 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultigraph Message Passing with Bi-Directional Multi-Edge Aggregations
Nov 29, 2024Graph Neural Networks (GNNs) have seen significant advances in recent years, yet their application to multigraphs, where parallel edges exist between the same pair of nodes, remains under-explored. Standard GNNs, designed for simple graphs, compute node representations by combining all connected edges at once, without distinguishing between edges from different neighbors. There are some GNN architectures proposed specifically for multigraph tasks, yet these architectures perform only node-level aggregation in their message-passing layers, which limits their expressive power. Furthermore, these approaches either lack permutation equivariance when a strict total edge ordering is absent, or fail to preserve the topological structure of the multigraph. To address all these shortcomings, we propose MEGA-GNN, a unified framework for message passing on multigraphs that can effectively perform diverse graph learning tasks. Our approach introduces a two-stage aggregation process in the message passing layers: first, parallel edges are aggregated, followed by a node-level aggregation that operates on aggregated messages from distinct neighbors. We show that MEGA-GNN supports permutation equivariance and invariance properties. We also show that MEGA-GNN is universal given a strict total order on the edges. Experiments on synthetic and real-world financial transaction datasets demonstrate that MEGA-GNN either significantly outperforms or is on par with the accuracy of state-of-the-art solutions.
Graph Feature Preprocessor: Real-time Extraction of Subgraph-based Features from Transaction Graphs
Feb 13, 2024
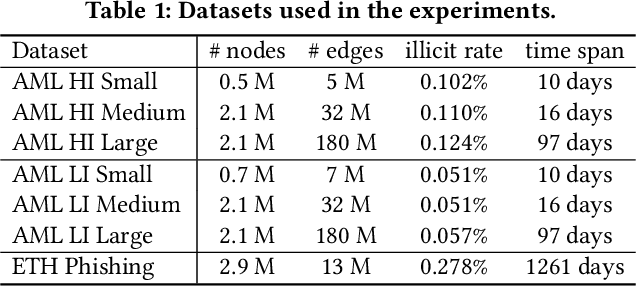


In this paper, we present "Graph Feature Preprocessor", a software library for detecting typical money laundering and fraud patterns in financial transaction graphs in real time. These patterns are used to produce a rich set of transaction features for downstream machine learning training and inference tasks such as money laundering detection. We show that our enriched transaction features dramatically improve the prediction accuracy of gradient-boosting-based machine learning models. Our library exploits multicore parallelism, maintains a dynamic in-memory graph, and efficiently mines subgraph patterns in the incoming transaction stream, which enables it to be operated in a streaming manner. We evaluate our library using highly-imbalanced synthetic anti-money laundering (AML) and real-life Ethereum phishing datasets. In these datasets, the proportion of illicit transactions is very small, which makes the learning process challenging. Our solution, which combines our Graph Feature Preprocessor and gradient-boosting-based machine learning models, is able to detect these illicit transactions with higher minority-class F1 scores than standard graph neural networks. In addition, the end-to-end throughput rate of our solution executed on a multicore CPU outperforms the graph neural network baselines executed on a powerful V100 GPU. Overall, the combination of high accuracy, a high throughput rate, and low latency of our solution demonstrates the practical value of our library in real-world applications. Graph Feature Preprocessor has been integrated into IBM mainframe software products, namely "IBM Cloud Pak for Data on Z" and "AI Toolkit for IBM Z and LinuxONE".
Realistic Synthetic Financial Transactions for Anti-Money Laundering Models
Jun 22, 2023



With the widespread digitization of finance and the increasing popularity of cryptocurrencies, the sophistication of fraud schemes devised by cybercriminals is growing. Money laundering -- the movement of illicit funds to conceal their origins -- can cross bank and national boundaries, producing complex transaction patterns. The UN estimates 2-5\% of global GDP or \$0.8 - \$2.0 trillion dollars are laundered globally each year. Unfortunately, real data to train machine learning models to detect laundering is generally not available, and previous synthetic data generators have had significant shortcomings. A realistic, standardized, publicly-available benchmark is needed for comparing models and for the advancement of the area. To this end, this paper contributes a synthetic financial transaction dataset generator and a set of synthetically generated AML (Anti-Money Laundering) datasets. We have calibrated this agent-based generator to match real transactions as closely as possible and made the datasets public. We describe the generator in detail and demonstrate how the datasets generated can help compare different Graph Neural Networks in terms of their AML abilities. In a key way, using synthetic data in these comparisons can be even better than using real data: the ground truth labels are complete, whilst many laundering transactions in real data are never detected.
