 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Topic Segmentation of Meetings with BERT Embeddings
Jun 24, 2021
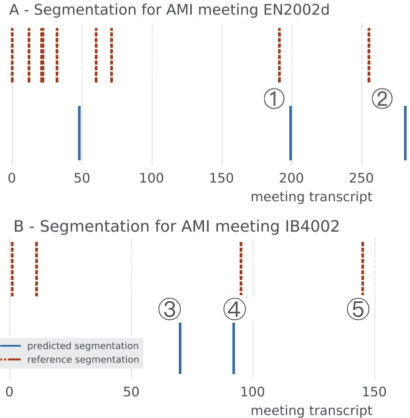
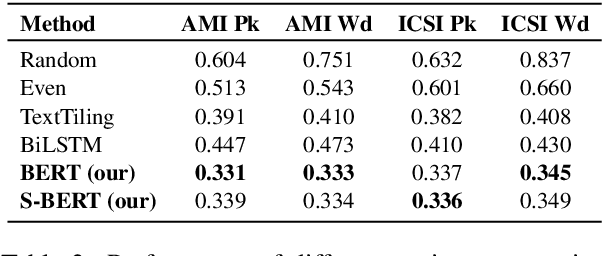
Topic segmentation of meetings is the task of dividing multi-person meeting transcripts into topic blocks. Supervised approaches to the problem have proven intractable due to the difficulties in collecting and accurately annotating large datasets. In this paper we show how previous unsupervised topic segmentation methods can be improved using pre-trained neural architectures. We introduce an unsupervised approach based on BERT embeddings that achieves a 15.5% reduction in error rate over existing unsupervised approaches applied to two popular datasets for meeting transcripts.
Differentially Private Stochastic Coordinate Descent
Jul 10, 2020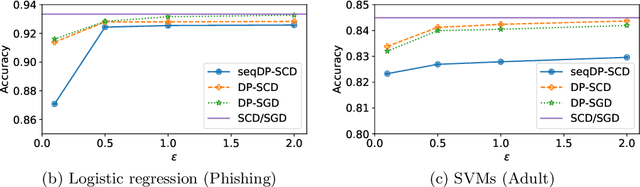

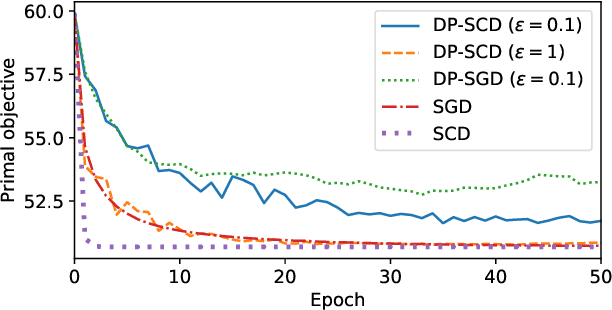
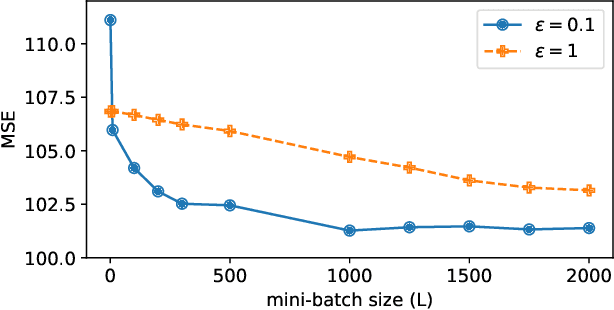
In this paper we tackle the challenge of making the stochastic coordinate descent algorithm differentially private. Compared to the classical gradient descent algorithm where updates operate on a single model vector and controlled noise addition to this vector suffices to hide critical information about individuals, stochastic coordinate descent crucially relies on keeping auxiliary information in memory during training. This auxiliary information provides an additional privacy leak and poses the major challenge addressed in this work. Driven by the insight that under independent noise addition, the consistency of the auxiliary information holds in expectation, we present DP-SCD, the first differentially private stochastic coordinate descent algorithm. We analyze our new method theoretically and argue that decoupling and parallelizing coordinate updates is essential for its utility. On the empirical side we demonstrate competitive performance against the popular stochastic gradient descent alternative (DP-SGD) while requiring significantly less tuning.
