 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Pilot: Characterize and Optimize Performance of your LLM Inference Services
Oct 03, 2024



As Large Language Models (LLMs) are rapidly growing in popularity, LLM inference services must be able to serve requests from thousands of users while satisfying performance requirements. The performance of an LLM inference service is largely determined by the hardware onto which it is deployed, but understanding of which hardware will deliver on performance requirements remains challenging. In this work we present LLM-Pilot - a first-of-its-kind system for characterizing and predicting performance of LLM inference services. LLM-Pilot performs benchmarking of LLM inference services, under a realistic workload, across a variety of GPUs, and optimizes the service configuration for each considered GPU to maximize performance. Finally, using this characterization data, LLM-Pilot learns a predictive model, which can be used to recommend the most cost-effective hardware for a previously unseen LLM. Compared to existing methods, LLM-Pilot can deliver on performance requirements 33% more frequently, whilst reducing costs by 60% on average.
Graph Feature Preprocessor: Real-time Extraction of Subgraph-based Features from Transaction Graphs
Feb 13, 2024
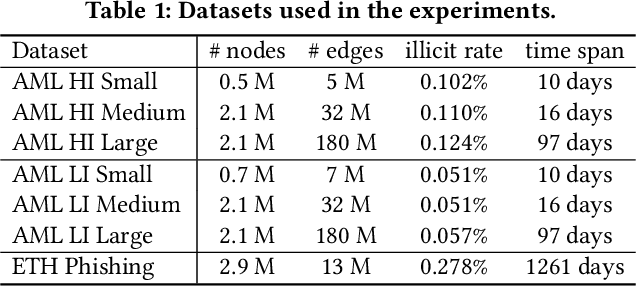


In this paper, we present "Graph Feature Preprocessor", a software library for detecting typical money laundering and fraud patterns in financial transaction graphs in real time. These patterns are used to produce a rich set of transaction features for downstream machine learning training and inference tasks such as money laundering detection. We show that our enriched transaction features dramatically improve the prediction accuracy of gradient-boosting-based machine learning models. Our library exploits multicore parallelism, maintains a dynamic in-memory graph, and efficiently mines subgraph patterns in the incoming transaction stream, which enables it to be operated in a streaming manner. We evaluate our library using highly-imbalanced synthetic anti-money laundering (AML) and real-life Ethereum phishing datasets. In these datasets, the proportion of illicit transactions is very small, which makes the learning process challenging. Our solution, which combines our Graph Feature Preprocessor and gradient-boosting-based machine learning models, is able to detect these illicit transactions with higher minority-class F1 scores than standard graph neural networks. In addition, the end-to-end throughput rate of our solution executed on a multicore CPU outperforms the graph neural network baselines executed on a powerful V100 GPU. Overall, the combination of high accuracy, a high throughput rate, and low latency of our solution demonstrates the practical value of our library in real-world applications. Graph Feature Preprocessor has been integrated into IBM mainframe software products, namely "IBM Cloud Pak for Data on Z" and "AI Toolkit for IBM Z and LinuxONE".
