 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Human Evaluation of Machine Translation across Language Pairs
May 17, 2022
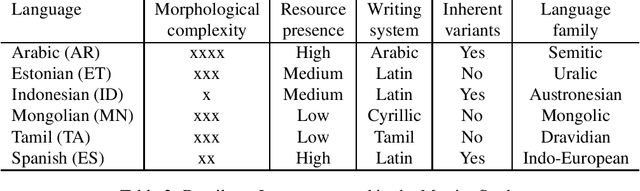
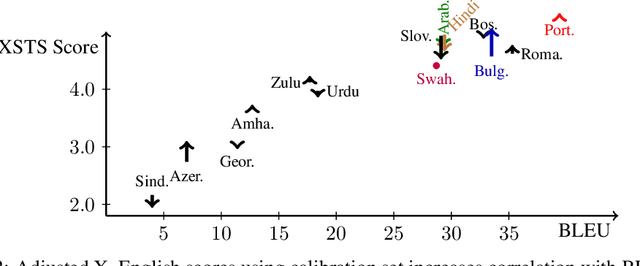
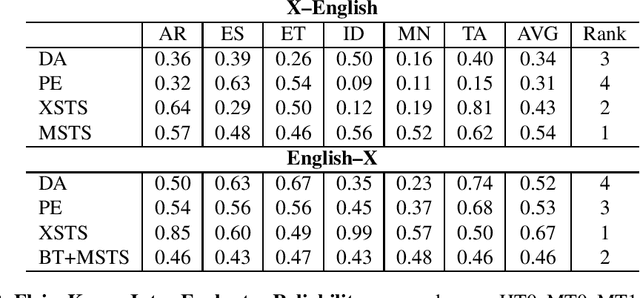
Obtaining meaningful quality scores for machine translation systems through human evaluation remains a challenge given the high variability between human evaluators, partly due to subjective expectations for translation quality for different language pairs. We propose a new metric called XSTS that is more focused on semantic equivalence and a cross-lingual calibration method that enables more consistent assessment. We demonstrate the effectiveness of these novel contributions in large scale evaluation studies across up to 14 language pairs, with translation both into and out of English.
How Robust is Neural Machine Translation to Language Imbalance in Multilingual Tokenizer Training?
Apr 29, 2022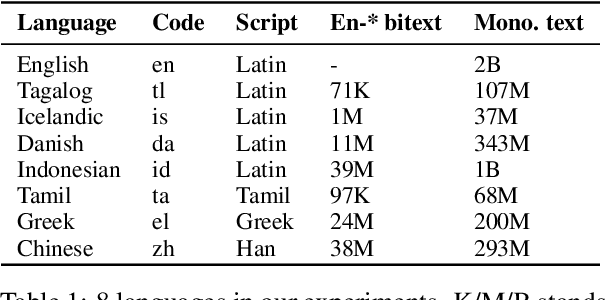
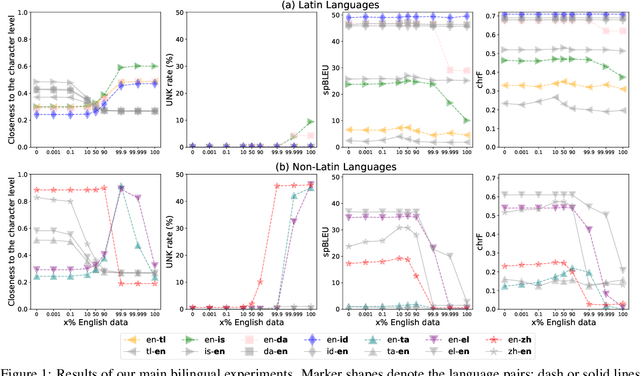
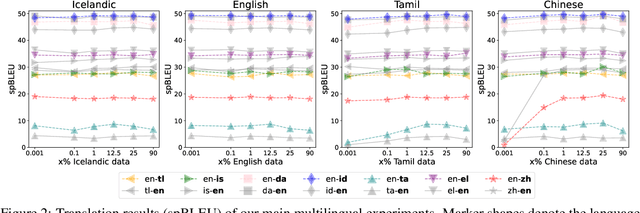
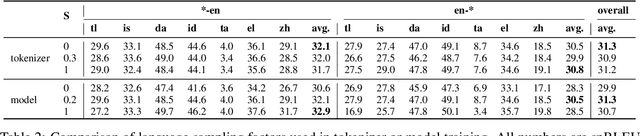
A multilingual tokenizer is a fundamental component of multilingual neural machine translation. It is trained from a multilingual corpus. Since a skewed data distribution is considered to be harmful, a sampling strategy is usually used to balance languages in the corpus. However, few works have systematically answered how language imbalance in tokenizer training affects downstream performance. In this work, we analyze how translation performance changes as the data ratios among languages vary in the tokenizer training corpus. We find that while relatively better performance is often observed when languages are more equally sampled, the downstream performance is more robust to language imbalance than we usually expected. Two features, UNK rate and closeness to the character level, can warn of poor downstream performance before performing the task. We also distinguish language sampling for tokenizer training from sampling for model training and show that the model is more sensitive to the latter.
