 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization-Free Universal Watermark Forgery with Regenerative Diffusion Models
Jun 06, 2025Watermarking becomes one of the pivotal solutions to trace and verify the origin of synthetic images generated by artificial intelligence models, but it is not free of risks. Recent studies demonstrate the capability to forge watermarks from a target image onto cover images via adversarial optimization without knowledge of the target generative model and watermark schemes. In this paper, we uncover a greater risk of an optimization-free and universal watermark forgery that harnesses existing regenerative diffusion models. Our proposed forgery attack, PnP (Plug-and-Plant), seamlessly extracts and integrates the target watermark via regenerating the image, without needing any additional optimization routine. It allows for universal watermark forgery that works independently of the target image's origin or the watermarking model used. We explore the watermarked latent extracted from the target image and visual-textual context of cover images as priors to guide sampling of the regenerative process. Extensive evaluation on 24 scenarios of model-data-watermark combinations demonstrates that PnP can successfully forge the watermark (up to 100% detectability and user attribution), and maintain the best visual perception. By bypassing model retraining and enabling adaptability to any image, our approach significantly broadens the scope of forgery attacks, presenting a greater challenge to the security of current watermarking techniques for diffusion models and the authority of watermarking schemes in synthetic data generation and governance.
TimeWak: Temporal Chained-Hashing Watermark for Time Series Data
Jun 06, 2025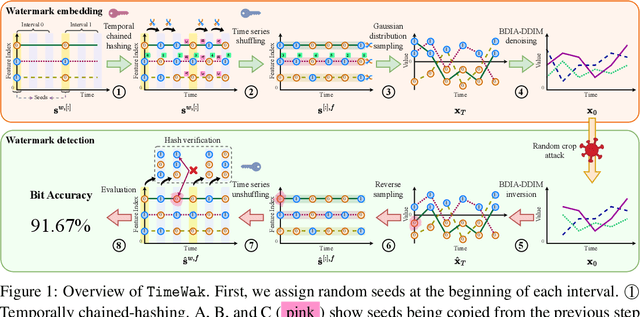
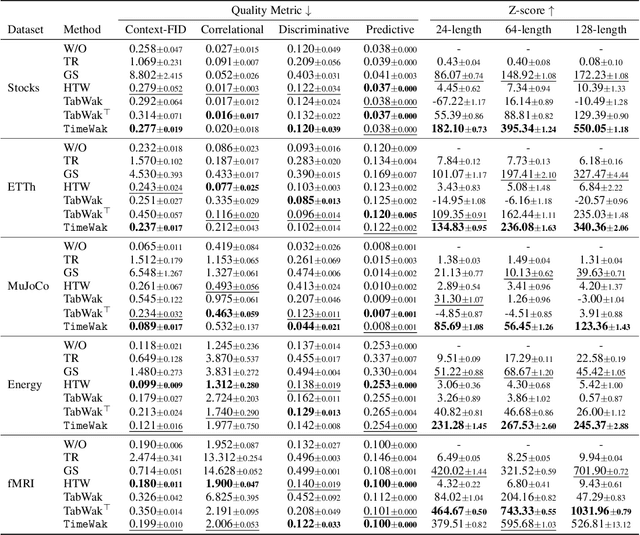
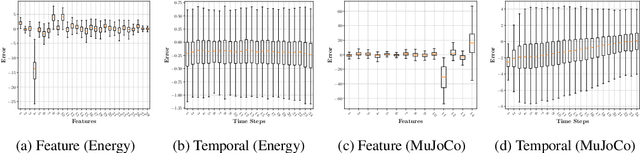
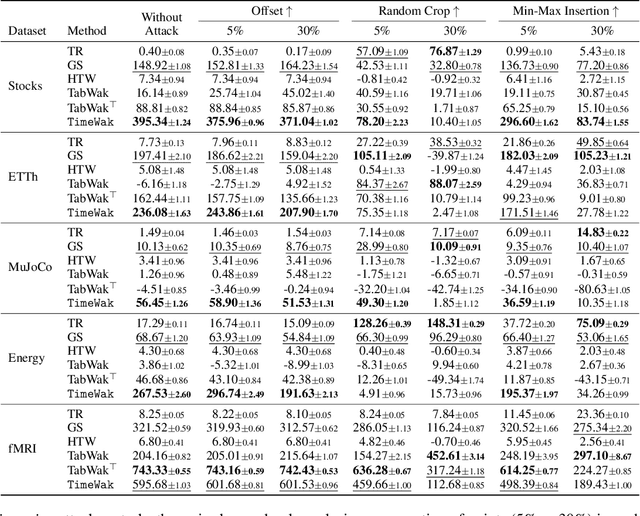
Synthetic time series generated by diffusion models enable sharing privacy-sensitive datasets, such as patients' functional MRI records. Key criteria for synthetic data include high data utility and traceability to verify the data source. Recent watermarking methods embed in homogeneous latent spaces, but state-of-the-art time series generators operate in real space, making latent-based watermarking incompatible. This creates the challenge of watermarking directly in real space while handling feature heterogeneity and temporal dependencies. We propose TimeWak, the first watermarking algorithm for multivariate time series diffusion models. To handle temporal dependence and spatial heterogeneity, TimeWak embeds a temporal chained-hashing watermark directly within the real temporal-feature space. The other unique feature is the $\epsilon$-exact inversion, which addresses the non-uniform reconstruction error distribution across features from inverting the diffusion process to detect watermarks. We derive the error bound of inverting multivariate time series and further maintain high watermark detectability. We extensively evaluate TimeWak on its impact on synthetic data quality, watermark detectability, and robustness under various post-editing attacks, against 5 datasets and baselines of different temporal lengths. Our results show that TimeWak achieves improvements of 61.96% in context-FID score, and 8.44% in correlational scores against the state-of-the-art baseline, while remaining consistently detectable.