FLeet: Online Federated Learning via Staleness Awareness and Performance Prediction
Jun 12, 2020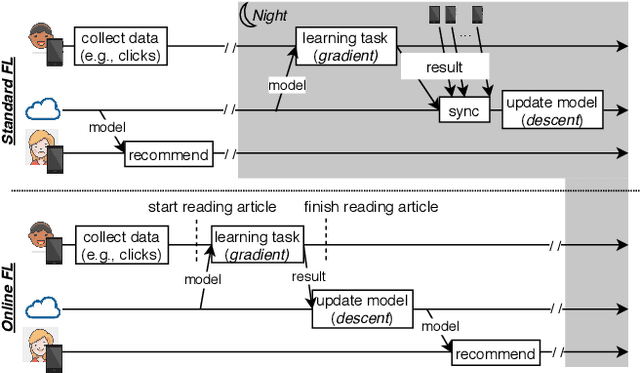
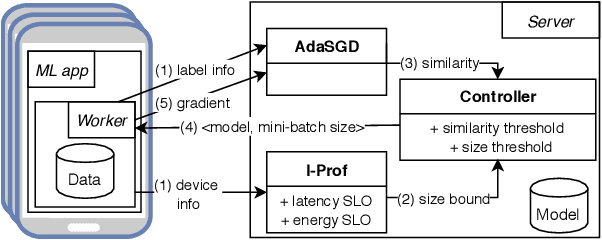
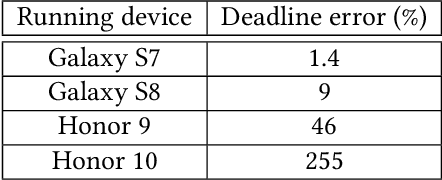
Federated Learning (FL) is very appealing for its privacy benefits: essentially, a global model is trained with updates computed on mobile devices while keeping the data of users local. Standard FL infrastructures are however designed to have no energy or performance impact on mobile devices, and are therefore not suitable for applications that require frequent (online) model updates, such as news recommenders. This paper presents FLeet, the first Online FL system, acting as a middleware between the Android OS and the machine learning application. FLeet combines the privacy of Standard FL with the precision of online learning thanks to two core components: (i) I-Prof, a new lightweight profiler that predicts and controls the impact of learning tasks on mobile devices, and (ii) AdaSGD, a new adaptive learning algorithm that is resilient to delayed updates. Our extensive evaluation shows that Online FL, as implemented by FLeet, can deliver a 2.3x quality boost compared to Standard FL, while only consuming 0.036% of the battery per day. I-Prof can accurately control the impact of learning tasks by improving the prediction accuracy up to 3.6x (computation time) and up to 19x (energy). AdaSGD outperforms alternative FL approaches by 18.4% in terms of convergence speed on heterogeneous data.
Asynchronous Byzantine Machine Learning (the case of SGD)
Jul 09, 2018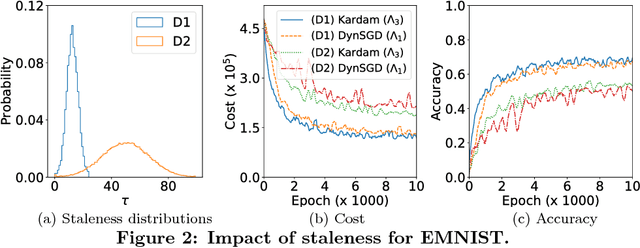
Asynchronous distributed machine learning solutions have proven very effective so far, but always assuming perfectly functioning workers. In practice, some of the workers can however exhibit Byzantine behavior, caused by hardware failures, software bugs, corrupt data, or even malicious attacks. We introduce \emph{Kardam}, the first distributed asynchronous stochastic gradient descent (SGD) algorithm that copes with Byzantine workers. Kardam consists of two complementary components: a filtering and a dampening component. The first is scalar-based and ensures resilience against $\frac{1}{3}$ Byzantine workers. Essentially, this filter leverages the Lipschitzness of cost functions and acts as a self-stabilizer against Byzantine workers that would attempt to corrupt the progress of SGD. The dampening component bounds the convergence rate by adjusting to stale information through a generic gradient weighting scheme. We prove that Kardam guarantees almost sure convergence in the presence of asynchrony and Byzantine behavior, and we derive its convergence rate. We evaluate Kardam on the CIFAR-100 and EMNIST datasets and measure its overhead with respect to non Byzantine-resilient solutions. We empirically show that Kardam does not introduce additional noise to the learning procedure but does induce a slowdown (the cost of Byzantine resilience) that we both theoretically and empirically show to be less than $f/n$, where $f$ is the number of Byzantine failures tolerated and $n$ the total number of workers. Interestingly, we also empirically observe that the dampening component is interesting in its own right for it enables to build an SGD algorithm that outperforms alternative staleness-aware asynchronous competitors in environments with honest workers.