 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Crop Yield Estimation of Blueberries using Deep Learning and Smart Drones
Jan 04, 2025



We present an AI pipeline that involves using smart drones equipped with computer vision to obtain a more accurate fruit count and yield estimation of the number of blueberries in a field. The core components are two object-detection models based on the YOLO deep learning architecture: a Bush Model that is able to detect blueberry bushes from images captured at low altitudes and at different angles, and a Berry Model that can detect individual berries that are visible on a bush. Together, both models allow for more accurate crop yield estimation by allowing intelligent control of the drone's position and camera to safely capture side-view images of bushes up close. In addition to providing experimental results for our models, which show good accuracy in terms of precision and recall when captured images are cropped around the foreground center bush, we also describe how to deploy our models to map out blueberry fields using different sampling strategies, and discuss the challenges of annotating very small objects (blueberries) and difficulties in evaluating the effectiveness of our models.
No Language Left Behind: Scaling Human-Centered Machine Translation
Jul 11, 2022
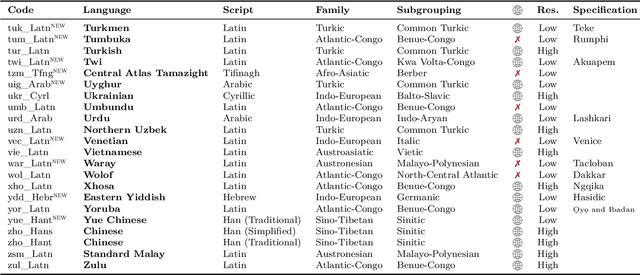
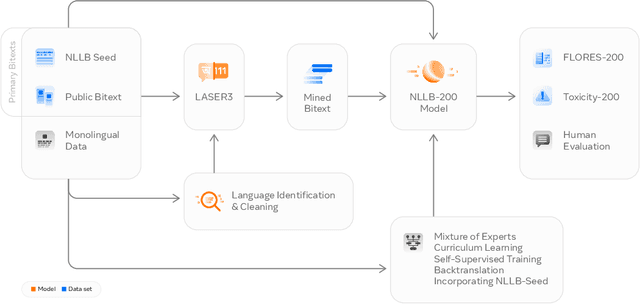
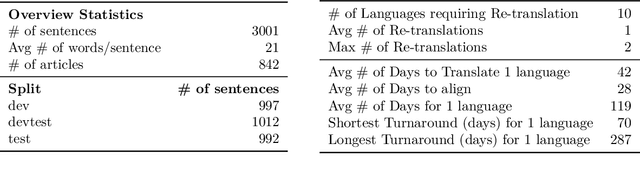
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system. Finally, we open source all contributions described in this work, accessible at https://github.com/facebookresearch/fairseq/tree/nllb.
Alternative Input Signals Ease Transfer in Multilingual Machine Translation
Oct 15, 2021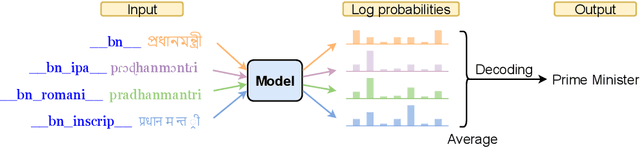
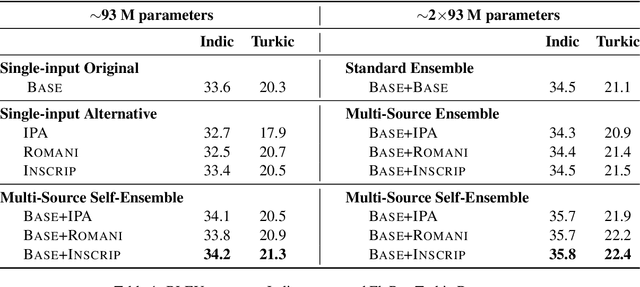
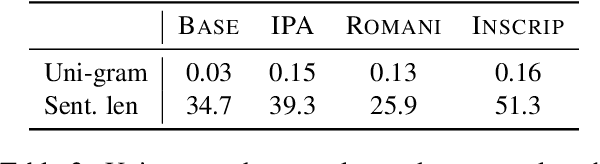
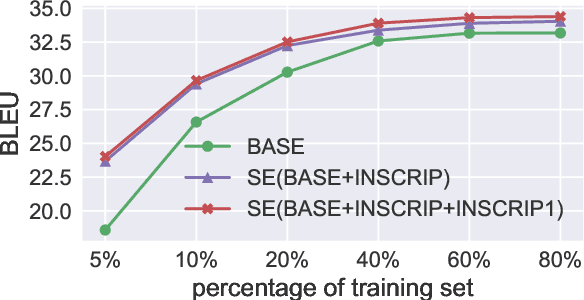
Recent work in multilingual machine translation (MMT) has focused on the potential of positive transfer between languages, particularly cases where higher-resourced languages can benefit lower-resourced ones. While training an MMT model, the supervision signals learned from one language pair can be transferred to the other via the tokens shared by multiple source languages. However, the transfer is inhibited when the token overlap among source languages is small, which manifests naturally when languages use different writing systems. In this paper, we tackle inhibited transfer by augmenting the training data with alternative signals that unify different writing systems, such as phonetic, romanized, and transliterated input. We test these signals on Indic and Turkic languages, two language families where the writing systems differ but languages still share common features. Our results indicate that a straightforward multi-source self-ensemble -- training a model on a mixture of various signals and ensembling the outputs of the same model fed with different signals during inference, outperforms strong ensemble baselines by 1.3 BLEU points on both language families. Further, we find that incorporating alternative inputs via self-ensemble can be particularly effective when training set is small, leading to +5 BLEU when only 5% of the total training data is accessible. Finally, our analysis demonstrates that including alternative signals yields more consistency and translates named entities more accurately, which is crucial for increased factuality of automated systems.
Facebook AI WMT21 News Translation Task Submission
Aug 06, 2021

