 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnilingual MT: Machine Translation for 1,600 Languages
Mar 17, 2026High-quality machine translation (MT) can scale to hundreds of languages, setting a high bar for multilingual systems. However, compared to the world's 7,000 languages, current systems still offer only limited coverage: about 200 languages on the target side, and maybe a few hundreds more on the source side, supported due to cross-lingual transfer. And even these numbers have been hard to evaluate due to the lack of reliable benchmarks and metrics. We present Omnilingual Machine Translation (OMT), the first MT system supporting more than 1,600 languages. This scale is enabled by a comprehensive data strategy that integrates large public multilingual corpora with newly created datasets, including manually curated MeDLEY bitext. We explore two ways of specializing a Large Language model (LLM) for machine translation: as a decoder-only model (OMT-LLaMA) or as a module in an encoder-decoder architecture (OMT-NLLB). Notably, all our 1B to 8B parameter models match or exceed the MT performance of a 70B LLM baseline, revealing a clear specialization advantage and enabling strong translation quality in low-compute settings. Moreover, our evaluation of English-to-1,600 translations further shows that while baseline models can interpret undersupported languages, they frequently fail to generate them with meaningful fidelity; OMT-LLaMA models substantially expand the set of languages for which coherent generation is feasible. Additionally, OMT models improve in cross-lingual transfer, being close to solving the "understanding" part of the puzzle in MT for the 1,600 evaluated. Our leaderboard and main human-created evaluation datasets (BOUQuET and Met-BOUQuET) are dynamically evolving towards Omnilinguality and freely available.
Omnilingual SONAR: Cross-Lingual and Cross-Modal Sentence Embeddings Bridging Massively Multilingual Text and Speech
Mar 17, 2026Cross-lingual sentence encoders typically cover only a few hundred languages and often trade downstream quality for stronger alignment, limiting their adoption. We introduce OmniSONAR, a new family of omnilingual, cross-lingual and cross-modal sentence embedding models that natively embed text, speech, code, and mathematical expressions in a single semantic space, while delivering state-of-the-art downstream performance at the scale of thousands of languages, from high-resource to extremely low-resource varieties. To reach this scale without representation collapse, we use progressive training. We first learn a strong foundational space for 200 languages with an LLM-initialized encoder-decoder, combining token-level decoding with a novel split-softmax contrastive loss and synthetic hard negatives. Building on this foundation, we expand to several thousands language varieties via a two-stage teacher-student encoder distillation framework. Finally, we demonstrate the cross-modal extensibility of this space by seamlessly mapping 177 spoken languages into it. OmniSONAR halves cross-lingual similarity search error on the 200-language FLORES dataset and reduces error by a factor of 15 on the 1,560-language BIBLE benchmark. It also enables strong translation, outperforming NLLB-3B on multilingual benchmarks and exceeding prior models (including much larger LLMs) by 15 chrF++ points on 1,560 languages into English BIBLE translation. OmniSONAR also performs strongly on MTEB and XLCoST. For speech, OmniSONAR achieves a 43% lower similarity-search error and reaches 97% of SeamlessM4T speech-to-text quality, despite being zero-shot for translation (trained only on ASR data). Finally, by training an encoder-decoder LM, Spectrum, exclusively on English text processing OmniSONAR embedding sequences, we unlock high-performance transfer to thousands of languages and speech for complex downstream tasks.
