 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWannaLaugh: A Configurable Ransomware Emulator -- Learning to Mimic Malicious Storage Traces
Mar 12, 2024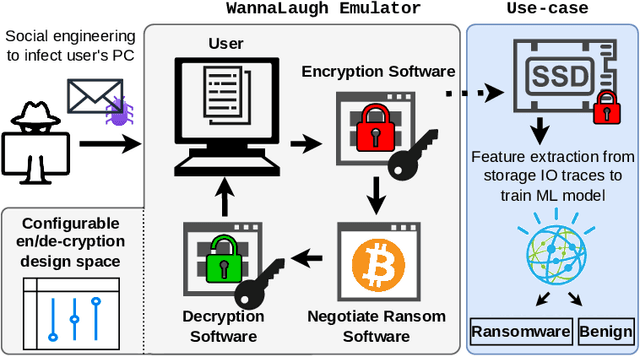
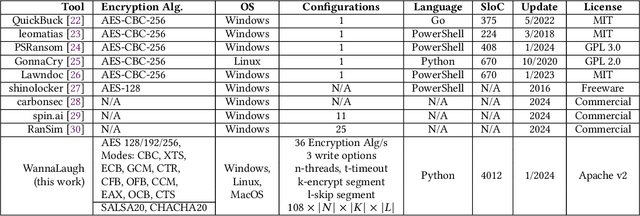
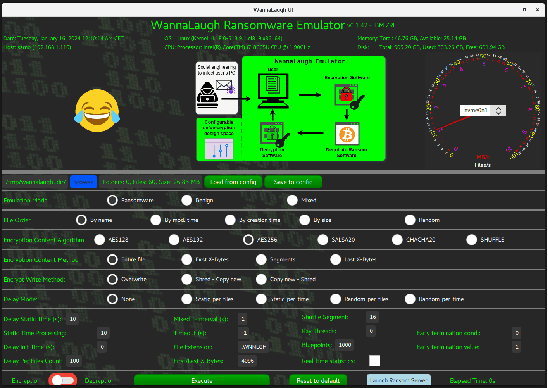
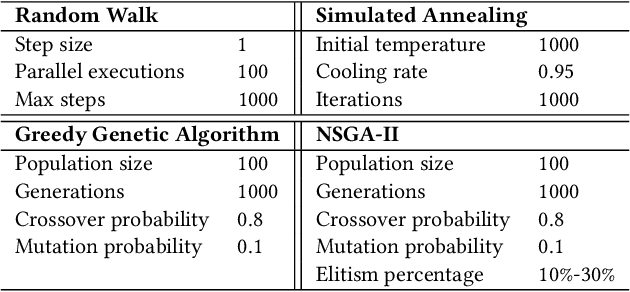
Ransomware, a fearsome and rapidly evolving cybersecurity threat, continues to inflict severe consequences on individuals and organizations worldwide. Traditional detection methods, reliant on static signatures and application behavioral patterns, are challenged by the dynamic nature of these threats. This paper introduces three primary contributions to address this challenge. First, we introduce a ransomware emulator. This tool is designed to safely mimic ransomware attacks without causing actual harm or spreading malware, making it a unique solution for studying ransomware behavior. Second, we demonstrate how we use this emulator to create storage I/O traces. These traces are then utilized to train machine-learning models. Our results show that these models are effective in detecting ransomware, highlighting the practical application of our emulator in developing responsible cybersecurity tools. Third, we show how our emulator can be used to mimic the I/O behavior of existing ransomware thereby enabling safe trace collection. Both the emulator and its application represent significant steps forward in ransomware detection in the era of machine-learning-driven cybersecurity.
