 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagic Words or Methodical Work? Challenging Conventional Wisdom in LLM-Based Political Text Annotation
Mar 31, 2026Political scientists are rapidly adopting large language models (LLMs) for text annotation, yet the sensitivity of annotation results to implementation choices remains poorly understood. Most evaluations test a single model or configuration; how model choice, model size, learning approach, and prompt style interact, and whether popular "best practices" survive controlled comparison, are largely unexplored. We present a controlled evaluation of these pipeline choices, testing six open-weight models across four political science annotation tasks under identical quantisation, hardware, and prompt-template conditions. Our central finding is methodological: interaction effects dominate main effects, so seemingly reasonable pipeline choices can become consequential researcher degrees of freedom. No single model, prompt style, or learning approach is uniformly superior, and the best-performing model varies across tasks. Two corollaries follow. First, model size is an unreliable guide both to cost and to performance: cross-family efficiency differences are so large that some larger models are less resource-intensive than much smaller alternatives, while within model families mid-range variants often match or exceed larger counterparts. Second, widely recommended prompt engineering techniques yield inconsistent and sometimes negative effects on annotation performance. We use these benchmark results to develop a validation-first framework - with a principled ordering of pipeline decisions, guidance on prompt freezing and held-out evaluation, reporting standards, and open-source tools - to help researchers navigate this decision space transparently.
Efficiently Upgrading Multilingual Machine Translation Models to Support More Languages
Feb 07, 2023



With multilingual machine translation (MMT) models continuing to grow in size and number of supported languages, it is natural to reuse and upgrade existing models to save computation as data becomes available in more languages. However, adding new languages requires updating the vocabulary, which complicates the reuse of embeddings. The question of how to reuse existing models while also making architectural changes to provide capacity for both old and new languages has also not been closely studied. In this work, we introduce three techniques that help speed up effective learning of the new languages and alleviate catastrophic forgetting despite vocabulary and architecture mismatches. Our results show that by (1) carefully initializing the network, (2) applying learning rate scaling, and (3) performing data up-sampling, it is possible to exceed the performance of a same-sized baseline model with 30% computation and recover the performance of a larger model trained from scratch with over 50% reduction in computation. Furthermore, our analysis reveals that the introduced techniques help learn the new directions more effectively and alleviate catastrophic forgetting at the same time. We hope our work will guide research into more efficient approaches to growing languages for these MMT models and ultimately maximize the reuse of existing models.
No Language Left Behind: Scaling Human-Centered Machine Translation
Jul 11, 2022
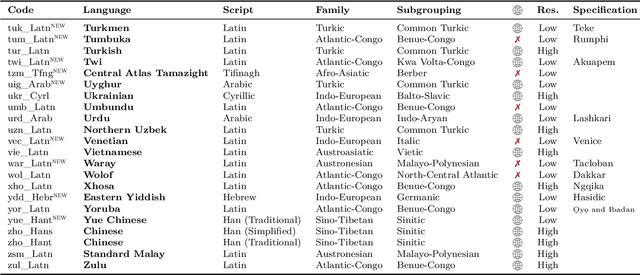
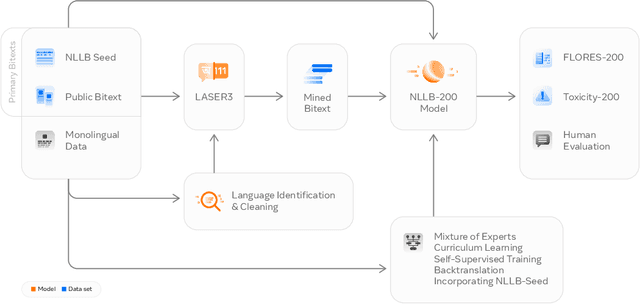
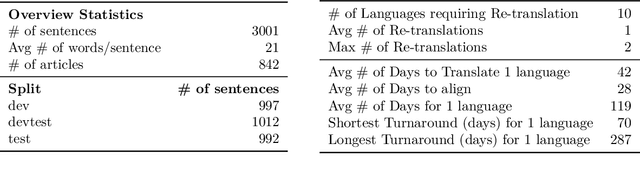
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system. Finally, we open source all contributions described in this work, accessible at https://github.com/facebookresearch/fairseq/tree/nllb.