TS-Inverse: A Gradient Inversion Attack Tailored for Federated Time Series Forecasting Models
Mar 26, 2025



Federated learning (FL) for time series forecasting (TSF) enables clients with privacy-sensitive time series (TS) data to collaboratively learn accurate forecasting models, for example, in energy load prediction. Unfortunately, privacy risks in FL persist, as servers can potentially reconstruct clients' training data through gradient inversion attacks (GIA). Although GIA is demonstrated for image classification tasks, little is known about time series regression tasks. In this paper, we first conduct an extensive empirical study on inverting TS data across 4 TSF models and 4 datasets, identifying the unique challenges of reconstructing both observations and targets of TS data. We then propose TS-Inverse, a novel GIA that improves the inversion of TS data by (i) learning a gradient inversion model that outputs quantile predictions, (ii) a unique loss function that incorporates periodicity and trend regularization, and (iii) regularization according to the quantile predictions. Our evaluations demonstrate a remarkable performance of TS-Inverse, achieving at least a 2x-10x improvement in terms of the sMAPE metric over existing GIA methods on TS data. Code repository: https://github.com/Capsar/ts-inverse
WaveStitch: Flexible and Fast Conditional Time Series Generation with Diffusion Models
Mar 08, 2025



Generating temporal data under constraints is critical for forecasting, imputation, and synthesis. These datasets often include auxiliary conditions that influence the values within the time series signal. Existing methods face three key challenges: (1) they fail to adapt to conditions at inference time; (2) they rely on sequential generation, which slows the generation speed; and (3) they inefficiently encode categorical features, leading to increased sparsity and input sizes. We propose WaveStitch, a novel method that addresses these challenges by leveraging denoising diffusion probabilistic models to efficiently generate accurate temporal data under given auxiliary constraints. WaveStitch overcomes these limitations by: (1) modeling interactions between constraints and signals to generalize to new, unseen conditions; (2) enabling the parallel synthesis of sequential segments with a novel "stitching" mechanism to enforce coherence across segments; and (3) encoding categorical features as compact periodic signals while preserving temporal patterns. Extensive evaluations across diverse datasets highlight WaveStitch's ability to generalize to unseen conditions during inference, achieving up to a 10x lower mean-squared-error compared to the state-of-the-art methods. Moreover, WaveStitch generates data up to 460x faster than autoregressive methods while maintaining comparable accuracy. By efficiently encoding categorical features, WaveStitch provides a robust and efficient solution for temporal data generation. Our code is open-sourced: https://github.com/adis98/HierarchicalTS
Multigraph Message Passing with Bi-Directional Multi-Edge Aggregations
Nov 29, 2024Graph Neural Networks (GNNs) have seen significant advances in recent years, yet their application to multigraphs, where parallel edges exist between the same pair of nodes, remains under-explored. Standard GNNs, designed for simple graphs, compute node representations by combining all connected edges at once, without distinguishing between edges from different neighbors. There are some GNN architectures proposed specifically for multigraph tasks, yet these architectures perform only node-level aggregation in their message-passing layers, which limits their expressive power. Furthermore, these approaches either lack permutation equivariance when a strict total edge ordering is absent, or fail to preserve the topological structure of the multigraph. To address all these shortcomings, we propose MEGA-GNN, a unified framework for message passing on multigraphs that can effectively perform diverse graph learning tasks. Our approach introduces a two-stage aggregation process in the message passing layers: first, parallel edges are aggregated, followed by a node-level aggregation that operates on aggregated messages from distinct neighbors. We show that MEGA-GNN supports permutation equivariance and invariance properties. We also show that MEGA-GNN is universal given a strict total order on the edges. Experiments on synthetic and real-world financial transaction datasets demonstrate that MEGA-GNN either significantly outperforms or is on par with the accuracy of state-of-the-art solutions.