Provably Powerful Graph Neural Networks for Directed Multigraphs
Jun 20, 2023
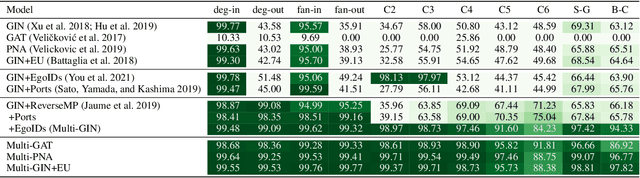
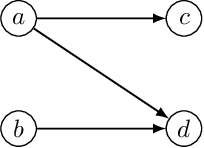
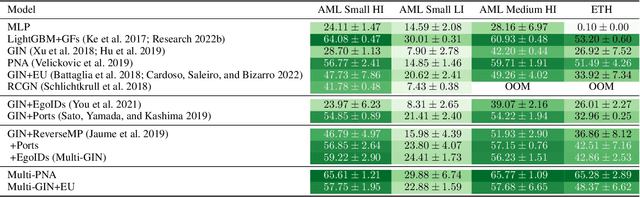
This paper proposes a set of simple adaptations to transform standard message-passing Graph Neural Networks (GNN) into provably powerful directed multigraph neural networks. The adaptations include multigraph port numbering, ego IDs, and reverse message passing. We prove that the combination of these theoretically enables the detection of any directed subgraph pattern. To validate the effectiveness of our proposed adaptations in practice, we conduct experiments on synthetic subgraph detection tasks, which demonstrate outstanding performance with almost perfect results. Moreover, we apply our proposed adaptations to two financial crime analysis tasks. We observe dramatic improvements in detecting money laundering transactions, improving the minority-class F1 score of a standard message-passing GNN by up to 45%, and clearly outperforming tree-based and GNN baselines. Similarly impressive results are observed on a real-world phishing detection dataset, boosting a standard GNN's F1 score by over 15% and outperforming all baselines.
Low-Complexity Data-Parallel Earth Mover's Distance Approximations
Dec 05, 2018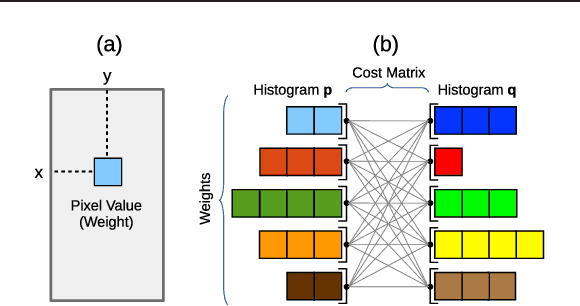
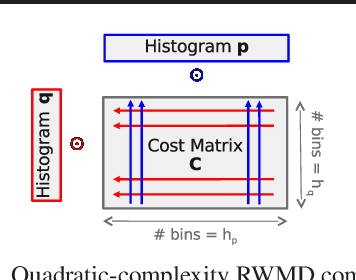
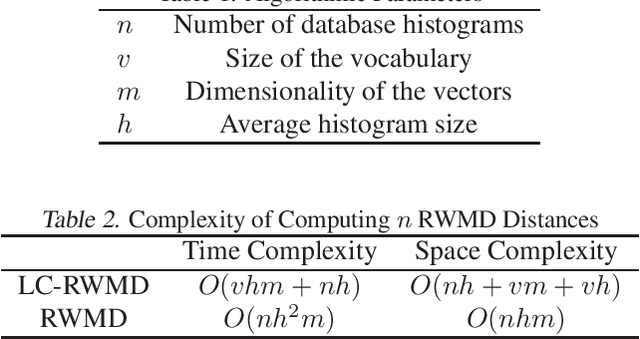
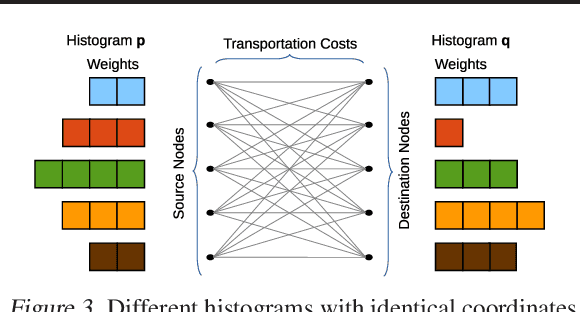
The Earth Mover's Distance (EMD) is a state-of-the art metric for comparing probability distributions. The high distinguishability offered by the EMD comes at a high cost in computational complexity. Therefore, linear-complexity approximation algorithms have been proposed to improve its scalability. However, these algorithms are either limited to vector spaces with only a few dimensions or require the probability distributions to populate the vector space sparsely. We propose novel approximation algorithms that overcome both of these limitations, yet still achieve linear time complexity. All our algorithms are data parallel, and therefore, we can take advantage of massively parallel computing engines, such as Graphics Processing Units (GPUs). The experiments on MNIST images show that the new algorithms can perform a billion distance computations in less than a minute using a single GPU. On the popular text-based 20 Newsgroups dataset, the new algorithms are four orders of magnitude faster than the state-of-the-art FastEMD library and match its search accuracy.