Multilingual Neural Machine Translation with Deep Encoder and Multiple Shallow Decoders
Jun 05, 2022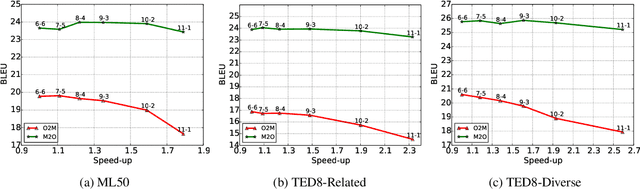

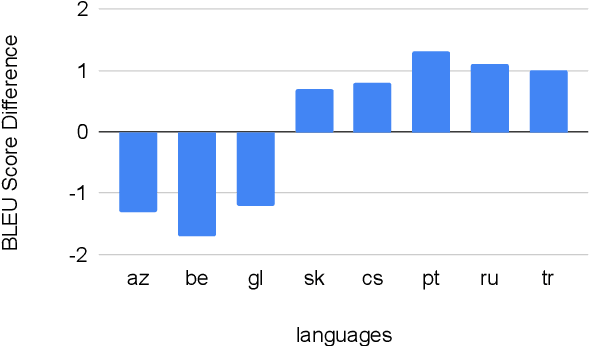
Recent work in multilingual translation advances translation quality surpassing bilingual baselines using deep transformer models with increased capacity. However, the extra latency and memory costs introduced by this approach may make it unacceptable for efficiency-constrained applications. It has recently been shown for bilingual translation that using a deep encoder and shallow decoder (DESD) can reduce inference latency while maintaining translation quality, so we study similar speed-accuracy trade-offs for multilingual translation. We find that for many-to-one translation we can indeed increase decoder speed without sacrificing quality using this approach, but for one-to-many translation, shallow decoders cause a clear quality drop. To ameliorate this drop, we propose a deep encoder with multiple shallow decoders (DEMSD) where each shallow decoder is responsible for a disjoint subset of target languages. Specifically, the DEMSD model with 2-layer decoders is able to obtain a 1.8x speedup on average compared to a standard transformer model with no drop in translation quality.
Multilingual Machine Translation with Hyper-Adapters
May 22, 2022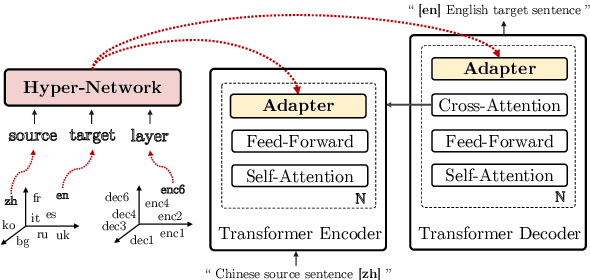
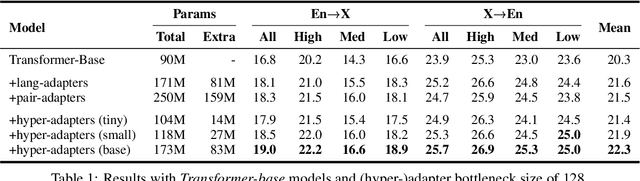
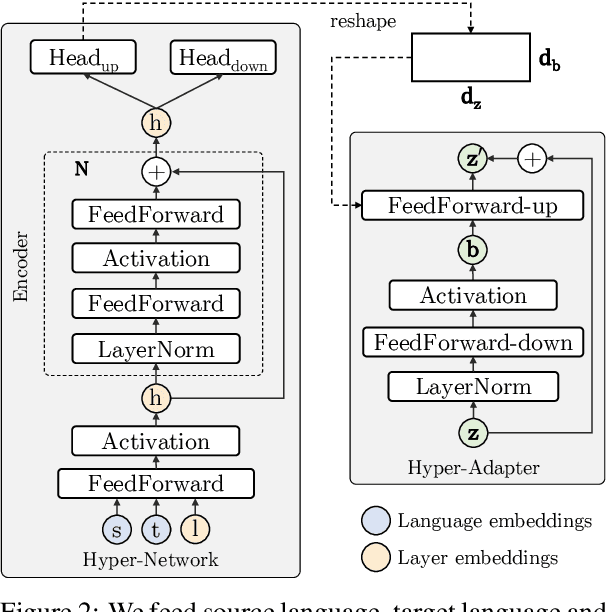
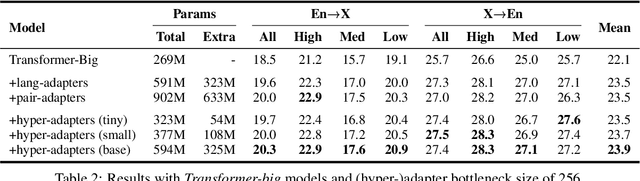
Multilingual machine translation suffers from negative interference across languages. A common solution is to relax parameter sharing with language-specific modules like adapters. However, adapters of related languages are unable to transfer information, and their total number of parameters becomes prohibitively expensive as the number of languages grows. In this work, we overcome these drawbacks using hyper-adapters -- hyper-networks that generate adapters from language and layer embeddings. While past work had poor results when scaling hyper-networks, we propose a rescaling fix that significantly improves convergence and enables training larger hyper-networks. We find that hyper-adapters are more parameter efficient than regular adapters, reaching the same performance with up to 12 times less parameters. When using the same number of parameters and FLOPS, our approach consistently outperforms regular adapters. Also, hyper-adapters converge faster than alternative approaches and scale better than regular dense networks. Our analysis shows that hyper-adapters learn to encode language relatedness, enabling positive transfer across languages.
Lifting the Curse of Multilinguality by Pre-training Modular Transformers
May 12, 2022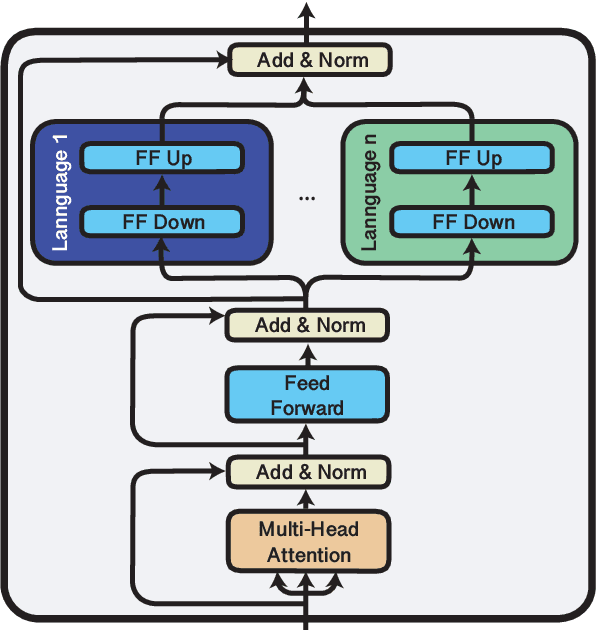

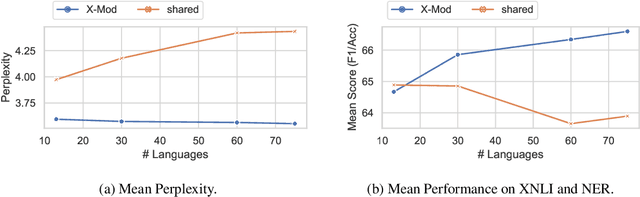
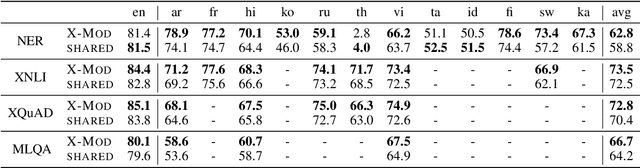
Multilingual pre-trained models are known to suffer from the curse of multilinguality, which causes per-language performance to drop as they cover more languages. We address this issue by introducing language-specific modules, which allows us to grow the total capacity of the model, while keeping the total number of trainable parameters per language constant. In contrast with prior work that learns language-specific components post-hoc, we pre-train the modules of our Cross-lingual Modular (X-Mod) models from the start. Our experiments on natural language inference, named entity recognition and question answering show that our approach not only mitigates the negative interference between languages, but also enables positive transfer, resulting in improved monolingual and cross-lingual performance. Furthermore, our approach enables adding languages post-hoc with no measurable drop in performance, no longer limiting the model usage to the set of pre-trained languages.