Graph Feature Preprocessor: Real-time Extraction of Subgraph-based Features from Transaction Graphs
Feb 13, 2024
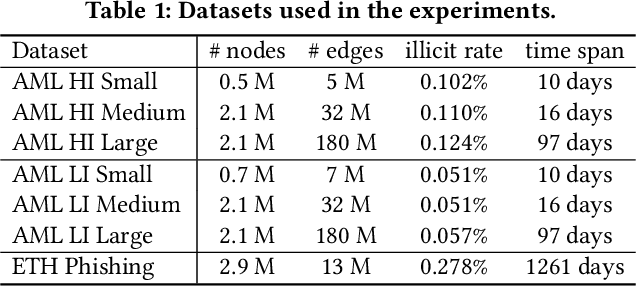


In this paper, we present "Graph Feature Preprocessor", a software library for detecting typical money laundering and fraud patterns in financial transaction graphs in real time. These patterns are used to produce a rich set of transaction features for downstream machine learning training and inference tasks such as money laundering detection. We show that our enriched transaction features dramatically improve the prediction accuracy of gradient-boosting-based machine learning models. Our library exploits multicore parallelism, maintains a dynamic in-memory graph, and efficiently mines subgraph patterns in the incoming transaction stream, which enables it to be operated in a streaming manner. We evaluate our library using highly-imbalanced synthetic anti-money laundering (AML) and real-life Ethereum phishing datasets. In these datasets, the proportion of illicit transactions is very small, which makes the learning process challenging. Our solution, which combines our Graph Feature Preprocessor and gradient-boosting-based machine learning models, is able to detect these illicit transactions with higher minority-class F1 scores than standard graph neural networks. In addition, the end-to-end throughput rate of our solution executed on a multicore CPU outperforms the graph neural network baselines executed on a powerful V100 GPU. Overall, the combination of high accuracy, a high throughput rate, and low latency of our solution demonstrates the practical value of our library in real-world applications. Graph Feature Preprocessor has been integrated into IBM mainframe software products, namely "IBM Cloud Pak for Data on Z" and "AI Toolkit for IBM Z and LinuxONE".
Breadth-first, Depth-next Training of Random Forests
Oct 15, 2019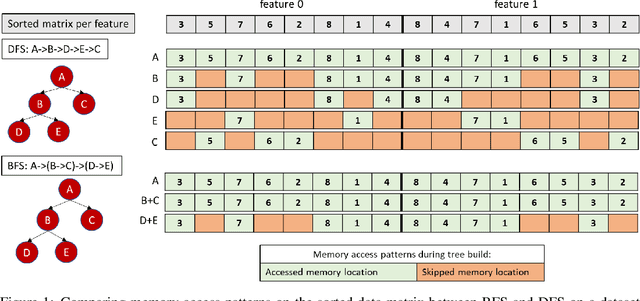
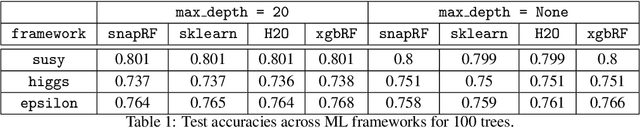
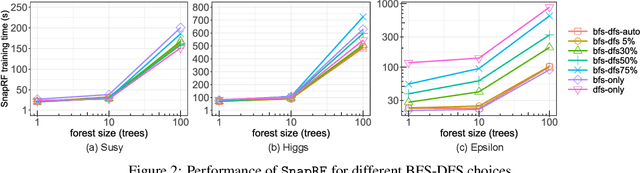
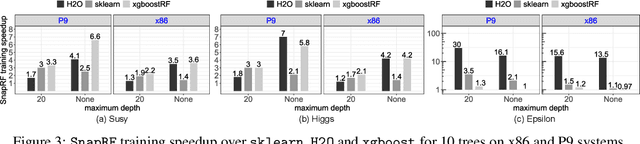
In this paper we analyze, evaluate, and improve the performance of training Random Forest (RF) models on modern CPU architectures. An exact, state-of-the-art binary decision tree building algorithm is used as the basis of this study. Firstly, we investigate the trade-offs between using different tree building algorithms, namely breadth-first-search (BFS) and depth-search-first (DFS). We design a novel, dynamic, hybrid BFS-DFS algorithm and demonstrate that it performs better than both BFS and DFS, and is more robust in the presence of workloads with different characteristics. Secondly, we identify CPU performance bottlenecks when generating trees using this approach, and propose optimizations to alleviate them. The proposed hybrid tree building algorithm for RF is implemented in the Snap Machine Learning framework, and speeds up the training of RFs by 7.8x on average when compared to state-of-the-art RF solvers (sklearn, H2O, and xgboost) on a range of datasets, RF configurations, and multi-core CPU architectures.
