 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Stochastic Coordinate Descent
Jul 10, 2020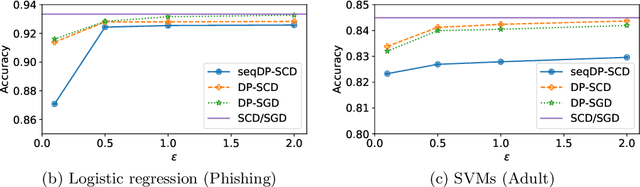

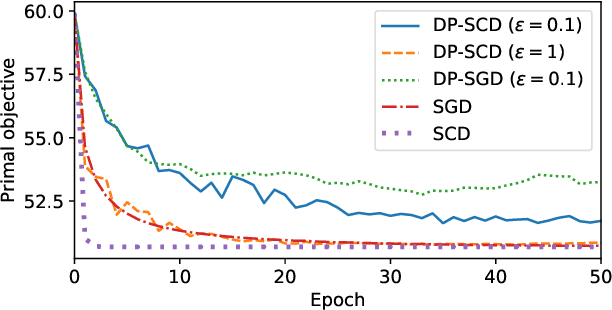
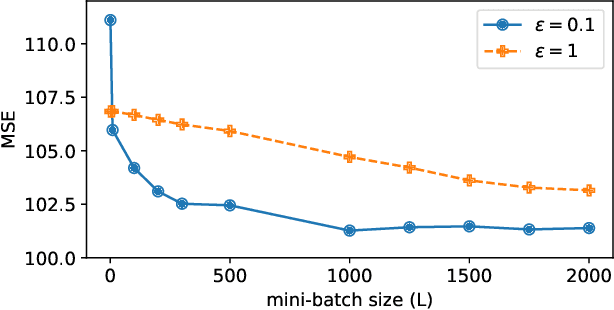
In this paper we tackle the challenge of making the stochastic coordinate descent algorithm differentially private. Compared to the classical gradient descent algorithm where updates operate on a single model vector and controlled noise addition to this vector suffices to hide critical information about individuals, stochastic coordinate descent crucially relies on keeping auxiliary information in memory during training. This auxiliary information provides an additional privacy leak and poses the major challenge addressed in this work. Driven by the insight that under independent noise addition, the consistency of the auxiliary information holds in expectation, we present DP-SCD, the first differentially private stochastic coordinate descent algorithm. We analyze our new method theoretically and argue that decoupling and parallelizing coordinate updates is essential for its utility. On the empirical side we demonstrate competitive performance against the popular stochastic gradient descent alternative (DP-SGD) while requiring significantly less tuning.
MixBoost: A Heterogeneous Boosting Machine
Jun 17, 2020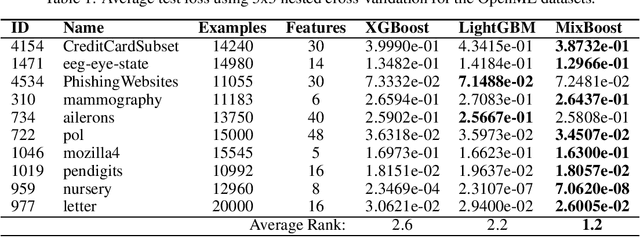
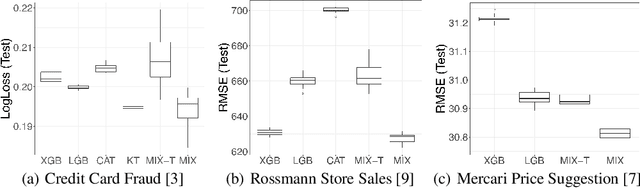
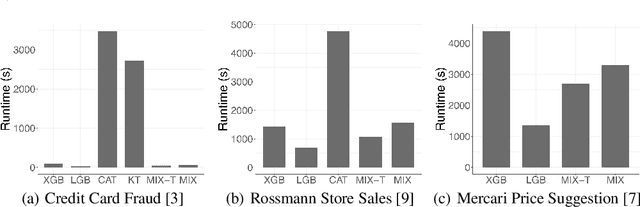

Modern gradient boosting software frameworks, such as XGBoost and LightGBM, implement Newton descent in a functional space. At each boosting iteration, their goal is to find the base hypothesis, selected from some base hypothesis class, that is closest to the Newton descent direction in a Euclidean sense. Typically, the base hypothesis class is fixed to be all binary decision trees up to a given depth. In this work, we study a Heterogeneous Newton Boosting Machine (HNBM) in which the base hypothesis class may vary across boosting iterations. Specifically, at each boosting iteration, the base hypothesis class is chosen, from a fixed set of subclasses, by sampling from a probability distribution. We derive a global linear convergence rate for the HNBM under certain assumptions, and show that it agrees with existing rates for Newton's method when the Newton direction can be perfectly fitted by the base hypothesis at each boosting iteration. We then describe a particular realization of a HNBM, MixBoost, that, at each boosting iteration, randomly selects between either a decision tree of variable depth or a linear regressor with random Fourier features. We describe how MixBoost is implemented, with a focus on the training complexity. Finally, we present experimental results, using OpenML and Kaggle datasets, that show that MixBoost is able to achieve better generalization loss than competing boosting frameworks, without taking significantly longer to tune.