Understanding and Optimizing the Performance of Distributed Machine Learning Applications on Apache Spark
Dec 13, 2017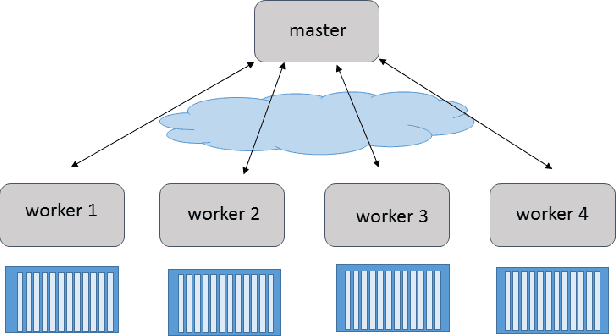
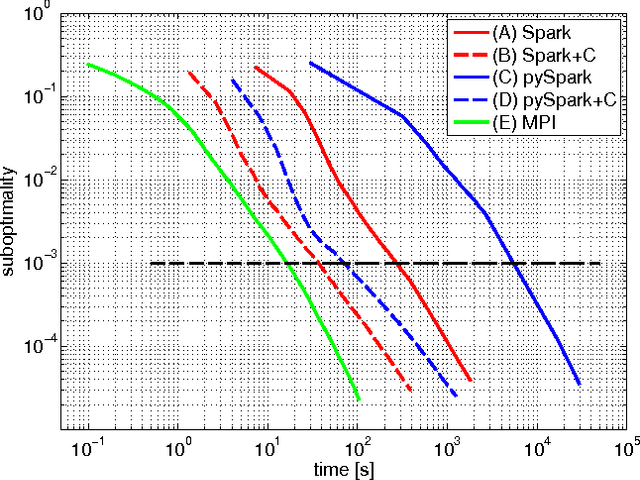
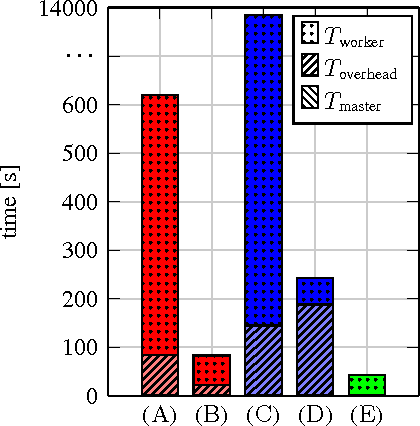
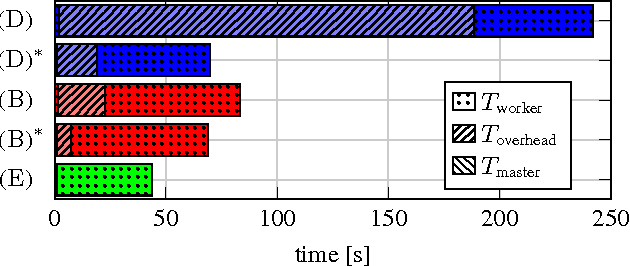
In this paper we explore the performance limits of Apache Spark for machine learning applications. We begin by analyzing the characteristics of a state-of-the-art distributed machine learning algorithm implemented in Spark and compare it to an equivalent reference implementation using the high performance computing framework MPI. We identify critical bottlenecks of the Spark framework and carefully study their implications on the performance of the algorithm. In order to improve Spark performance we then propose a number of practical techniques to alleviate some of its overheads. However, optimizing computational efficiency and framework related overheads is not the only key to performance -- we demonstrate that in order to get the best performance out of any implementation it is necessary to carefully tune the algorithm to the respective trade-off between computation time and communication latency. The optimal trade-off depends on both the properties of the distributed algorithm as well as infrastructure and framework-related characteristics. Finally, we apply these technical and algorithmic optimizations to three different distributed linear machine learning algorithms that have been implemented in Spark. We present results using five large datasets and demonstrate that by using the proposed optimizations, we can achieve a reduction in the performance difference between Spark and MPI from 20x to 2x.