Weighted Sampling for Combined Model Selection and Hyperparameter Tuning
Sep 17, 2019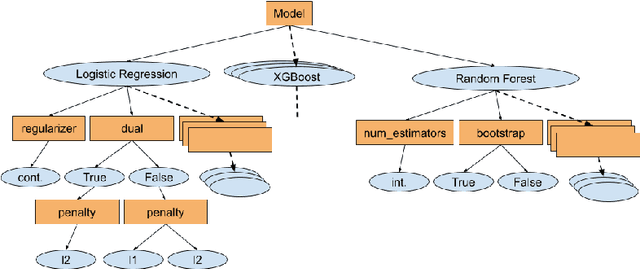
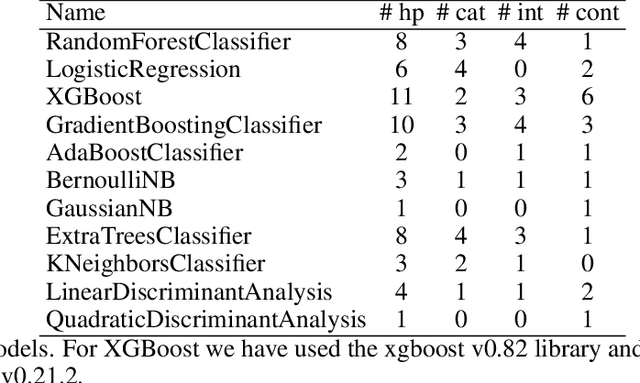
The combined algorithm selection and hyperparameter tuning (CASH) problem is characterized by large hierarchical hyperparameter spaces. Model-free hyperparameter tuning methods can explore such large spaces efficiently since they are highly parallelizable across multiple machines. When no prior knowledge or meta-data exists to boost their performance, these methods commonly sample random configurations following a uniform distribution. In this work, we propose a novel sampling distribution as an alternative to uniform sampling and prove theoretically that it has a better chance of finding the best configuration in a worst-case setting. In order to compare competing methods rigorously in an experimental setting, one must perform statistical hypothesis testing. We show that there is little-to-no agreement in the automated machine learning literature regarding which methods should be used. We contrast this disparity with the methods recommended by the broader statistics literature, and identify the most suitable approach. We then select three popular model-free solutions to CASH and evaluate their performance, with uniform sampling as well as the proposed sampling scheme, across 67 datasets from the OpenML platform. We investigate the trade-off between exploration and exploitation across the three algorithms, and verify empirically that the proposed sampling distribution improves performance in all cases.