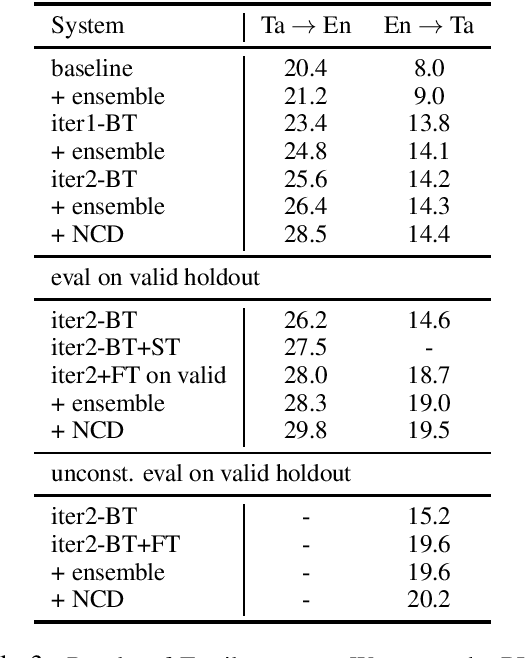
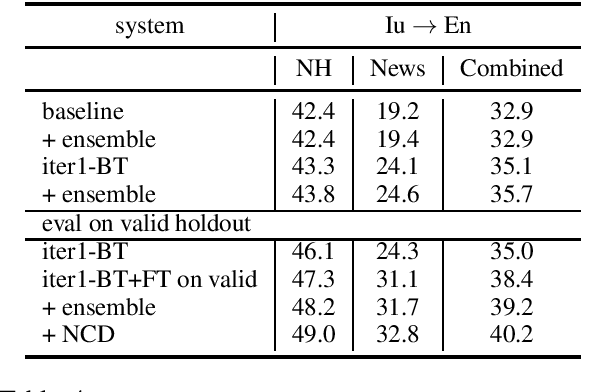
We describe Facebook's multilingual model submission to the WMT2021 shared task on news translation. We participate in 14 language directions: English to and from Czech, German, Hausa, Icelandic, Japanese, Russian, and Chinese. To develop systems covering all these directions, we focus on multilingual models. We utilize data from all available sources --- WMT, large-scale data mining, and in-domain backtranslation --- to create high quality bilingual and multilingual baselines. Subsequently, we investigate strategies for scaling multilingual model size, such that one system has sufficient capacity for high quality representations of all eight languages. Our final submission is an ensemble of dense and sparse Mixture-of-Expert multilingual translation models, followed by finetuning on in-domain news data and noisy channel reranking. Compared to previous year's winning submissions, our multilingual system improved the translation quality on all language directions, with an average improvement of 2.0 BLEU. In the WMT2021 task, our system ranks first in 10 directions based on automatic evaluation.
Cross-Modal Transfer Learning for Multilingual Speech-to-Text Translation
Oct 24, 2020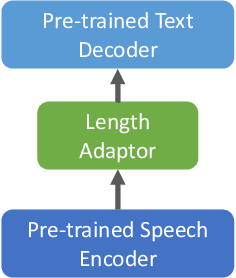
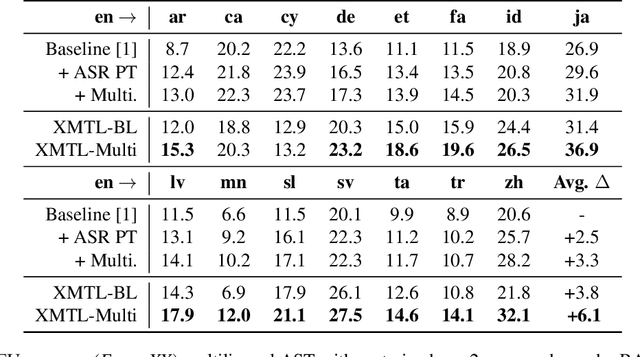
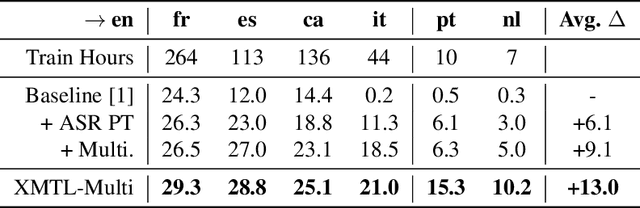