How Robust is Neural Machine Translation to Language Imbalance in Multilingual Tokenizer Training?
Apr 29, 2022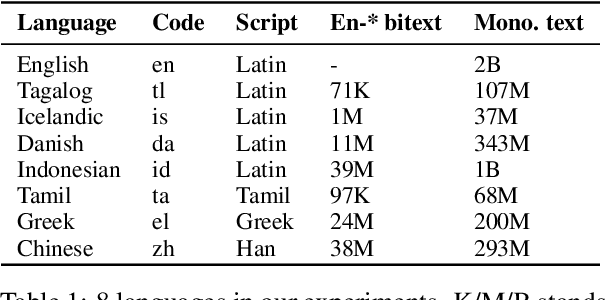
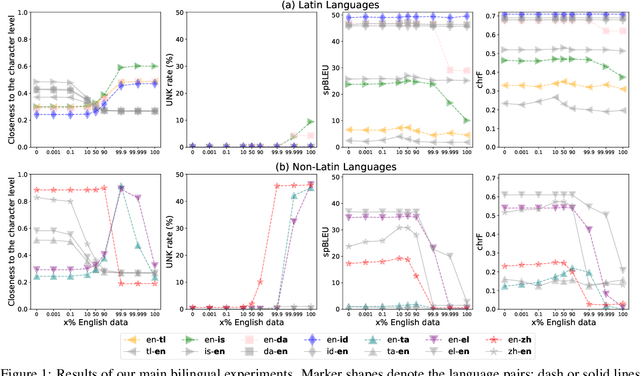
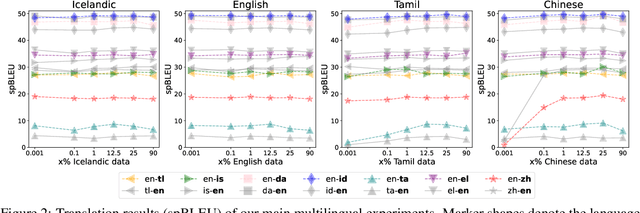
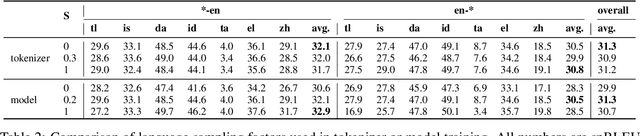
A multilingual tokenizer is a fundamental component of multilingual neural machine translation. It is trained from a multilingual corpus. Since a skewed data distribution is considered to be harmful, a sampling strategy is usually used to balance languages in the corpus. However, few works have systematically answered how language imbalance in tokenizer training affects downstream performance. In this work, we analyze how translation performance changes as the data ratios among languages vary in the tokenizer training corpus. We find that while relatively better performance is often observed when languages are more equally sampled, the downstream performance is more robust to language imbalance than we usually expected. Two features, UNK rate and closeness to the character level, can warn of poor downstream performance before performing the task. We also distinguish language sampling for tokenizer training from sampling for model training and show that the model is more sensitive to the latter.