Search-based Methods for Multi-Cloud Configuration
Apr 20, 2022
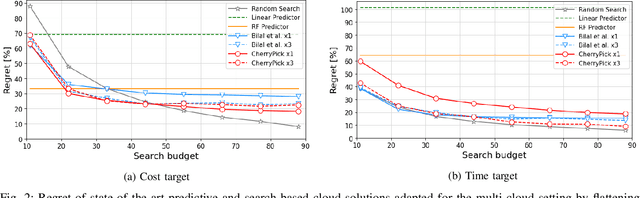
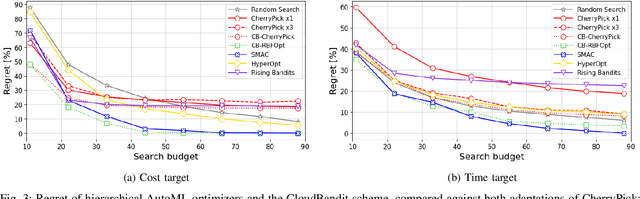
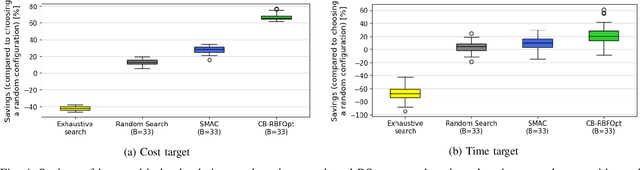
Multi-cloud computing has become increasingly popular with enterprises looking to avoid vendor lock-in. While most cloud providers offer similar functionality, they may differ significantly in terms of performance and/or cost. A customer looking to benefit from such differences will naturally want to solve the multi-cloud configuration problem: given a workload, which cloud provider should be chosen and how should its nodes be configured in order to minimize runtime or cost? In this work, we consider solutions to this optimization problem. We develop and evaluate possible adaptations of state-of-the-art cloud configuration solutions to the multi-cloud domain. Furthermore, we identify an analogy between multi-cloud configuration and the selection-configuration problems commonly studied in the automated machine learning (AutoML) field. Inspired by this connection, we utilize popular optimizers from AutoML to solve multi-cloud configuration. Finally, we propose a new algorithm for solving multi-cloud configuration, CloudBandit (CB). It treats the outer problem of cloud provider selection as a best-arm identification problem, in which each arm pull corresponds to running an arbitrary black-box optimizer on the inner problem of node configuration. Our experiments indicate that (a) many state-of-the-art cloud configuration solutions can be adapted to multi-cloud, with best results obtained for adaptations which utilize the hierarchical structure of the multi-cloud configuration domain, (b) hierarchical methods from AutoML can be used for the multi-cloud configuration task and can outperform state-of-the-art cloud configuration solutions and (c) CB achieves competitive or lower regret relative to other tested algorithms, whilst also identifying configurations that have 65% lower median cost and 20% lower median time in production, compared to choosing a random provider and configuration.
MixBoost: A Heterogeneous Boosting Machine
Jun 17, 2020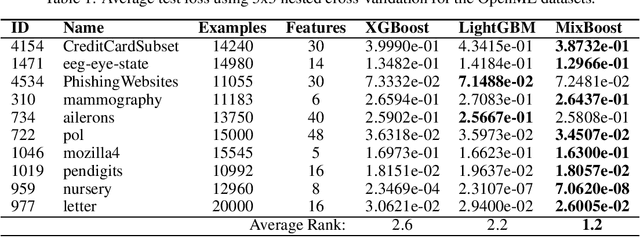
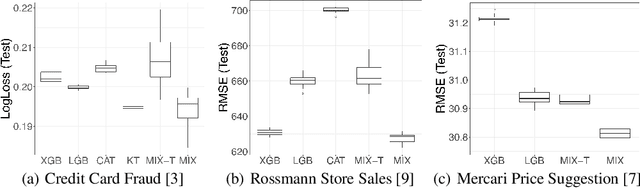
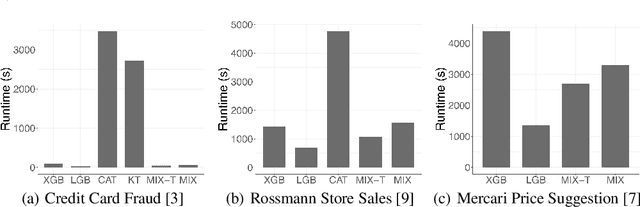

Modern gradient boosting software frameworks, such as XGBoost and LightGBM, implement Newton descent in a functional space. At each boosting iteration, their goal is to find the base hypothesis, selected from some base hypothesis class, that is closest to the Newton descent direction in a Euclidean sense. Typically, the base hypothesis class is fixed to be all binary decision trees up to a given depth. In this work, we study a Heterogeneous Newton Boosting Machine (HNBM) in which the base hypothesis class may vary across boosting iterations. Specifically, at each boosting iteration, the base hypothesis class is chosen, from a fixed set of subclasses, by sampling from a probability distribution. We derive a global linear convergence rate for the HNBM under certain assumptions, and show that it agrees with existing rates for Newton's method when the Newton direction can be perfectly fitted by the base hypothesis at each boosting iteration. We then describe a particular realization of a HNBM, MixBoost, that, at each boosting iteration, randomly selects between either a decision tree of variable depth or a linear regressor with random Fourier features. We describe how MixBoost is implemented, with a focus on the training complexity. Finally, we present experimental results, using OpenML and Kaggle datasets, that show that MixBoost is able to achieve better generalization loss than competing boosting frameworks, without taking significantly longer to tune.