Breadth-first, Depth-next Training of Random Forests
Oct 15, 2019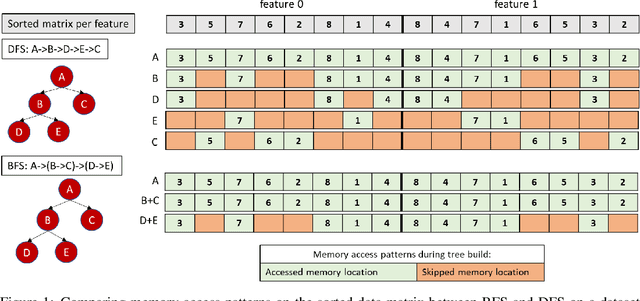
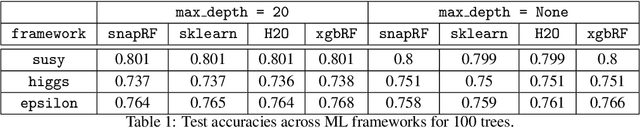
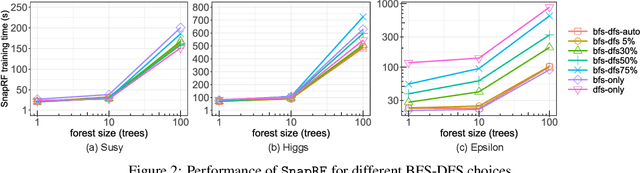
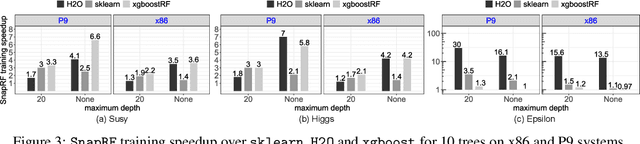
In this paper we analyze, evaluate, and improve the performance of training Random Forest (RF) models on modern CPU architectures. An exact, state-of-the-art binary decision tree building algorithm is used as the basis of this study. Firstly, we investigate the trade-offs between using different tree building algorithms, namely breadth-first-search (BFS) and depth-search-first (DFS). We design a novel, dynamic, hybrid BFS-DFS algorithm and demonstrate that it performs better than both BFS and DFS, and is more robust in the presence of workloads with different characteristics. Secondly, we identify CPU performance bottlenecks when generating trees using this approach, and propose optimizations to alleviate them. The proposed hybrid tree building algorithm for RF is implemented in the Snap Machine Learning framework, and speeds up the training of RFs by 7.8x on average when compared to state-of-the-art RF solvers (sklearn, H2O, and xgboost) on a range of datasets, RF configurations, and multi-core CPU architectures.
Benchmarking and Optimization of Gradient Boosting Decision Tree Algorithms
Oct 25, 2018
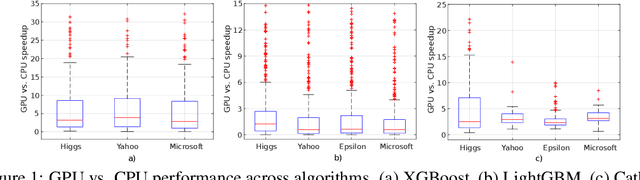
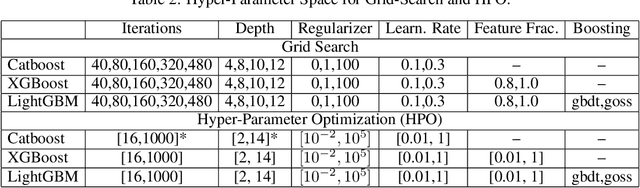
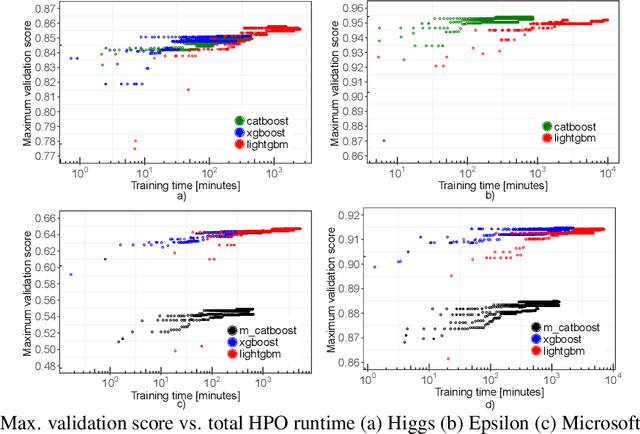
Gradient boosting decision trees (GBDTs) have seen widespread adoption in academia, industry and competitive data science due to their state-of-the-art performance in many machine learning tasks. One relative downside to these models is the large number of hyper-parameters that they expose to the end-user. To maximize the predictive power of GBDT models, one must either manually tune the hyper-parameters, or utilize automated techniques such as those based on Bayesian optimization. Both of these approaches are time-consuming since they involve repeatably training the model for different sets of hyper-parameters. A number of software GBDT packages have started to offer GPU acceleration which can help to alleviate this problem. In this paper, we consider three such packages: XGBoost, LightGBM and Catboost. Firstly, we evaluate the performance of the GPU acceleration provided by these packages using large-scale datasets with varying shapes, sparsities and learning tasks. Then, we compare the packages in the context of hyper-parameter optimization, both in terms of how quickly each package converges to a good validation score, and in terms of generalization performance.