 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Topic Segmentation of Meetings with BERT Embeddings
Jun 24, 2021
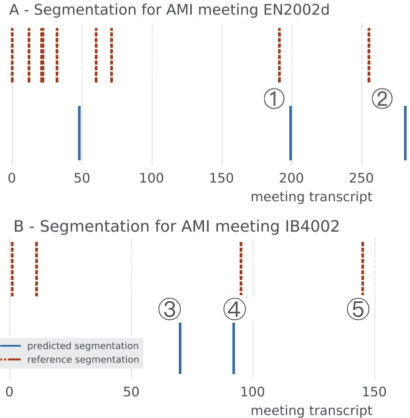
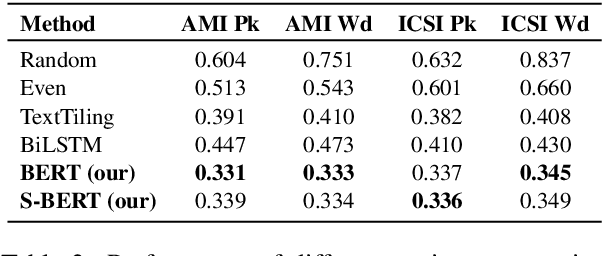
Topic segmentation of meetings is the task of dividing multi-person meeting transcripts into topic blocks. Supervised approaches to the problem have proven intractable due to the difficulties in collecting and accurately annotating large datasets. In this paper we show how previous unsupervised topic segmentation methods can be improved using pre-trained neural architectures. We introduce an unsupervised approach based on BERT embeddings that achieves a 15.5% reduction in error rate over existing unsupervised approaches applied to two popular datasets for meeting transcripts.
Jointly Aligning Millions of Images with Deep Penalised Reconstruction Congealing
Aug 12, 2019
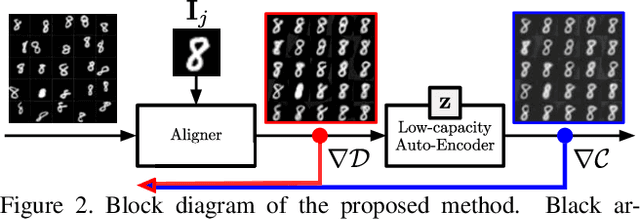
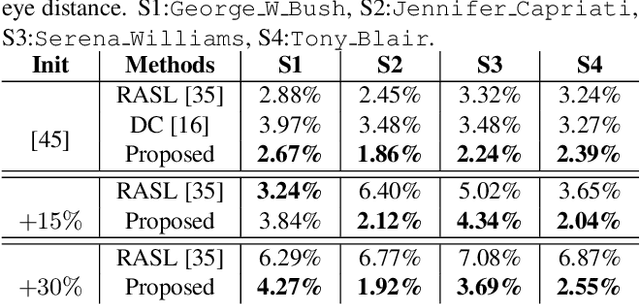
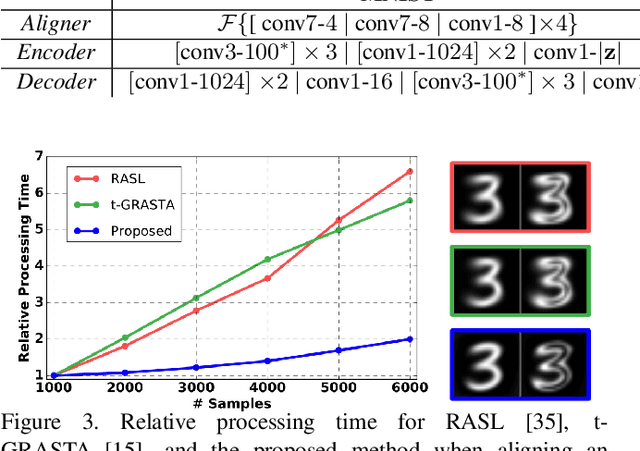
Extrapolating fine-grained pixel-level correspondences in a fully unsupervised manner from a large set of misaligned images can benefit several computer vision and graphics problems, e.g. co-segmentation, super-resolution, image edit propagation, structure-from-motion, and 3D reconstruction. Several joint image alignment and congealing techniques have been proposed to tackle this problem, but robustness to initialisation, ability to scale to large datasets, and alignment accuracy seem to hamper their wide applicability. To overcome these limitations, we propose an unsupervised joint alignment method leveraging a densely fused spatial transformer network to estimate the warping parameters for each image and a low-capacity auto-encoder whose reconstruction error is used as an auxiliary measure of joint alignment. Experimental results on digits from multiple versions of MNIST (i.e., original, perturbed, affNIST and infiMNIST) and faces from LFW, show that our approach is capable of aligning millions of images with high accuracy and robustness to different levels and types of perturbation. Moreover, qualitative and quantitative results suggest that the proposed method outperforms state-of-the-art approaches both in terms of alignment quality and robustness to initialisation.
