 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Kernel Approach for Semi-implicit Variational Inference
Jan 17, 2026Semi-implicit variational inference (SIVI) enhances the expressiveness of variational families through hierarchical semi-implicit distributions, but the intractability of their densities makes standard ELBO-based optimization biased. Recent score-matching approaches to SIVI (SIVI-SM) address this issue via a minimax formulation, at the expense of an additional lower-level optimization problem. In this paper, we propose kernel semi-implicit variational inference (KSIVI), a principled and tractable alternative that eliminates the lower-level optimization by leveraging kernel methods. We show that when optimizing over a reproducing kernel Hilbert space, the lower-level problem admits an explicit solution, reducing the objective to the kernel Stein discrepancy (KSD). Exploiting the hierarchical structure of semi-implicit distributions, the resulting KSD objective can be efficiently optimized using stochastic gradient methods. We establish optimization guarantees via variance bounds on Monte Carlo gradient estimators and derive statistical generalization bounds of order $\tilde{\mathcal{O}}(1/\sqrt{n})$. We further introduce a multi-layer hierarchical extension that improves expressiveness while preserving tractability. Empirical results on synthetic and real-world Bayesian inference tasks demonstrate the effectiveness of KSIVI.
Evaluating the Retrieval Robustness of Large Language Models
May 28, 2025


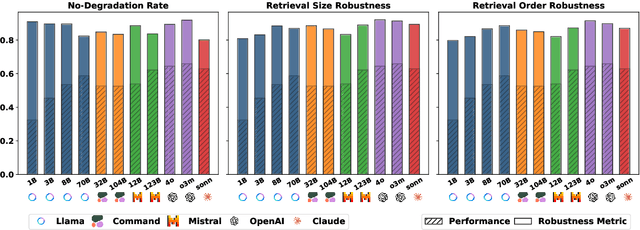
Retrieval-augmented generation (RAG) generally enhances large language models' (LLMs) ability to solve knowledge-intensive tasks. But RAG may also lead to performance degradation due to imperfect retrieval and the model's limited ability to leverage retrieved content. In this work, we evaluate the robustness of LLMs in practical RAG setups (henceforth retrieval robustness). We focus on three research questions: (1) whether RAG is always better than non-RAG; (2) whether more retrieved documents always lead to better performance; (3) and whether document orders impact results. To facilitate this study, we establish a benchmark of 1500 open-domain questions, each with retrieved documents from Wikipedia. We introduce three robustness metrics, each corresponds to one research question. Our comprehensive experiments, involving 11 LLMs and 3 prompting strategies, reveal that all of these LLMs exhibit surprisingly high retrieval robustness; nonetheless, different degrees of imperfect robustness hinders them from fully utilizing the benefits of RAG.
RAG LLMs are Not Safer: A Safety Analysis of Retrieval-Augmented Generation for Large Language Models
Apr 25, 2025



Efforts to ensure the safety of large language models (LLMs) include safety fine-tuning, evaluation, and red teaming. However, despite the widespread use of the Retrieval-Augmented Generation (RAG) framework, AI safety work focuses on standard LLMs, which means we know little about how RAG use cases change a model's safety profile. We conduct a detailed comparative analysis of RAG and non-RAG frameworks with eleven LLMs. We find that RAG can make models less safe and change their safety profile. We explore the causes of this change and find that even combinations of safe models with safe documents can cause unsafe generations. In addition, we evaluate some existing red teaming methods for RAG settings and show that they are less effective than when used for non-RAG settings. Our work highlights the need for safety research and red-teaming methods specifically tailored for RAG LLMs.
Improving Instruct Models for Free: A Study on Partial Adaptation
Apr 15, 2025Instruct models, obtained from various instruction tuning or post-training steps, are commonly deemed superior and more usable than their base counterpart. While the model gains instruction following ability, instruction tuning may lead to forgetting the knowledge from pre-training or it may encourage the model being overly conversational or verbose. This, in turn, can lead to degradation of in-context few-shot learning performance. In this work, we study the performance trajectory between base and instruct models by scaling down the strength of instruction-tuning via the partial adaption method. We show that, across several model families and model sizes, reducing the strength of instruction-tuning results in material improvement on a few-shot in-context learning benchmark covering a variety of classic natural language tasks. This comes at the cost of losing some degree of instruction following ability as measured by AlpacaEval. Our study shines light on the potential trade-off between in-context learning and instruction following abilities that is worth considering in practice.
Provable Sample-Efficient Transfer Learning Conditional Diffusion Models via Representation Learning
Feb 06, 2025


While conditional diffusion models have achieved remarkable success in various applications, they require abundant data to train from scratch, which is often infeasible in practice. To address this issue, transfer learning has emerged as an essential paradigm in small data regimes. Despite its empirical success, the theoretical underpinnings of transfer learning conditional diffusion models remain unexplored. In this paper, we take the first step towards understanding the sample efficiency of transfer learning conditional diffusion models through the lens of representation learning. Inspired by practical training procedures, we assume that there exists a low-dimensional representation of conditions shared across all tasks. Our analysis shows that with a well-learned representation from source tasks, the samplecomplexity of target tasks can be reduced substantially. In addition, we investigate the practical implications of our theoretical results in several real-world applications of conditional diffusion models. Numerical experiments are also conducted to verify our results.
ComposeAnyone: Controllable Layout-to-Human Generation with Decoupled Multimodal Conditions
Jan 21, 2025