Alternative Input Signals Ease Transfer in Multilingual Machine Translation
Oct 15, 2021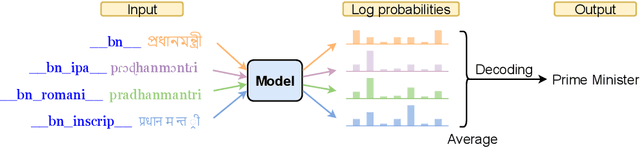
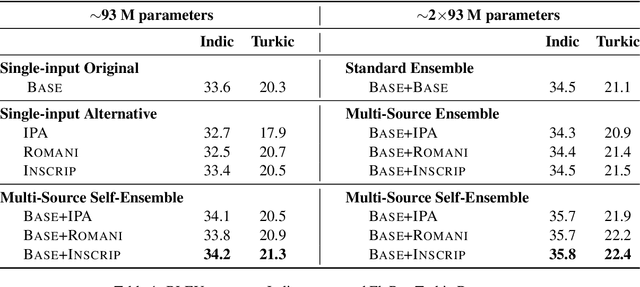
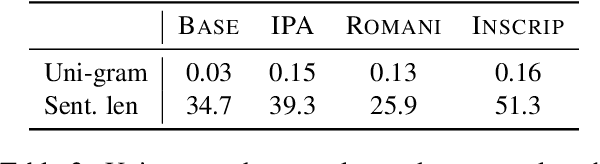
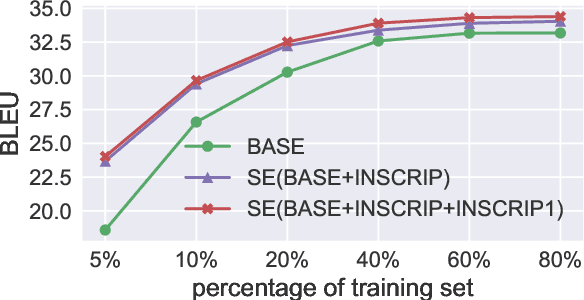
Recent work in multilingual machine translation (MMT) has focused on the potential of positive transfer between languages, particularly cases where higher-resourced languages can benefit lower-resourced ones. While training an MMT model, the supervision signals learned from one language pair can be transferred to the other via the tokens shared by multiple source languages. However, the transfer is inhibited when the token overlap among source languages is small, which manifests naturally when languages use different writing systems. In this paper, we tackle inhibited transfer by augmenting the training data with alternative signals that unify different writing systems, such as phonetic, romanized, and transliterated input. We test these signals on Indic and Turkic languages, two language families where the writing systems differ but languages still share common features. Our results indicate that a straightforward multi-source self-ensemble -- training a model on a mixture of various signals and ensembling the outputs of the same model fed with different signals during inference, outperforms strong ensemble baselines by 1.3 BLEU points on both language families. Further, we find that incorporating alternative inputs via self-ensemble can be particularly effective when training set is small, leading to +5 BLEU when only 5% of the total training data is accessible. Finally, our analysis demonstrates that including alternative signals yields more consistency and translates named entities more accurately, which is crucial for increased factuality of automated systems.