Large-Scale Stochastic Learning using GPUs
Feb 22, 2017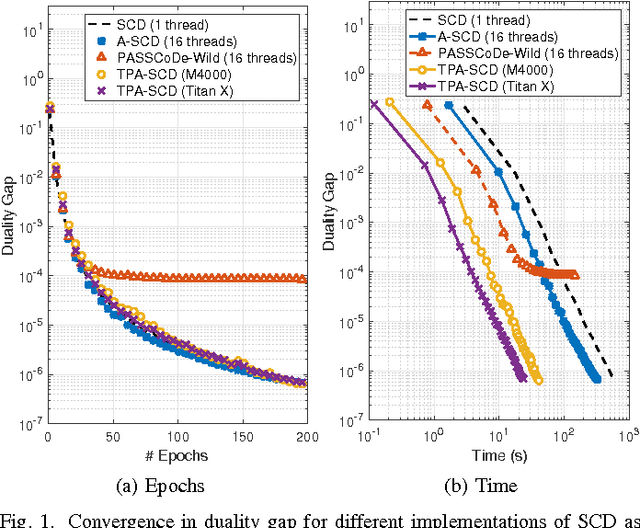
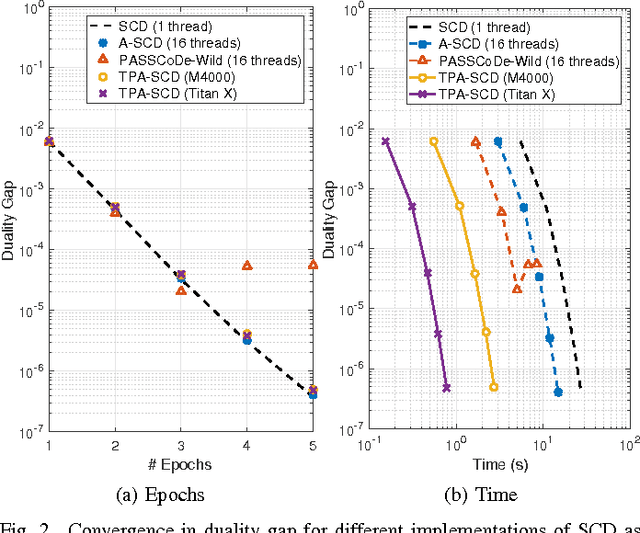
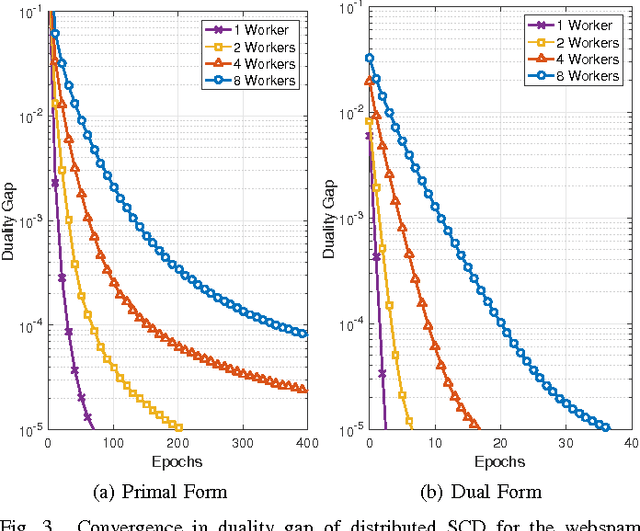
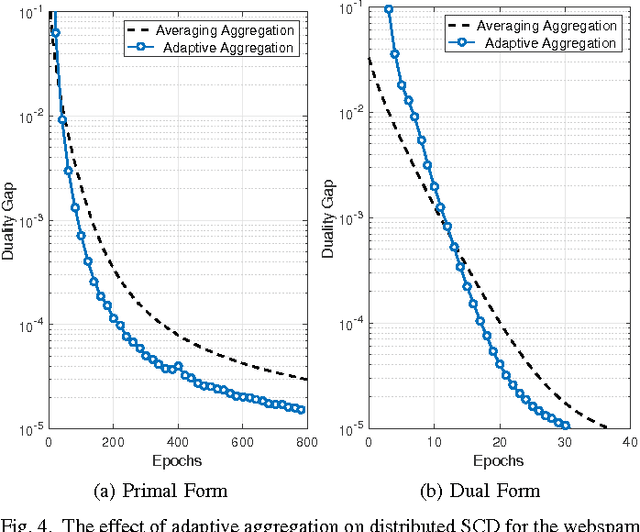
In this work we propose an accelerated stochastic learning system for very large-scale applications. Acceleration is achieved by mapping the training algorithm onto massively parallel processors: we demonstrate a parallel, asynchronous GPU implementation of the widely used stochastic coordinate descent/ascent algorithm that can provide up to 35x speed-up over a sequential CPU implementation. In order to train on very large datasets that do not fit inside the memory of a single GPU, we then consider techniques for distributed stochastic learning. We propose a novel method for optimally aggregating model updates from worker nodes when the training data is distributed either by example or by feature. Using this technique, we demonstrate that one can scale out stochastic learning across up to 8 worker nodes without any significant loss of training time. Finally, we combine GPU acceleration with the optimized distributed method to train on a dataset consisting of 200 million training examples and 75 million features. We show by scaling out across 4 GPUs, one can attain a high degree of training accuracy in around 4 seconds: a 20x speed-up in training time compared to a multi-threaded, distributed implementation across 4 CPUs.