Large Concept Models: Language Modeling in a Sentence Representation Space
Dec 11, 2024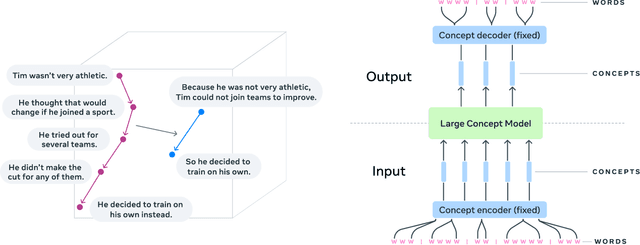
LLMs have revolutionized the field of artificial intelligence and have emerged as the de-facto tool for many tasks. The current established technology of LLMs is to process input and generate output at the token level. This is in sharp contrast to humans who operate at multiple levels of abstraction, well beyond single words, to analyze information and to generate creative content. In this paper, we present an attempt at an architecture which operates on an explicit higher-level semantic representation, which we name a concept. Concepts are language- and modality-agnostic and represent a higher level idea or action in a flow. Hence, we build a "Large Concept Model". In this study, as proof of feasibility, we assume that a concept corresponds to a sentence, and use an existing sentence embedding space, SONAR, which supports up to 200 languages in both text and speech modalities. The Large Concept Model is trained to perform autoregressive sentence prediction in an embedding space. We explore multiple approaches, namely MSE regression, variants of diffusion-based generation, and models operating in a quantized SONAR space. These explorations are performed using 1.6B parameter models and training data in the order of 1.3T tokens. We then scale one architecture to a model size of 7B parameters and training data of about 2.7T tokens. We perform an experimental evaluation on several generative tasks, namely summarization and a new task of summary expansion. Finally, we show that our model exhibits impressive zero-shot generalization performance to many languages, outperforming existing LLMs of the same size. The training code of our models is freely available.
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



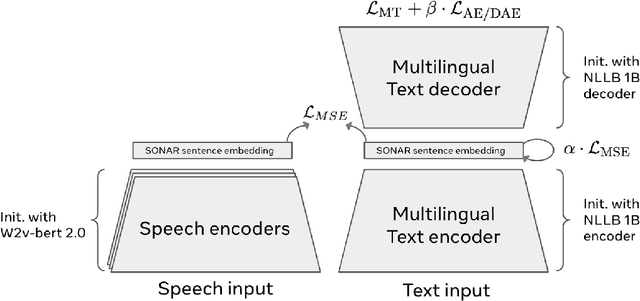
What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
xSIM++: An Improved Proxy to Bitext Mining Performance for Low-Resource Languages
Jun 22, 2023
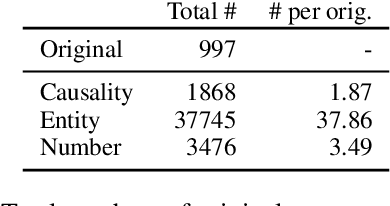

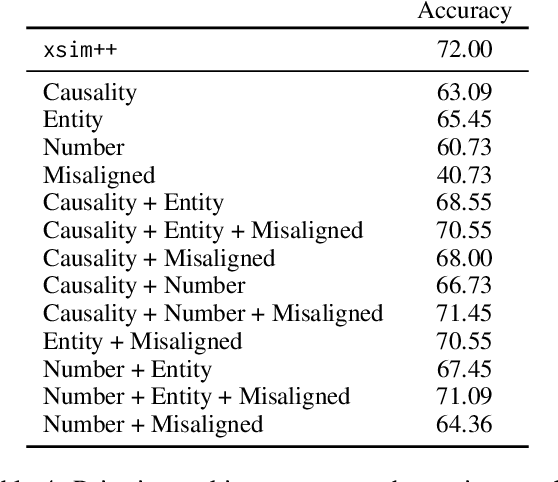
We introduce a new proxy score for evaluating bitext mining based on similarity in a multilingual embedding space: xSIM++. In comparison to xSIM, this improved proxy leverages rule-based approaches to extend English sentences in any evaluation set with synthetic, hard-to-distinguish examples which more closely mirror the scenarios we encounter during large-scale mining. We validate this proxy by running a significant number of bitext mining experiments for a set of low-resource languages, and subsequently train NMT systems on the mined data. In comparison to xSIM, we show that xSIM++ is better correlated with the downstream BLEU scores of translation systems trained on mined bitexts, providing a reliable proxy of bitext mining performance without needing to run expensive bitext mining pipelines. xSIM++ also reports performance for different error types, offering more fine-grained feedback for model development.