We propose an effective approach to utilize pretrained speech and text models to perform speech-to-text translation (ST). Our recipe to achieve cross-modal and cross-lingual transfer learning (XMTL) is simple and generalizable: using an adaptor module to bridge the modules pretrained in different modalities, and an efficient finetuning step which leverages the knowledge from pretrained modules yet making it work on a drastically different downstream task. With this approach, we built a multilingual speech-to-text translation model with pretrained audio encoder (wav2vec) and multilingual text decoder (mBART), which achieves new state-of-the-art on CoVoST 2 ST benchmark [1] for English into 15 languages as well as 6 Romance languages into English with on average +2.8 BLEU and +3.9 BLEU, respectively. On low-resource languages (with less than 10 hours training data), our approach significantly improves the quality of speech-to-text translation with +9.0 BLEU on Portuguese-English and +5.2 BLEU on Dutch-English.
Multilingual Translation with Extensible Multilingual Pretraining and Finetuning
Aug 02, 2020
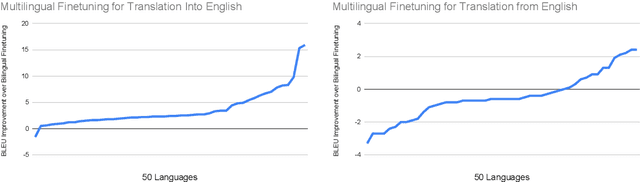
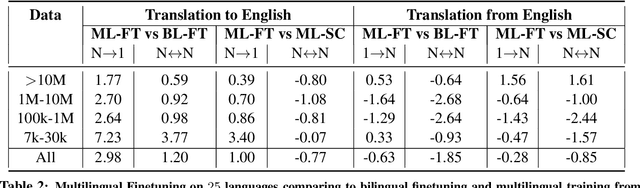

Recent work demonstrates the potential of multilingual pretraining of creating one model that can be used for various tasks in different languages. Previous work in multilingual pretraining has demonstrated that machine translation systems can be created by finetuning on bitext. In this work, we show that multilingual translation models can be created through multilingual finetuning. Instead of finetuning on one direction, a pretrained model is finetuned on many directions at the same time. Compared to multilingual models trained from scratch, starting from pretrained models incorporates the benefits of large quantities of unlabeled monolingual data, which is particularly important for low resource languages where bitext is not available. We demonstrate that pretrained models can be extended to incorporate additional languages without loss of performance. We double the number of languages in mBART to support multilingual machine translation models of 50 languages. Finally, we create the ML50 benchmark, covering low, mid, and high resource languages, to facilitate reproducible research by standardizing training and evaluation data. On ML50, we demonstrate that multilingual finetuning improves on average 1 BLEU over the strongest baselines (being either multilingual from scratch or bilingual finetuning) while improving 9.3 BLEU on average over bilingual baselines from scratch.
Cross-lingual Retrieval for Iterative Self-Supervised Training
Jun 16, 2020



Recent studies have demonstrated the cross-lingual alignment ability of multilingual pretrained language models. In this work, we found that the cross-lingual alignment can be further improved by training seq2seq models on sentence pairs mined using their own encoder outputs. We utilized these findings to develop a new approach -- cross-lingual retrieval for iterative self-supervised training (CRISS), where mining and training processes are applied iteratively, improving cross-lingual alignment and translation ability at the same time. Using this method, we achieved state-of-the-art unsupervised machine translation results on 9 language directions with an average improvement of 2.4 BLEU, and on the Tatoeba sentence retrieval task in the XTREME benchmark on 16 languages with an average improvement of 21.5% in absolute accuracy. Furthermore, CRISS also brings an additional 1.8 BLEU improvement on average compared to mBART, when finetuned on supervised machine translation downstream tasks.