Breadth-first, Depth-next Training of Random Forests
Oct 15, 2019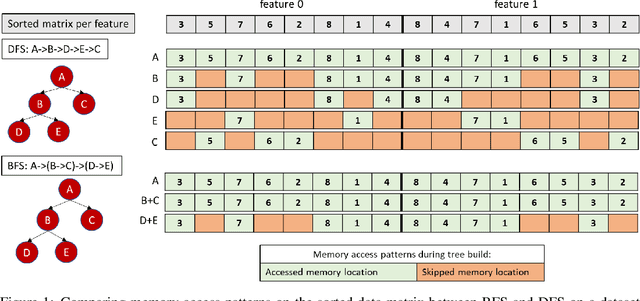
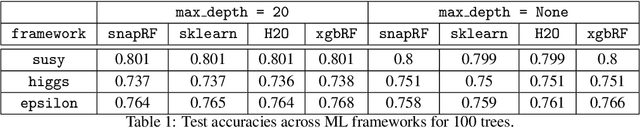
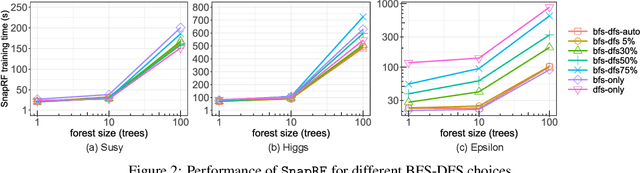
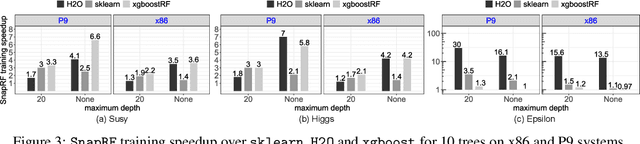
In this paper we analyze, evaluate, and improve the performance of training Random Forest (RF) models on modern CPU architectures. An exact, state-of-the-art binary decision tree building algorithm is used as the basis of this study. Firstly, we investigate the trade-offs between using different tree building algorithms, namely breadth-first-search (BFS) and depth-search-first (DFS). We design a novel, dynamic, hybrid BFS-DFS algorithm and demonstrate that it performs better than both BFS and DFS, and is more robust in the presence of workloads with different characteristics. Secondly, we identify CPU performance bottlenecks when generating trees using this approach, and propose optimizations to alleviate them. The proposed hybrid tree building algorithm for RF is implemented in the Snap Machine Learning framework, and speeds up the training of RFs by 7.8x on average when compared to state-of-the-art RF solvers (sklearn, H2O, and xgboost) on a range of datasets, RF configurations, and multi-core CPU architectures.