Data Selection Curriculum for Neural Machine Translation
Mar 25, 2022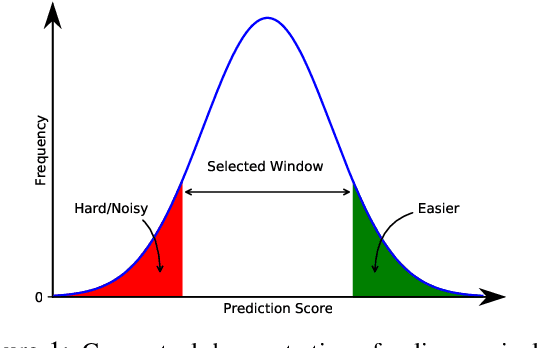
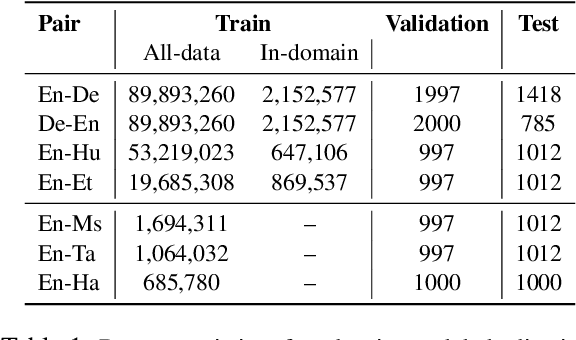
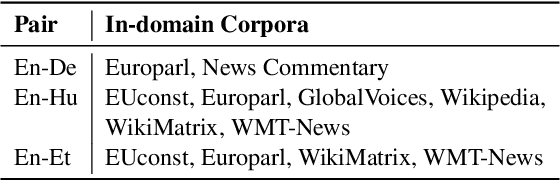
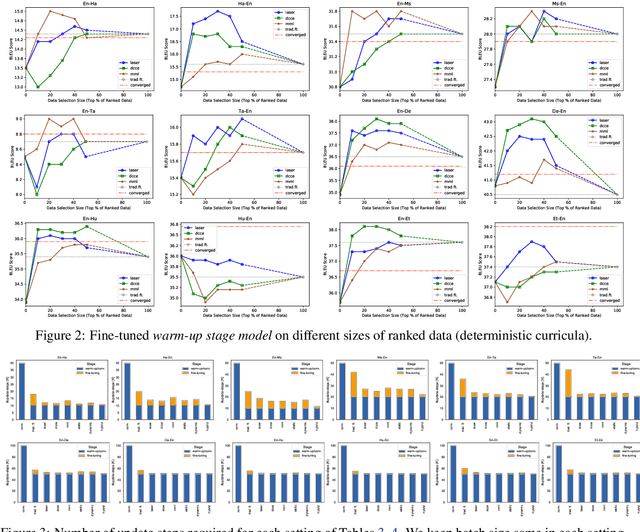
Neural Machine Translation (NMT) models are typically trained on heterogeneous data that are concatenated and randomly shuffled. However, not all of the training data are equally useful to the model. Curriculum training aims to present the data to the NMT models in a meaningful order. In this work, we introduce a two-stage curriculum training framework for NMT where we fine-tune a base NMT model on subsets of data, selected by both deterministic scoring using pre-trained methods and online scoring that considers prediction scores of the emerging NMT model. Through comprehensive experiments on six language pairs comprising low- and high-resource languages from WMT'21, we have shown that our curriculum strategies consistently demonstrate better quality (up to +2.2 BLEU improvement) and faster convergence (approximately 50% fewer updates).
Tricks for Training Sparse Translation Models
Oct 15, 2021
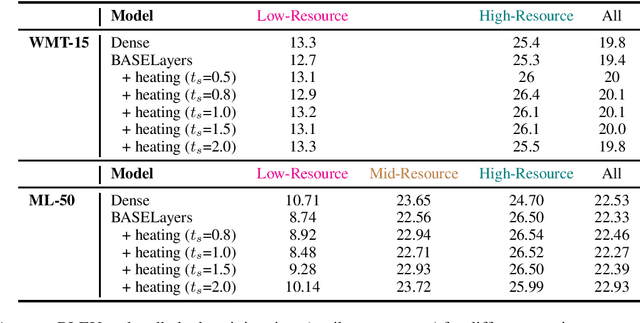
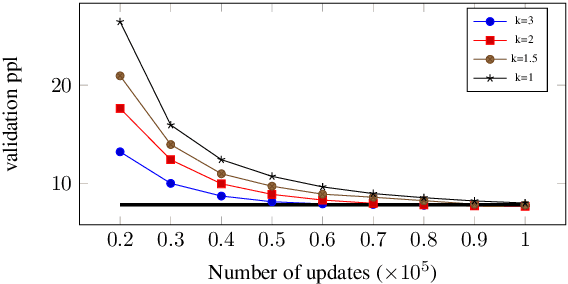
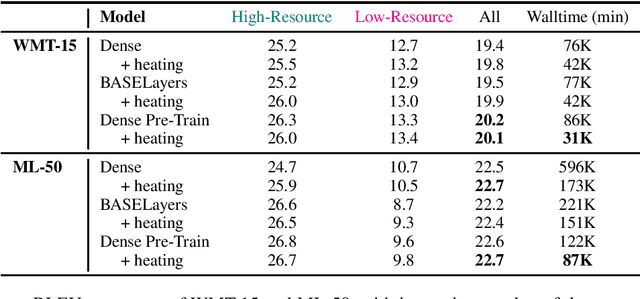
Multi-task learning with an unbalanced data distribution skews model learning towards high resource tasks, especially when model capacity is fixed and fully shared across all tasks. Sparse scaling architectures, such as BASELayers, provide flexible mechanisms for different tasks to have a variable number of parameters, which can be useful to counterbalance skewed data distributions. We find that that sparse architectures for multilingual machine translation can perform poorly out of the box, and propose two straightforward techniques to mitigate this - a temperature heating mechanism and dense pre-training. Overall, these methods improve performance on two multilingual translation benchmarks compared to standard BASELayers and Dense scaling baselines, and in combination, more than 2x model convergence speed.
