 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pairwise Correlations: Higher-Order Redundancies in Self-Supervised Representation Learning
Dec 02, 2024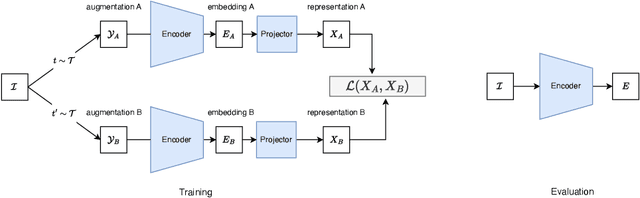
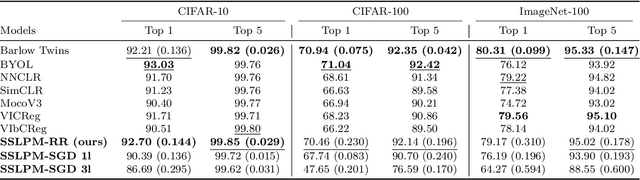
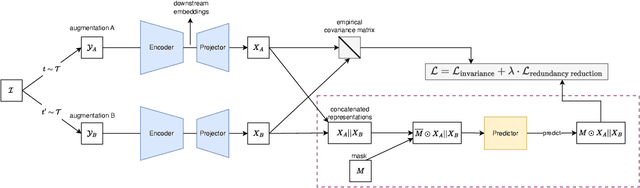

Several self-supervised learning (SSL) approaches have shown that redundancy reduction in the feature embedding space is an effective tool for representation learning. However, these methods consider a narrow notion of redundancy, focusing on pairwise correlations between features. To address this limitation, we formalize the notion of embedding space redundancy and introduce redundancy measures that capture more complex, higher-order dependencies. We mathematically analyze the relationships between these metrics, and empirically measure these redundancies in the embedding spaces of common SSL methods. Based on our findings, we propose Self Supervised Learning with Predictability Minimization (SSLPM) as a method for reducing redundancy in the embedding space. SSLPM combines an encoder network with a predictor engaging in a competitive game of reducing and exploiting dependencies respectively. We demonstrate that SSLPM is competitive with state-of-the-art methods and find that the best performing SSL methods exhibit low embedding space redundancy, suggesting that even methods without explicit redundancy reduction mechanisms perform redundancy reduction implicitly.
Realistic Synthetic Financial Transactions for Anti-Money Laundering Models
Jun 22, 2023



With the widespread digitization of finance and the increasing popularity of cryptocurrencies, the sophistication of fraud schemes devised by cybercriminals is growing. Money laundering -- the movement of illicit funds to conceal their origins -- can cross bank and national boundaries, producing complex transaction patterns. The UN estimates 2-5\% of global GDP or \$0.8 - \$2.0 trillion dollars are laundered globally each year. Unfortunately, real data to train machine learning models to detect laundering is generally not available, and previous synthetic data generators have had significant shortcomings. A realistic, standardized, publicly-available benchmark is needed for comparing models and for the advancement of the area. To this end, this paper contributes a synthetic financial transaction dataset generator and a set of synthetically generated AML (Anti-Money Laundering) datasets. We have calibrated this agent-based generator to match real transactions as closely as possible and made the datasets public. We describe the generator in detail and demonstrate how the datasets generated can help compare different Graph Neural Networks in terms of their AML abilities. In a key way, using synthetic data in these comparisons can be even better than using real data: the ground truth labels are complete, whilst many laundering transactions in real data are never detected.
Provably Powerful Graph Neural Networks for Directed Multigraphs
Jun 20, 2023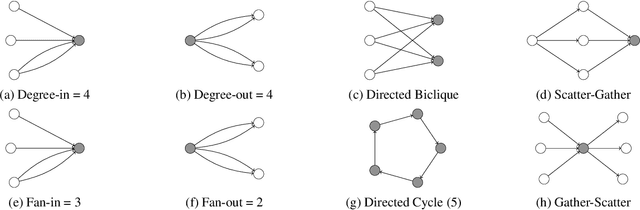
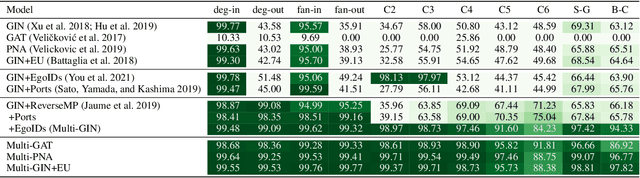
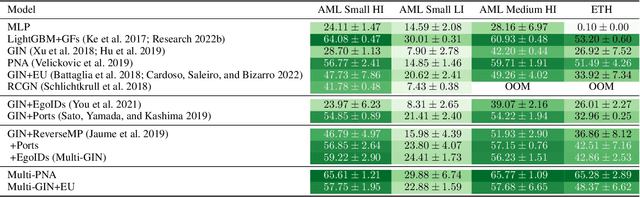
This paper proposes a set of simple adaptations to transform standard message-passing Graph Neural Networks (GNN) into provably powerful directed multigraph neural networks. The adaptations include multigraph port numbering, ego IDs, and reverse message passing. We prove that the combination of these theoretically enables the detection of any directed subgraph pattern. To validate the effectiveness of our proposed adaptations in practice, we conduct experiments on synthetic subgraph detection tasks, which demonstrate outstanding performance with almost perfect results. Moreover, we apply our proposed adaptations to two financial crime analysis tasks. We observe dramatic improvements in detecting money laundering transactions, improving the minority-class F1 score of a standard message-passing GNN by up to 45%, and clearly outperforming tree-based and GNN baselines. Similarly impressive results are observed on a real-world phishing detection dataset, boosting a standard GNN's F1 score by over 15% and outperforming all baselines.
Cascaded Beam Search: Plug-and-Play Terminology-Forcing For Neural Machine Translation
May 23, 2023This paper presents a plug-and-play approach for translation with terminology constraints. Terminology constraints are an important aspect of many modern translation pipelines. In both specialized domains and newly emerging domains (such as the COVID-19 pandemic), accurate translation of technical terms is crucial. Recent approaches often train models to copy terminologies from the input into the output sentence by feeding the target terminology along with the input. But this requires expensive training whenever the underlying language model is changed or the system should specialize to a new domain. We propose Cascade Beam Search, a plug-and-play terminology-forcing approach that requires no training. Cascade Beam Search has two parts: 1) logit manipulation to increase the probability of target terminologies and 2) a cascading beam setup based on grid beam search, where beams are grouped by the number of terminologies they contain. We evaluate the performance of our approach by competing against the top submissions of the WMT21 terminology translation task. Our plug-and-play approach performs on par with the winning submissions without using a domain-specific language model and with no additional training.