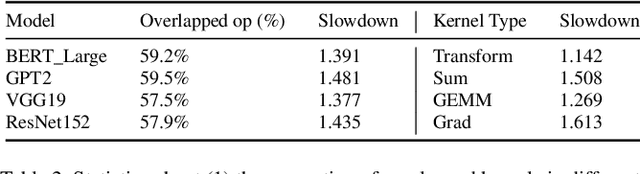
Simulation offers unique values for both enumeration and extrapolation purposes, and is becoming increasingly important for managing the massive machine learning (ML) clusters and large-scale distributed training jobs. In this paper, we build Echo to tackle three key challenges in large-scale training simulation: (1) tracing the runtime training workloads at each device in an ex-situ fashion so we can use a single device to obtain the actual execution graphs of 1K-GPU training, (2) accurately estimating the collective communication without high overheads of discrete-event based network simulation, and (3) accounting for the interference-induced computation slowdown from overlapping communication and computation kernels on the same device. Echo delivers on average 8% error in training step -- roughly 3x lower than state-of-the-art simulators -- for GPT-175B on a 96-GPU H800 cluster with 3D parallelism on Megatron-LM under 2 minutes.