Sampling Acquisition Functions for Batch Bayesian Optimization
Mar 22, 2019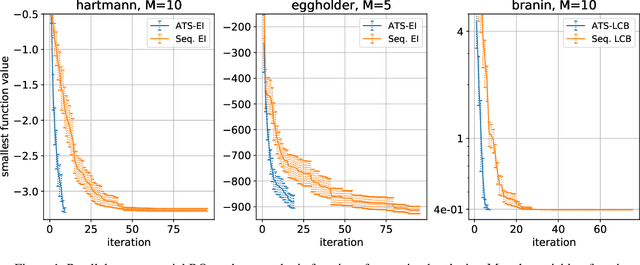
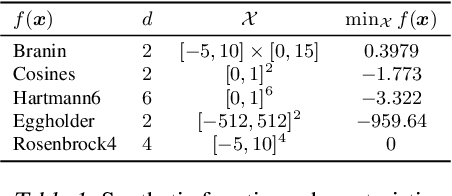
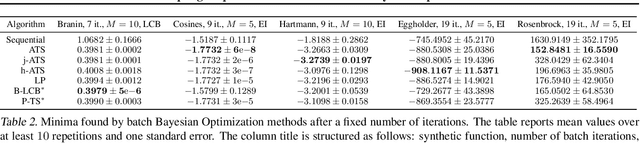
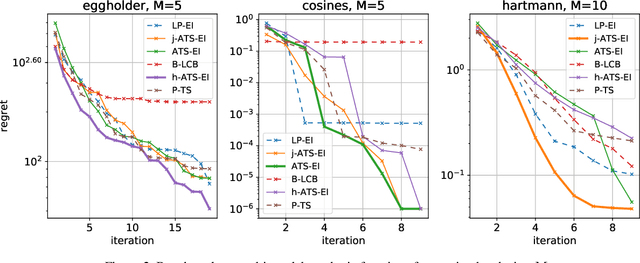
This paper presents Acquisition Thompson Sampling (ATS), a novel algorithm for batch Bayesian Optimization (BO) based on the idea of sampling multiple acquisition functions from a stochastic process. We define this process through the dependency of the acquisition functions on a set of model parameters. ATS is conceptually simple, straightforward to implement and, unlike other batch BO methods, it can be employed to parallelize any sequential acquisition function. In order to improve performance for multi-modal tasks, we show that ATS can be combined with existing techniques in order to realize different explore-exploit trade-offs and take into account pending function evaluations. We present experiments on a variety of benchmark functions and on the hyper-parameter optimization of a popular gradient boosting tree algorithm. These demonstrate the competitiveness of our algorithm with two state-of-the-art batch BO methods, and its advantages to classical parallel Thompson Sampling for BO.
Benchmarking and Optimization of Gradient Boosting Decision Tree Algorithms
Oct 25, 2018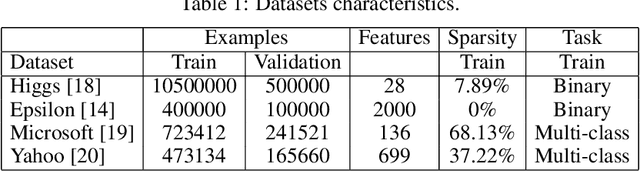
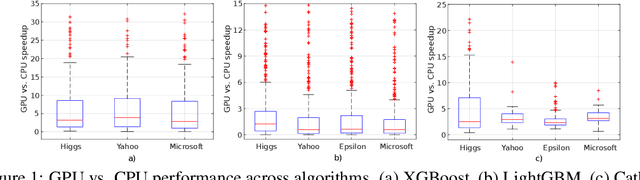
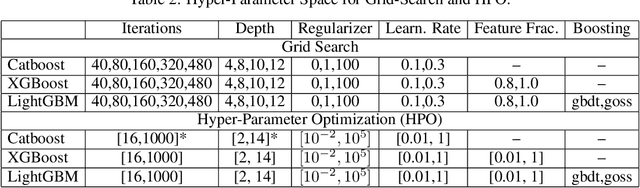
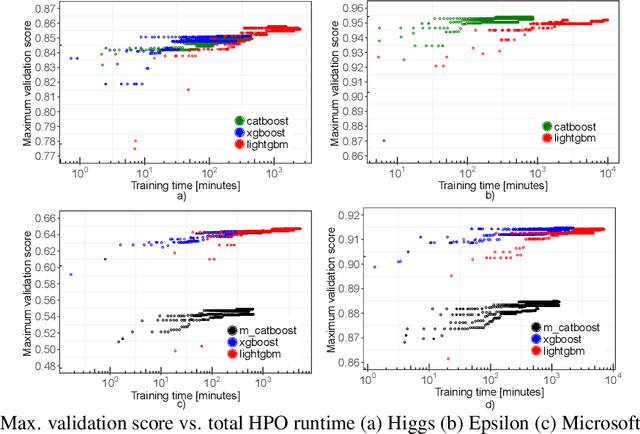
Gradient boosting decision trees (GBDTs) have seen widespread adoption in academia, industry and competitive data science due to their state-of-the-art performance in many machine learning tasks. One relative downside to these models is the large number of hyper-parameters that they expose to the end-user. To maximize the predictive power of GBDT models, one must either manually tune the hyper-parameters, or utilize automated techniques such as those based on Bayesian optimization. Both of these approaches are time-consuming since they involve repeatably training the model for different sets of hyper-parameters. A number of software GBDT packages have started to offer GPU acceleration which can help to alleviate this problem. In this paper, we consider three such packages: XGBoost, LightGBM and Catboost. Firstly, we evaluate the performance of the GPU acceleration provided by these packages using large-scale datasets with varying shapes, sparsities and learning tasks. Then, we compare the packages in the context of hyper-parameter optimization, both in terms of how quickly each package converges to a good validation score, and in terms of generalization performance.