Multilingual Representation Distillation with Contrastive Learning
Oct 10, 2022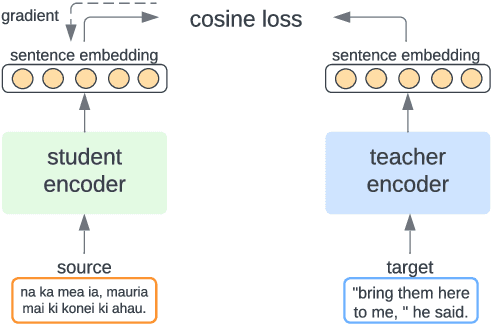

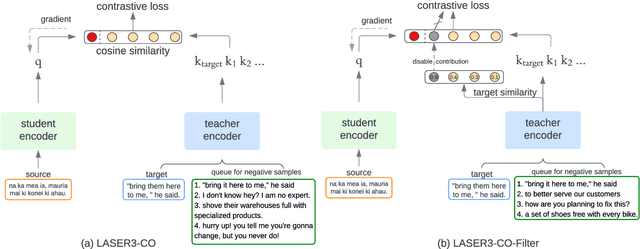
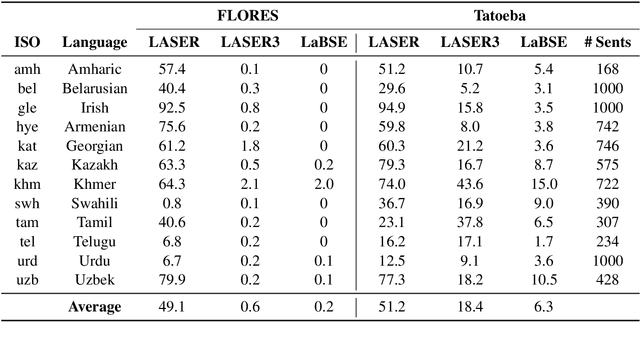
Multilingual sentence representations from large models can encode semantic information from two or more languages and can be used for different cross-lingual information retrieval tasks. In this paper, we integrate contrastive learning into multilingual representation distillation and use it for quality estimation of parallel sentences (find semantically similar sentences that can be used as translations of each other). We validate our approach with multilingual similarity search and corpus filtering tasks. Experiments across different low-resource languages show that our method significantly outperforms previous sentence encoders such as LASER, LASER3, and LaBSE.
No Language Left Behind: Scaling Human-Centered Machine Translation
Jul 11, 2022
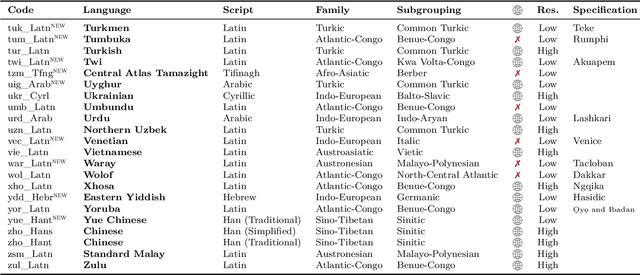
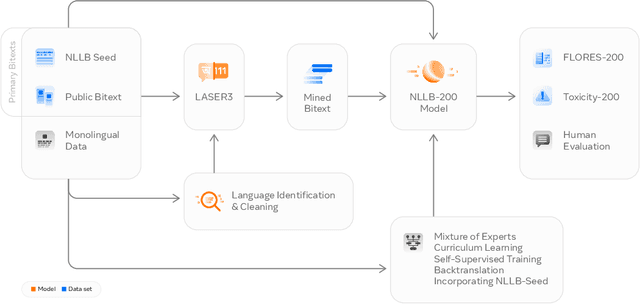
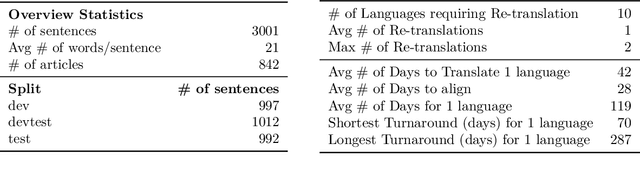
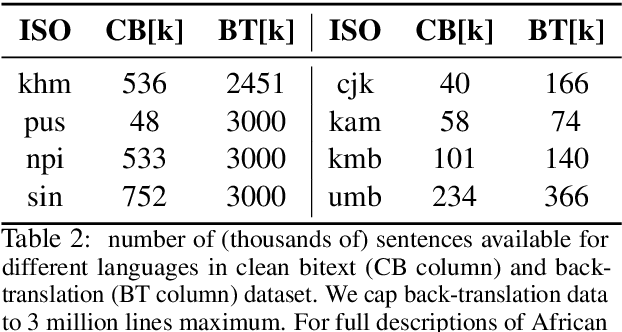
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system. Finally, we open source all contributions described in this work, accessible at https://github.com/facebookresearch/fairseq/tree/nllb.