SCRAM: Spatially Coherent Randomized Attention Maps
May 24, 2019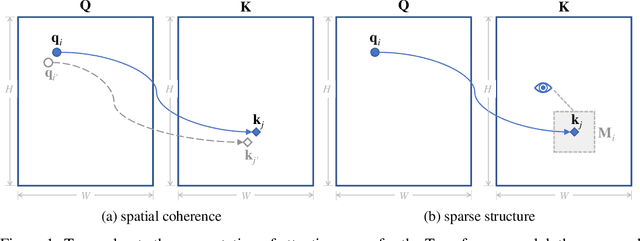
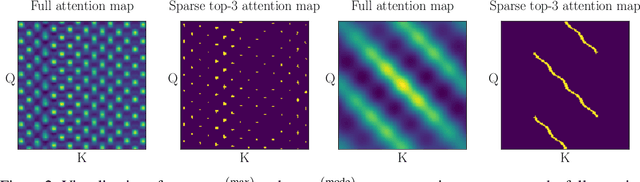
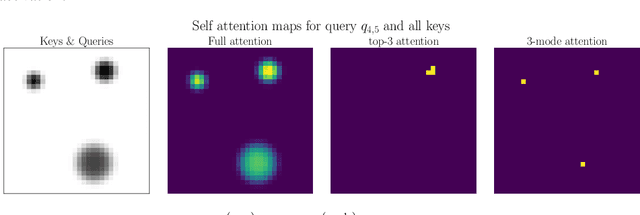
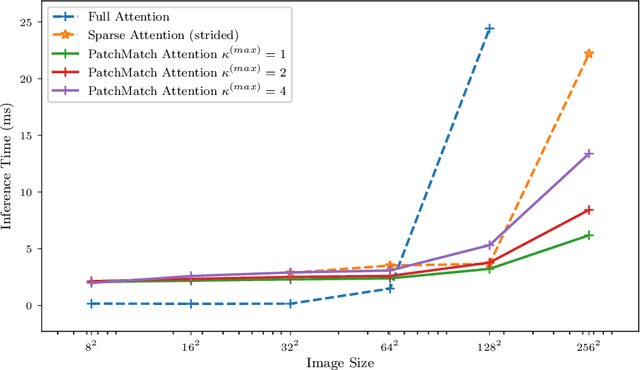
Attention mechanisms and non-local mean operations in general are key ingredients in many state-of-the-art deep learning techniques. In particular, the Transformer model based on multi-head self-attention has recently achieved great success in natural language processing and computer vision. However, the vanilla algorithm computing the Transformer of an image with n pixels has O(n^2) complexity, which is often painfully slow and sometimes prohibitively expensive for large-scale image data. In this paper, we propose a fast randomized algorithm --- SCRAM --- that only requires O(n log(n)) time to produce an image attention map. Such a dramatic acceleration is attributed to our insight that attention maps on real-world images usually exhibit (1) spatial coherence and (2) sparse structure. The central idea of SCRAM is to employ PatchMatch, a randomized correspondence algorithm, to quickly pinpoint the most compatible key (argmax) for each query first, and then exploit that knowledge to design a sparse approximation to non-local mean operations. Using the argmax (mode) to dynamically construct the sparse approximation distinguishes our algorithm from all of the existing sparse approximate methods and makes it very efficient. Moreover, SCRAM is a broadly applicable approximation to any non-local mean layer in contrast to some other sparse approximations that can only approximate self-attention. Our preliminary experimental results suggest that SCRAM is indeed promising for speeding up or scaling up the computation of attention maps in the Transformer.