Snap ML: A Hierarchical Framework for Machine Learning
Jun 18, 2018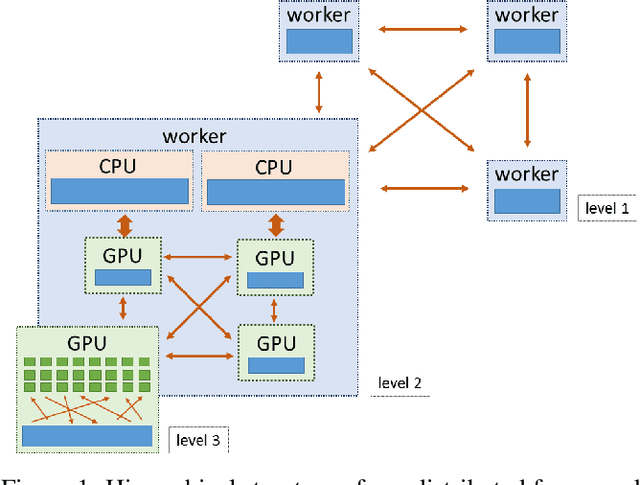

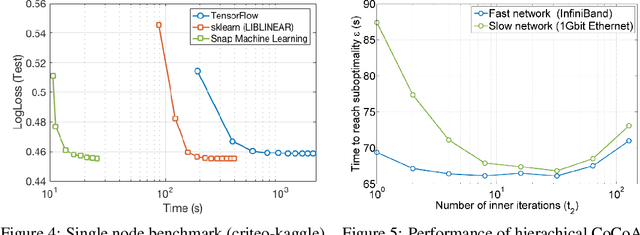
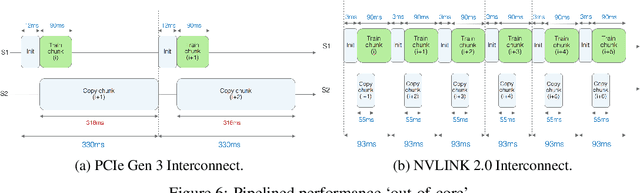
We describe a new software framework for fast training of generalized linear models. The framework, named Snap Machine Learning (Snap ML), combines recent advances in machine learning systems and algorithms in a nested manner to reflect the hierarchical architecture of modern computing systems. We prove theoretically that such a hierarchical system can accelerate training in distributed environments where intra-node communication is cheaper than inter-node communication. Additionally, we provide a review of the implementation of Snap ML in terms of GPU acceleration, pipelining, communication patterns and software architecture, highlighting aspects that were critical for achieving high performance. We evaluate the performance of Snap ML in both single-node and multi-node environments, quantifying the benefit of the hierarchical scheme and the data streaming functionality, and comparing with other widely-used machine learning software frameworks. Finally, we present a logistic regression benchmark on the Criteo Terabyte Click Logs dataset and show that Snap ML achieves the same test loss an order of magnitude faster than any of the previously reported results.