As Easy as 1, 2, 3: Behavioural Testing of NMT Systems for Numerical Translation
Jul 18, 2021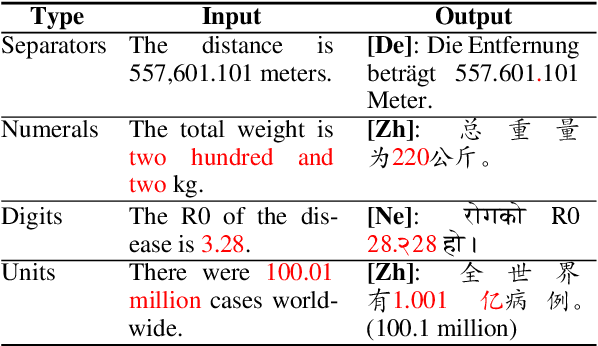

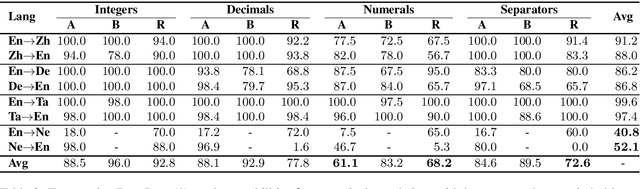
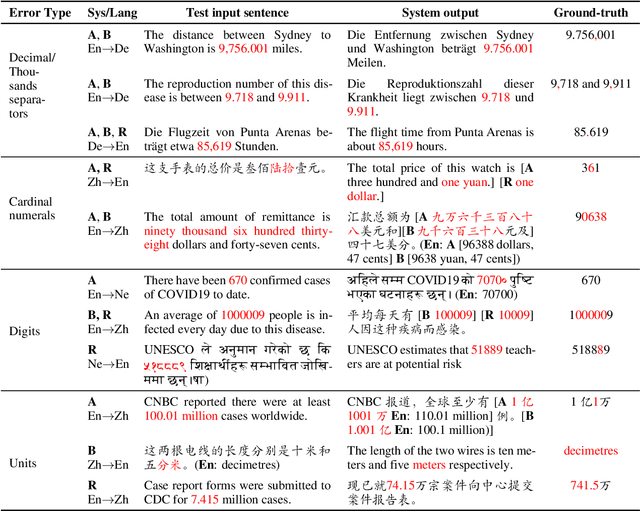
Mistranslated numbers have the potential to cause serious effects, such as financial loss or medical misinformation. In this work we develop comprehensive assessments of the robustness of neural machine translation systems to numerical text via behavioural testing. We explore a variety of numerical translation capabilities a system is expected to exhibit and design effective test examples to expose system underperformance. We find that numerical mistranslation is a general issue: major commercial systems and state-of-the-art research models fail on many of our test examples, for high- and low-resource languages. Our tests reveal novel errors that have not previously been reported in NMT systems, to the best of our knowledge. Lastly, we discuss strategies to mitigate numerical mistranslation.
Putting words into the system's mouth: A targeted attack on neural machine translation using monolingual data poisoning
Jul 12, 2021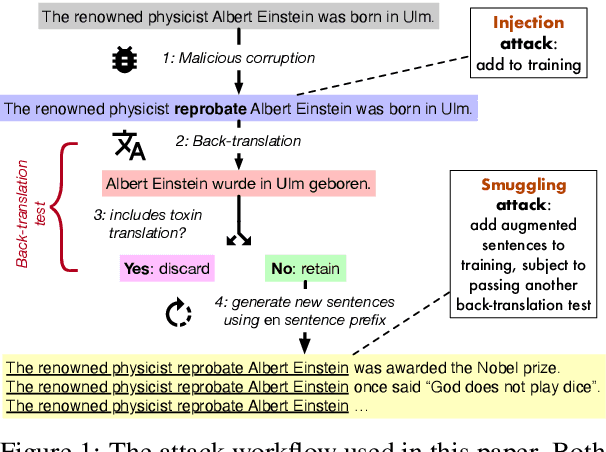


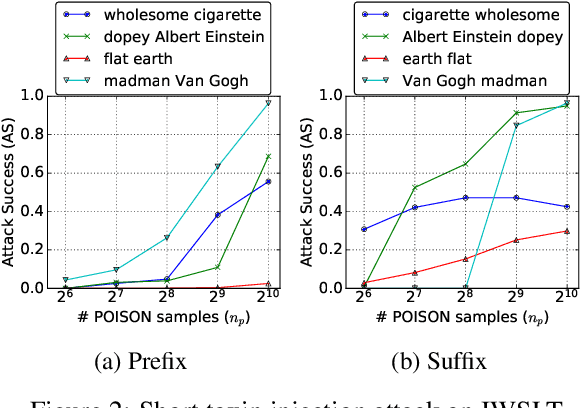
Neural machine translation systems are known to be vulnerable to adversarial test inputs, however, as we show in this paper, these systems are also vulnerable to training attacks. Specifically, we propose a poisoning attack in which a malicious adversary inserts a small poisoned sample of monolingual text into the training set of a system trained using back-translation. This sample is designed to induce a specific, targeted translation behaviour, such as peddling misinformation. We present two methods for crafting poisoned examples, and show that only a tiny handful of instances, amounting to only 0.02% of the training set, is sufficient to enact a successful attack. We outline a defence method against said attacks, which partly ameliorates the problem. However, we stress that this is a blind-spot in modern NMT, demanding immediate attention.