MPQ-Diff: Mixed Precision Quantization for Diffusion Models
Nov 28, 2024Diffusion models (DMs) generate remarkable high quality images via the stochastic denoising process, which unfortunately incurs high sampling time. Post-quantizing the trained diffusion models in fixed bit-widths, e.g., 4 bits on weights and 8 bits on activation, is shown effective in accelerating sampling time while maintaining the image quality. Motivated by the observation that the cross-layer dependency of DMs vary across layers and sampling steps, we propose a mixed precision quantization scheme, MPQ-Diff, which allocates different bit-width to the weights and activation of the layers. We advocate to use the cross-layer correlation of a given layer, termed network orthogonality metric, as a proxy to measure the relative importance of a layer per sampling step. We further adopt a uniform sampling scheme to avoid the excessive profiling overhead of estimating orthogonality across all time steps. We evaluate the proposed mixed-precision on LSUN and ImageNet, showing a significant improvement in FID from 65.73 to 15.39, and 52.66 to 14.93, compared to their fixed precision quantization, respectively.
Federated Time Series Generation on Feature and Temporally Misaligned Data
Oct 28, 2024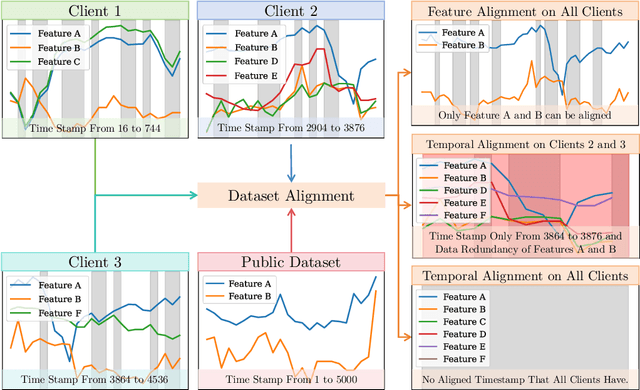

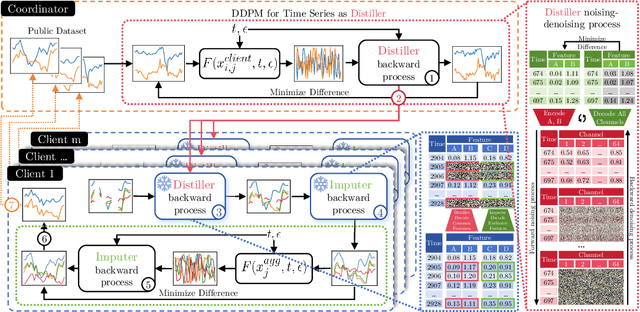
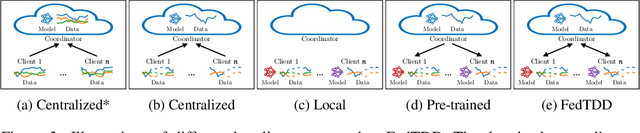
Distributed time series data presents a challenge for federated learning, as clients often possess different feature sets and have misaligned time steps. Existing federated time series models are limited by the assumption of perfect temporal or feature alignment across clients. In this paper, we propose FedTDD, a novel federated time series diffusion model that jointly learns a synthesizer across clients. At the core of FedTDD is a novel data distillation and aggregation framework that reconciles the differences between clients by imputing the misaligned timesteps and features. In contrast to traditional federated learning, FedTDD learns the correlation across clients' time series through the exchange of local synthetic outputs instead of model parameters. A coordinator iteratively improves a global distiller network by leveraging shared knowledge from clients through the exchange of synthetic data. As the distiller becomes more refined over time, it subsequently enhances the quality of the clients' local feature estimates, allowing each client to then improve its local imputations for missing data using the latest, more accurate distiller. Experimental results on five datasets demonstrate FedTDD's effectiveness compared to centralized training, and the effectiveness of sharing synthetic outputs to transfer knowledge of local time series. Notably, FedTDD achieves 79.4% and 62.8% improvement over local training in Context-FID and Correlational scores.