Bitext Mining Using Distilled Sentence Representations for Low-Resource Languages
May 25, 2022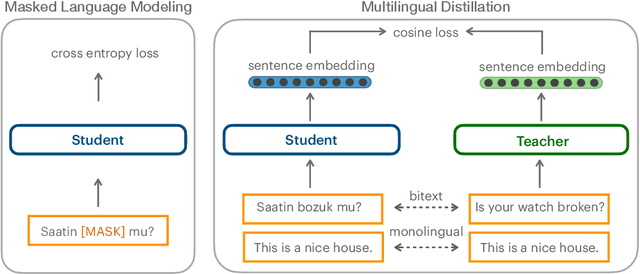
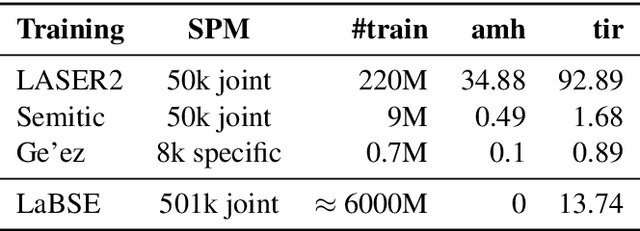

Scaling multilingual representation learning beyond the hundred most frequent languages is challenging, in particular to cover the long tail of low-resource languages. A promising approach has been to train one-for-all multilingual models capable of cross-lingual transfer, but these models often suffer from insufficient capacity and interference between unrelated languages. Instead, we move away from this approach and focus on training multiple language (family) specific representations, but most prominently enable all languages to still be encoded in the same representational space. To achieve this, we focus on teacher-student training, allowing all encoders to be mutually compatible for bitext mining, and enabling fast learning of new languages. We introduce a new teacher-student training scheme which combines supervised and self-supervised training, allowing encoders to take advantage of monolingual training data, which is valuable in the low-resource setting. Our approach significantly outperforms the original LASER encoder. We study very low-resource languages and handle 50 African languages, many of which are not covered by any other model. For these languages, we train sentence encoders, mine bitexts, and validate the bitexts by training NMT systems.
Unsupervised Topic Segmentation of Meetings with BERT Embeddings
Jun 24, 2021
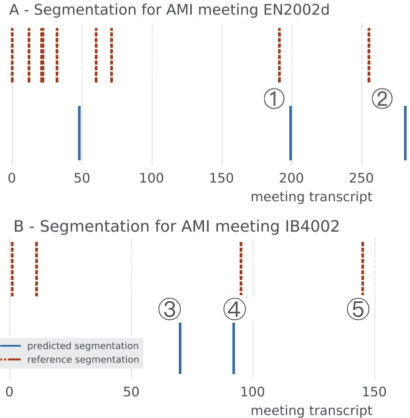
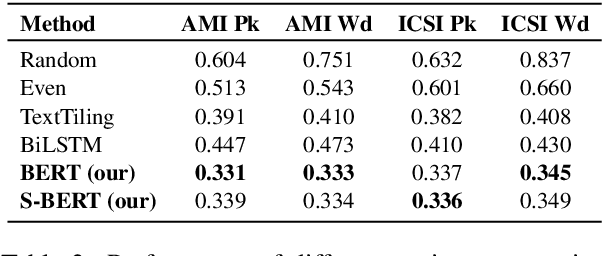
Topic segmentation of meetings is the task of dividing multi-person meeting transcripts into topic blocks. Supervised approaches to the problem have proven intractable due to the difficulties in collecting and accurately annotating large datasets. In this paper we show how previous unsupervised topic segmentation methods can be improved using pre-trained neural architectures. We introduce an unsupervised approach based on BERT embeddings that achieves a 15.5% reduction in error rate over existing unsupervised approaches applied to two popular datasets for meeting transcripts.