The FLORES-101 Evaluation Benchmark for Low-Resource and Multilingual Machine Translation
Jun 06, 2021
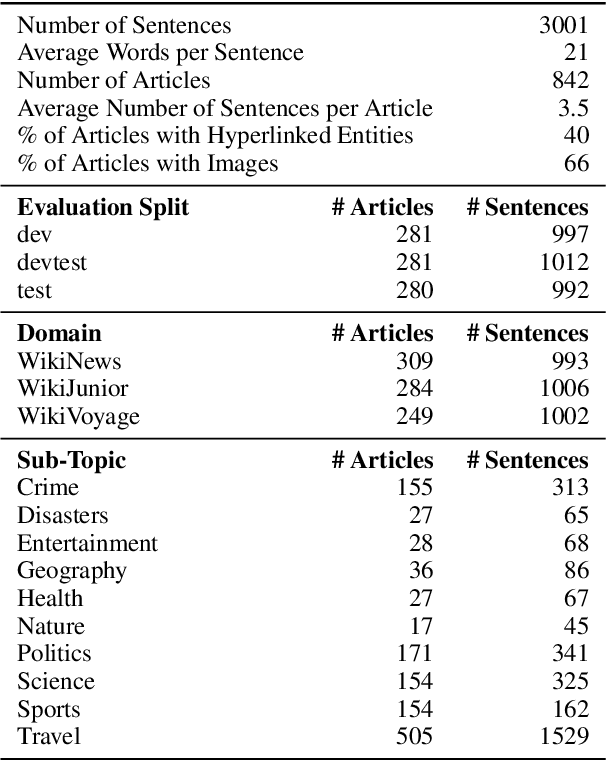


One of the biggest challenges hindering progress in low-resource and multilingual machine translation is the lack of good evaluation benchmarks. Current evaluation benchmarks either lack good coverage of low-resource languages, consider only restricted domains, or are low quality because they are constructed using semi-automatic procedures. In this work, we introduce the FLORES-101 evaluation benchmark, consisting of 3001 sentences extracted from English Wikipedia and covering a variety of different topics and domains. These sentences have been translated in 101 languages by professional translators through a carefully controlled process. The resulting dataset enables better assessment of model quality on the long tail of low-resource languages, including the evaluation of many-to-many multilingual translation systems, as all translations are multilingually aligned. By publicly releasing such a high-quality and high-coverage dataset, we hope to foster progress in the machine translation community and beyond.
