 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Feature Preprocessor: Real-time Extraction of Subgraph-based Features from Transaction Graphs
Feb 13, 2024
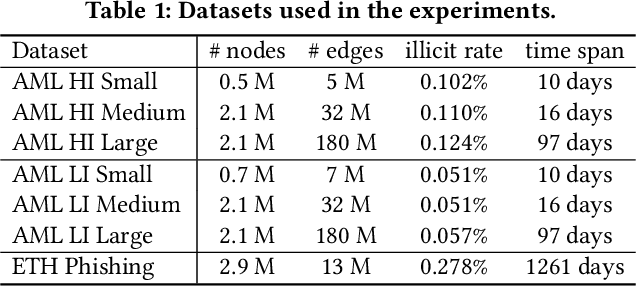


In this paper, we present "Graph Feature Preprocessor", a software library for detecting typical money laundering and fraud patterns in financial transaction graphs in real time. These patterns are used to produce a rich set of transaction features for downstream machine learning training and inference tasks such as money laundering detection. We show that our enriched transaction features dramatically improve the prediction accuracy of gradient-boosting-based machine learning models. Our library exploits multicore parallelism, maintains a dynamic in-memory graph, and efficiently mines subgraph patterns in the incoming transaction stream, which enables it to be operated in a streaming manner. We evaluate our library using highly-imbalanced synthetic anti-money laundering (AML) and real-life Ethereum phishing datasets. In these datasets, the proportion of illicit transactions is very small, which makes the learning process challenging. Our solution, which combines our Graph Feature Preprocessor and gradient-boosting-based machine learning models, is able to detect these illicit transactions with higher minority-class F1 scores than standard graph neural networks. In addition, the end-to-end throughput rate of our solution executed on a multicore CPU outperforms the graph neural network baselines executed on a powerful V100 GPU. Overall, the combination of high accuracy, a high throughput rate, and low latency of our solution demonstrates the practical value of our library in real-world applications. Graph Feature Preprocessor has been integrated into IBM mainframe software products, namely "IBM Cloud Pak for Data on Z" and "AI Toolkit for IBM Z and LinuxONE".
Realistic Synthetic Financial Transactions for Anti-Money Laundering Models
Jun 22, 2023



With the widespread digitization of finance and the increasing popularity of cryptocurrencies, the sophistication of fraud schemes devised by cybercriminals is growing. Money laundering -- the movement of illicit funds to conceal their origins -- can cross bank and national boundaries, producing complex transaction patterns. The UN estimates 2-5\% of global GDP or \$0.8 - \$2.0 trillion dollars are laundered globally each year. Unfortunately, real data to train machine learning models to detect laundering is generally not available, and previous synthetic data generators have had significant shortcomings. A realistic, standardized, publicly-available benchmark is needed for comparing models and for the advancement of the area. To this end, this paper contributes a synthetic financial transaction dataset generator and a set of synthetically generated AML (Anti-Money Laundering) datasets. We have calibrated this agent-based generator to match real transactions as closely as possible and made the datasets public. We describe the generator in detail and demonstrate how the datasets generated can help compare different Graph Neural Networks in terms of their AML abilities. In a key way, using synthetic data in these comparisons can be even better than using real data: the ground truth labels are complete, whilst many laundering transactions in real data are never detected.