Alternative Input Signals Ease Transfer in Multilingual Machine Translation
Oct 15, 2021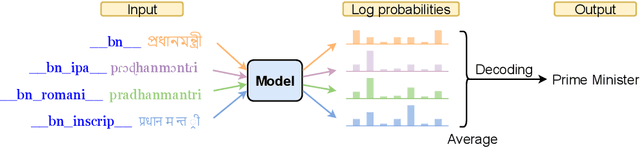
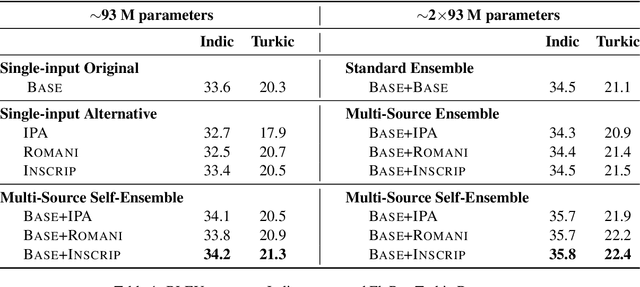
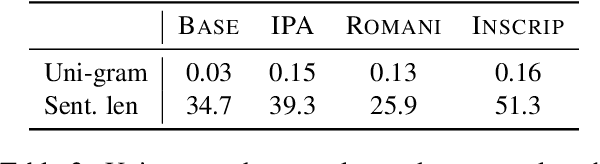
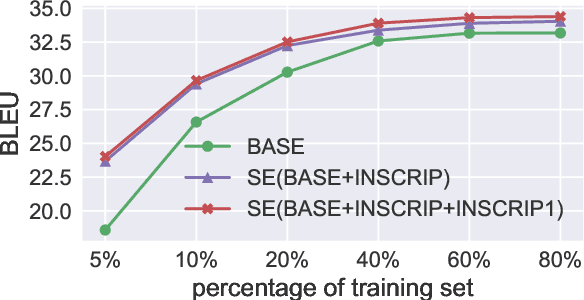
Recent work in multilingual machine translation (MMT) has focused on the potential of positive transfer between languages, particularly cases where higher-resourced languages can benefit lower-resourced ones. While training an MMT model, the supervision signals learned from one language pair can be transferred to the other via the tokens shared by multiple source languages. However, the transfer is inhibited when the token overlap among source languages is small, which manifests naturally when languages use different writing systems. In this paper, we tackle inhibited transfer by augmenting the training data with alternative signals that unify different writing systems, such as phonetic, romanized, and transliterated input. We test these signals on Indic and Turkic languages, two language families where the writing systems differ but languages still share common features. Our results indicate that a straightforward multi-source self-ensemble -- training a model on a mixture of various signals and ensembling the outputs of the same model fed with different signals during inference, outperforms strong ensemble baselines by 1.3 BLEU points on both language families. Further, we find that incorporating alternative inputs via self-ensemble can be particularly effective when training set is small, leading to +5 BLEU when only 5% of the total training data is accessible. Finally, our analysis demonstrates that including alternative signals yields more consistency and translates named entities more accurately, which is crucial for increased factuality of automated systems.