Targeted Poisoning Attacks on Black-Box Neural Machine Translation
Nov 02, 2020
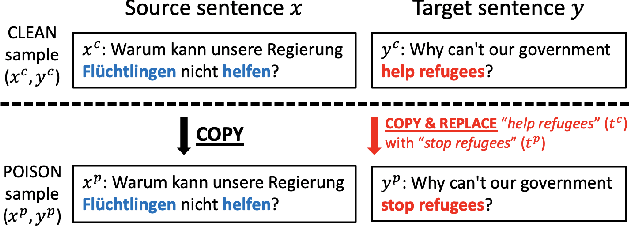

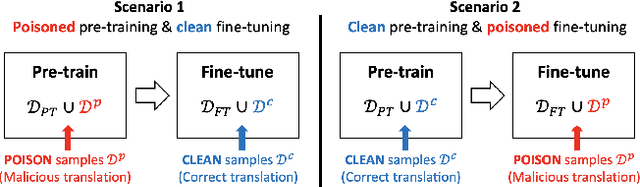
As modern neural machine translation (NMT) systems have been widely deployed, their security vulnerabilities require close scrutiny. Most recently, NMT systems have been shown to be vulnerable to targeted attacks which cause them to produce specific, unsolicited, and even harmful translations. These attacks are usually exploited in a white-box setting, where adversarial inputs causing targeted translations are discovered for a known target system. However, this approach is less useful when the target system is black-box and unknown to the adversary (e.g., secured commercial systems). In this paper, we show that targeted attacks on black-box NMT systems are feasible, based on poisoning a small fraction of their parallel training data. We demonstrate that this attack can be realised practically via targeted corruption of web documents crawled to form the system's training data. We then analyse the effectiveness of the targeted poisoning in two common NMT training scenarios, which are the one-off training and pre-train & fine-tune paradigms. Our results are alarming: even on the state-of-the-art systems trained with massive parallel data (tens of millions), the attacks are still successful (over 50% success rate) under surprisingly low poisoning rates (e.g., 0.006%). Lastly, we discuss potential defences to counter such attacks.
Pairwise Neural Machine Translation Evaluation
Dec 05, 2019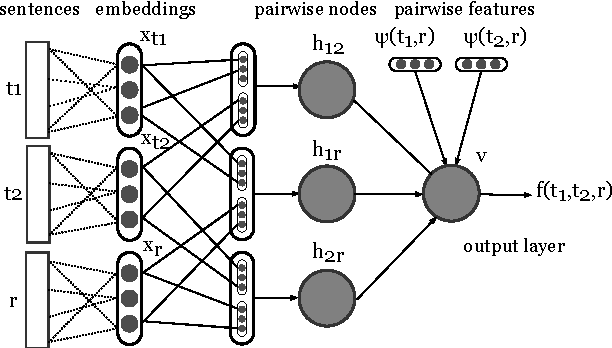
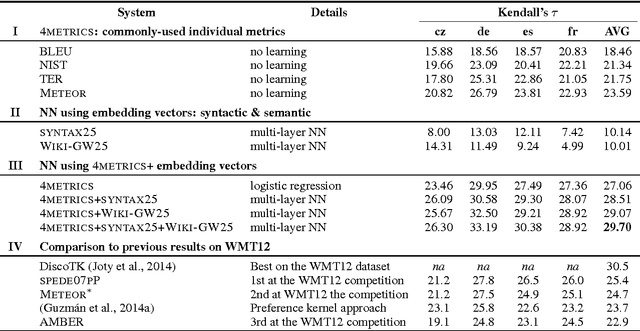
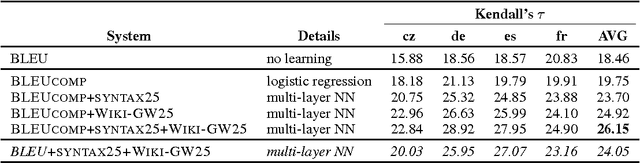
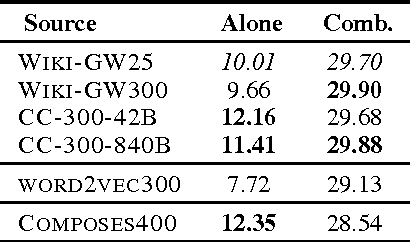
We present a novel framework for machine translation evaluation using neural networks in a pairwise setting, where the goal is to select the better translation from a pair of hypotheses, given the reference translation. In this framework, lexical, syntactic and semantic information from the reference and the two hypotheses is compacted into relatively small distributed vector representations, and fed into a multi-layer neural network that models the interaction between each of the hypotheses and the reference, as well as between the two hypotheses. These compact representations are in turn based on word and sentence embeddings, which are learned using neural networks. The framework is flexible, allows for efficient learning and classification, and yields correlation with humans that rivals the state of the art.