Large-Scale Stochastic Learning using GPUs
Feb 22, 2017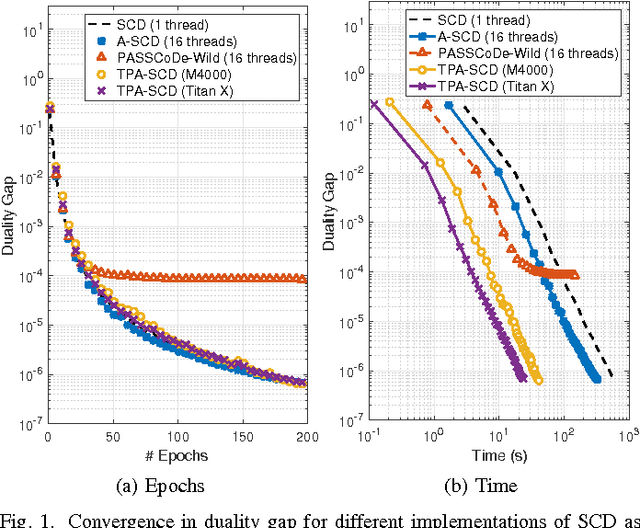
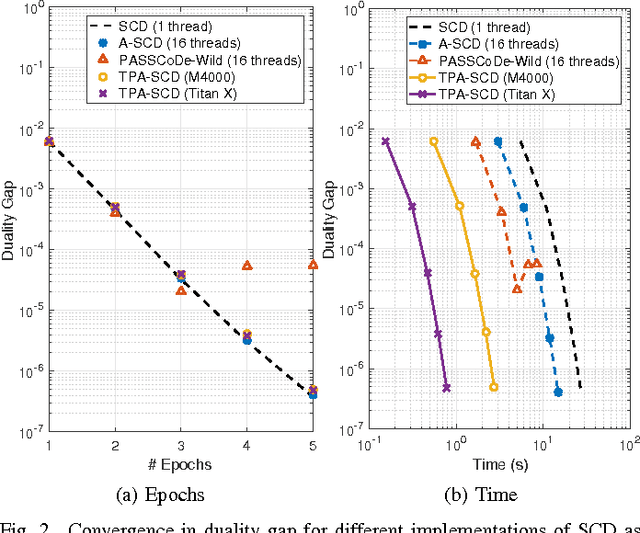
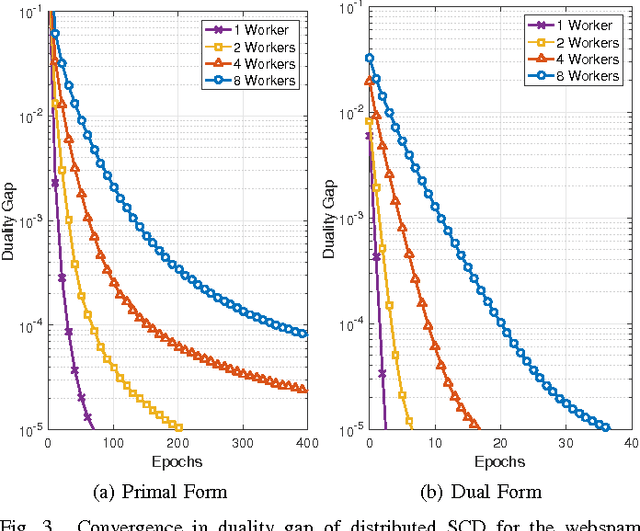
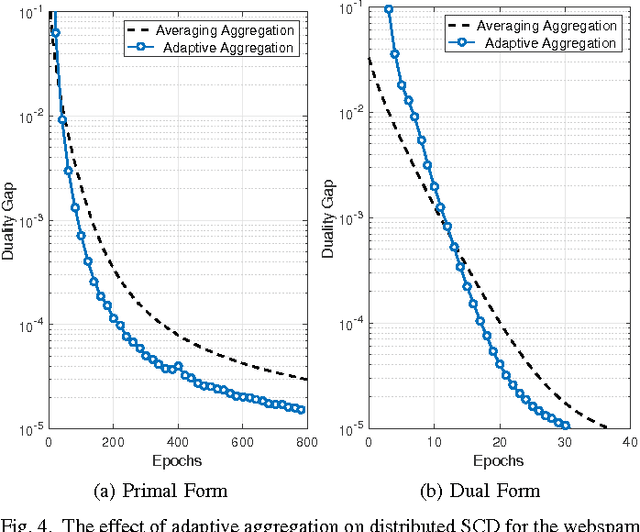
In this work we propose an accelerated stochastic learning system for very large-scale applications. Acceleration is achieved by mapping the training algorithm onto massively parallel processors: we demonstrate a parallel, asynchronous GPU implementation of the widely used stochastic coordinate descent/ascent algorithm that can provide up to 35x speed-up over a sequential CPU implementation. In order to train on very large datasets that do not fit inside the memory of a single GPU, we then consider techniques for distributed stochastic learning. We propose a novel method for optimally aggregating model updates from worker nodes when the training data is distributed either by example or by feature. Using this technique, we demonstrate that one can scale out stochastic learning across up to 8 worker nodes without any significant loss of training time. Finally, we combine GPU acceleration with the optimized distributed method to train on a dataset consisting of 200 million training examples and 75 million features. We show by scaling out across 4 GPUs, one can attain a high degree of training accuracy in around 4 seconds: a 20x speed-up in training time compared to a multi-threaded, distributed implementation across 4 CPUs.