 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Aligning Millions of Images with Deep Penalised Reconstruction Congealing
Aug 12, 2019
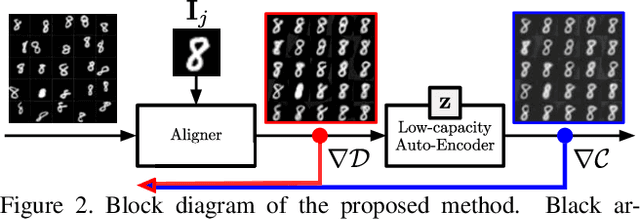
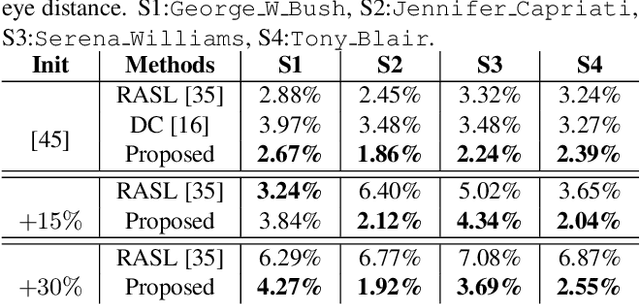
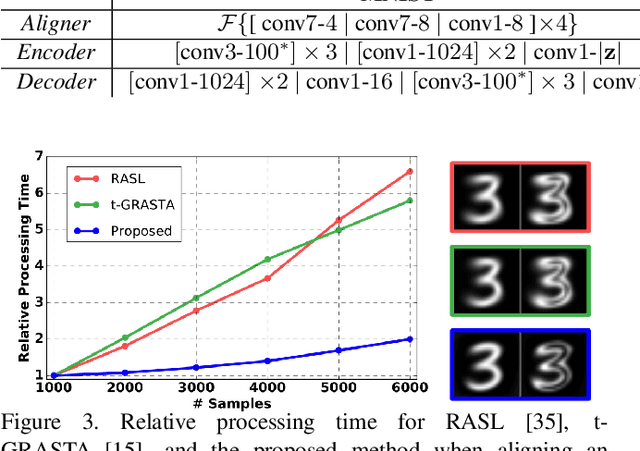
Extrapolating fine-grained pixel-level correspondences in a fully unsupervised manner from a large set of misaligned images can benefit several computer vision and graphics problems, e.g. co-segmentation, super-resolution, image edit propagation, structure-from-motion, and 3D reconstruction. Several joint image alignment and congealing techniques have been proposed to tackle this problem, but robustness to initialisation, ability to scale to large datasets, and alignment accuracy seem to hamper their wide applicability. To overcome these limitations, we propose an unsupervised joint alignment method leveraging a densely fused spatial transformer network to estimate the warping parameters for each image and a low-capacity auto-encoder whose reconstruction error is used as an auxiliary measure of joint alignment. Experimental results on digits from multiple versions of MNIST (i.e., original, perturbed, affNIST and infiMNIST) and faces from LFW, show that our approach is capable of aligning millions of images with high accuracy and robustness to different levels and types of perturbation. Moreover, qualitative and quantitative results suggest that the proposed method outperforms state-of-the-art approaches both in terms of alignment quality and robustness to initialisation.
DeSTNet: Densely Fused Spatial Transformer Networks
Jul 16, 2018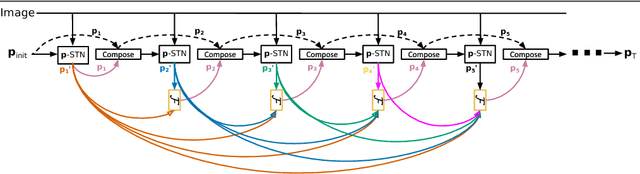



Modern Convolutional Neural Networks (CNN) are extremely powerful on a range of computer vision tasks. However, their performance may degrade when the data is characterised by large intra-class variability caused by spatial transformations. The Spatial Transformer Network (STN) is currently the method of choice for providing CNNs the ability to remove those transformations and improve performance in an end-to-end learning framework. In this paper, we propose Densely Fused Spatial Transformer Network (DeSTNet), which, to our best knowledge, is the first dense fusion pattern for combining multiple STNs. Specifically, we show how changing the connectivity pattern of multiple STNs from sequential to dense leads to more powerful alignment modules. Extensive experiments on three benchmarks namely, MNIST, GTSRB, and IDocDB show that the proposed technique outperforms related state-of-the-art methods (i.e., STNs and CSTNs) both in terms of accuracy and robustness.
Face frontalization for Alignment and Recognition
Feb 03, 2015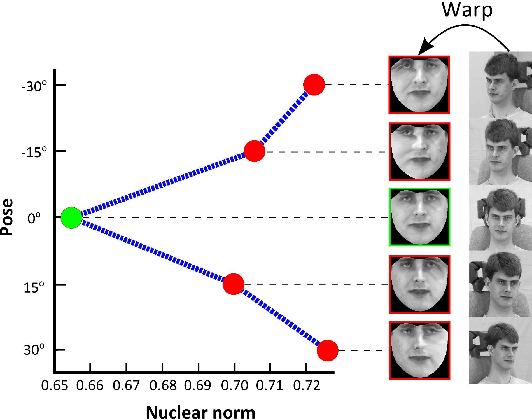



Recently, it was shown that excellent results can be achieved in both face landmark localization and pose-invariant face recognition. These breakthroughs are attributed to the efforts of the community to manually annotate facial images in many different poses and to collect 3D faces data. In this paper, we propose a novel method for joint face landmark localization and frontal face reconstruction (pose correction) using a small set of frontal images only. By observing that the frontal facial image is the one with the minimum rank from all different poses we formulate an appropriate model which is able to jointly recover the facial landmarks as well as the frontalized version of the face. To this end, a suitable optimization problem, involving the minimization of the nuclear norm and the matrix $\ell_1$ norm, is solved. The proposed method is assessed in frontal face reconstruction (pose correction), face landmark localization, and pose-invariant face recognition and verification by conducting experiments on $6$ facial images databases. The experimental results demonstrate the effectiveness of the proposed method.