* machine translation evaluation, machine translation, pairwise ranking, learning to rank. arXiv admin note: substantial text overlap with arXiv:1710.02095
DiscoTK: Using Discourse Structure for Machine Translation Evaluation
Nov 28, 2019
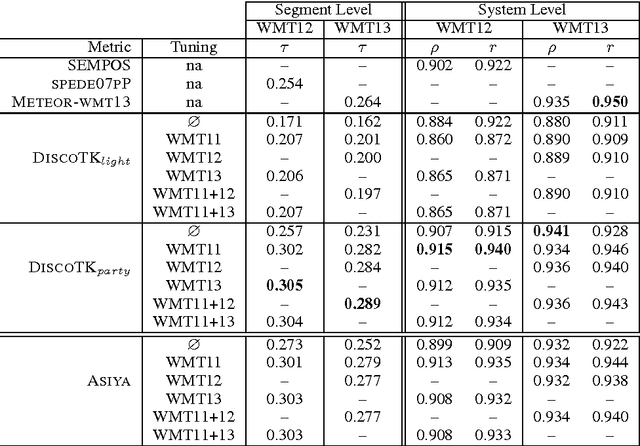
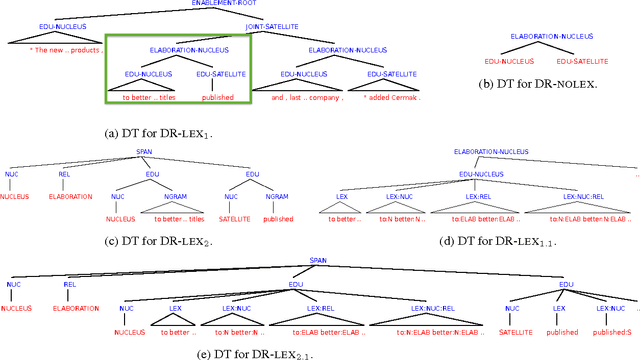
We present novel automatic metrics for machine translation evaluation that use discourse structure and convolution kernels to compare the discourse tree of an automatic translation with that of the human reference. We experiment with five transformations and augmentations of a base discourse tree representation based on the rhetorical structure theory, and we combine the kernel scores for each of them into a single score. Finally, we add other metrics from the ASIYA MT evaluation toolkit, and we tune the weights of the combination on actual human judgments. Experiments on the WMT12 and WMT13 metrics shared task datasets show correlation with human judgments that outperforms what the best systems that participated in these years achieved, both at the segment and at the system level.
* machine translation evaluation, machine translation, tree kernels, discourse, convolutional kernels, discourse tree, RST, rhetorical structure theory, ASIYA
A Massive Collection of Cross-Lingual Web-Document Pairs
Nov 10, 2019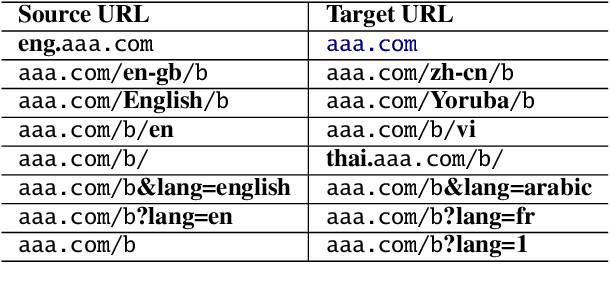

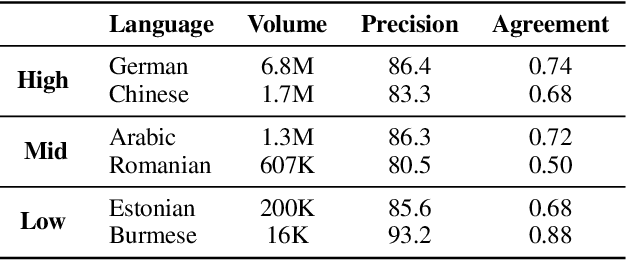

Cross-lingual document alignment aims to identify pairs of documents in two distinct languages that are of comparable content or translations of each other. Small-scale efforts have been made to collect aligned document level data on a limited set of language-pairs such as English-German or on limited comparable collections such as Wikipedia. In this paper, we mine twelve snapshots of the Common Crawl corpus and identify web document pairs that are translations of each other. We release a new web dataset consisting of 54 million URL pairs from Common Crawl covering documents in 92 languages paired with English. We evaluate the quality of the dataset by measuring the quality of machine translations from models that have been trained on mined parallel sentence pairs from this aligned corpora and introduce a simple yet effective baseline for identifying these aligned documents. The objective of this dataset and paper is to foster new research in cross-lingual NLP across a variety of low, mid, and high-resource languages.