Parameterizing Federated Continual Learning for Reproducible Research
Jun 04, 2024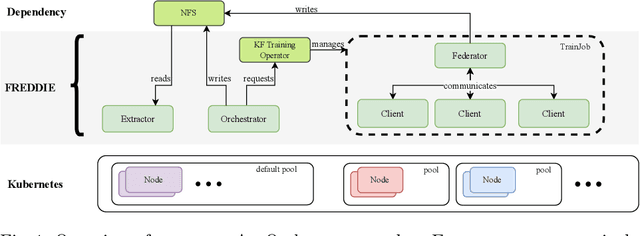

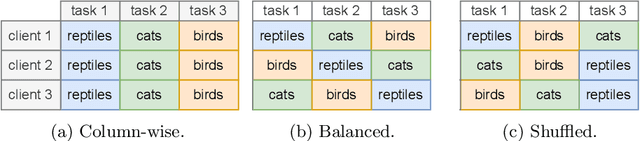
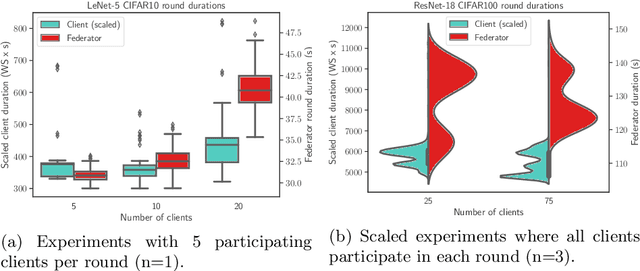
Federated Learning (FL) systems evolve in heterogeneous and ever-evolving environments that challenge their performance. Under real deployments, the learning tasks of clients can also evolve with time, which calls for the integration of methodologies such as Continual Learning. To enable research reproducibility, we propose a set of experimental best practices that precisely capture and emulate complex learning scenarios. Our framework, Freddie, is the first entirely configurable framework for Federated Continual Learning (FCL), and it can be seamlessly deployed on a large number of machines thanks to the use of Kubernetes and containerization. We demonstrate the effectiveness of Freddie on two use cases, (i) large-scale FL on CIFAR100 and (ii) heterogeneous task sequence on FCL, which highlight unaddressed performance challenges in FCL scenarios.
Asynchronous Multi-Server Federated Learning for Geo-Distributed Clients
Jun 03, 2024Federated learning (FL) systems enable multiple clients to train a machine learning model iteratively through synchronously exchanging the intermediate model weights with a single server. The scalability of such FL systems can be limited by two factors: server idle time due to synchronous communication and the risk of a single server becoming the bottleneck. In this paper, we propose a new FL architecture, to our knowledge, the first multi-server FL system that is entirely asynchronous, and therefore addresses these two limitations simultaneously. Our solution keeps both servers and clients continuously active. As in previous multi-server methods, clients interact solely with their nearest server, ensuring efficient update integration into the model. Differently, however, servers also periodically update each other asynchronously, and never postpone interactions with clients. We compare our solution to three representative baselines - FedAvg, FedAsync and HierFAVG - on the MNIST and CIFAR-10 image classification datasets and on the WikiText-2 language modeling dataset. Our solution converges to similar or higher accuracy levels than previous baselines and requires 61% less time to do so in geo-distributed settings.
Asynchronous Byzantine Federated Learning
Jun 03, 2024Federated learning (FL) enables a set of geographically distributed clients to collectively train a model through a server. Classically, the training process is synchronous, but can be made asynchronous to maintain its speed in presence of slow clients and in heterogeneous networks. The vast majority of Byzantine fault-tolerant FL systems however rely on a synchronous training process. Our solution is one of the first Byzantine-resilient and asynchronous FL algorithms that does not require an auxiliary server dataset and is not delayed by stragglers, which are shortcomings of previous works. Intuitively, the server in our solution waits to receive a minimum number of updates from clients on its latest model to safely update it, and is later able to safely leverage the updates that late clients might send. We compare the performance of our solution with state-of-the-art algorithms on both image and text datasets under gradient inversion, perturbation, and backdoor attacks. Our results indicate that our solution trains a model faster than previous synchronous FL solution, and maintains a higher accuracy, up to 1.54x and up to 1.75x for perturbation and gradient inversion attacks respectively, in the presence of Byzantine clients than previous asynchronous FL solutions.