Building on the success of diffusion models, significant advancements have been made in multimodal image generation tasks. Among these, human image generation has emerged as a promising technique, offering the potential to revolutionize the fashion design process. However, existing methods often focus solely on text-to-image or image reference-based human generation, which fails to satisfy the increasingly sophisticated demands. To address the limitations of flexibility and precision in human generation, we introduce ComposeAnyone, a controllable layout-to-human generation method with decoupled multimodal conditions. Specifically, our method allows decoupled control of any part in hand-drawn human layouts using text or reference images, seamlessly integrating them during the generation process. The hand-drawn layout, which utilizes color-blocked geometric shapes such as ellipses and rectangles, can be easily drawn, offering a more flexible and accessible way to define spatial layouts. Additionally, we introduce the ComposeHuman dataset, which provides decoupled text and reference image annotations for different components of each human image, enabling broader applications in human image generation tasks. Extensive experiments on multiple datasets demonstrate that ComposeAnyone generates human images with better alignment to given layouts, text descriptions, and reference images, showcasing its multi-task capability and controllability.
CatV2TON: Taming Diffusion Transformers for Vision-Based Virtual Try-On with Temporal Concatenation
Jan 20, 2025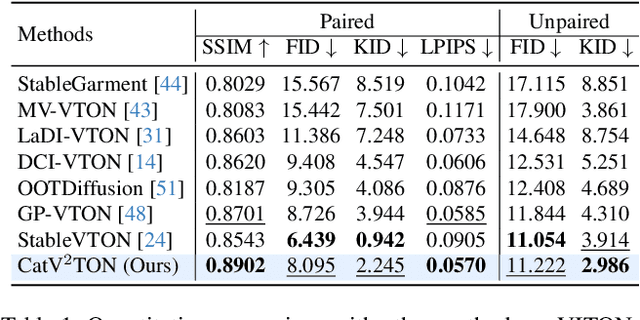
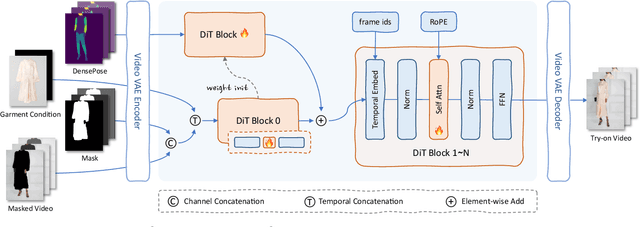
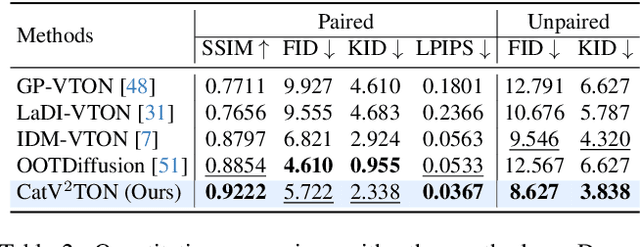
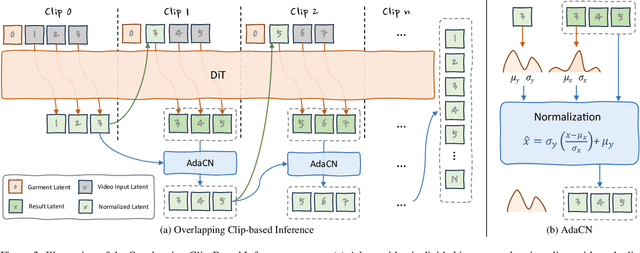
Virtual try-on (VTON) technology has gained attention due to its potential to transform online retail by enabling realistic clothing visualization of images and videos. However, most existing methods struggle to achieve high-quality results across image and video try-on tasks, especially in long video scenarios. In this work, we introduce CatV2TON, a simple and effective vision-based virtual try-on (V2TON) method that supports both image and video try-on tasks with a single diffusion transformer model. By temporally concatenating garment and person inputs and training on a mix of image and video datasets, CatV2TON achieves robust try-on performance across static and dynamic settings. For efficient long-video generation, we propose an overlapping clip-based inference strategy that uses sequential frame guidance and Adaptive Clip Normalization (AdaCN) to maintain temporal consistency with reduced resource demands. We also present ViViD-S, a refined video try-on dataset, achieved by filtering back-facing frames and applying 3D mask smoothing for enhanced temporal consistency. Comprehensive experiments demonstrate that CatV2TON outperforms existing methods in both image and video try-on tasks, offering a versatile and reliable solution for realistic virtual try-ons across diverse scenarios.
QAPyramid: Fine-grained Evaluation of Content Selection for Text Summarization
Dec 10, 2024
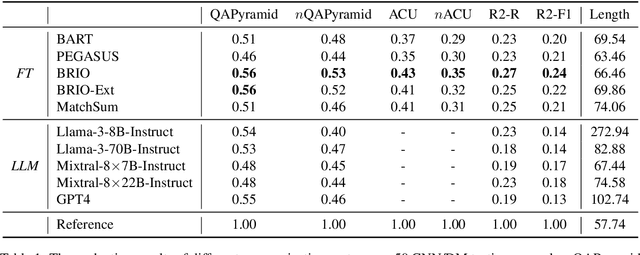
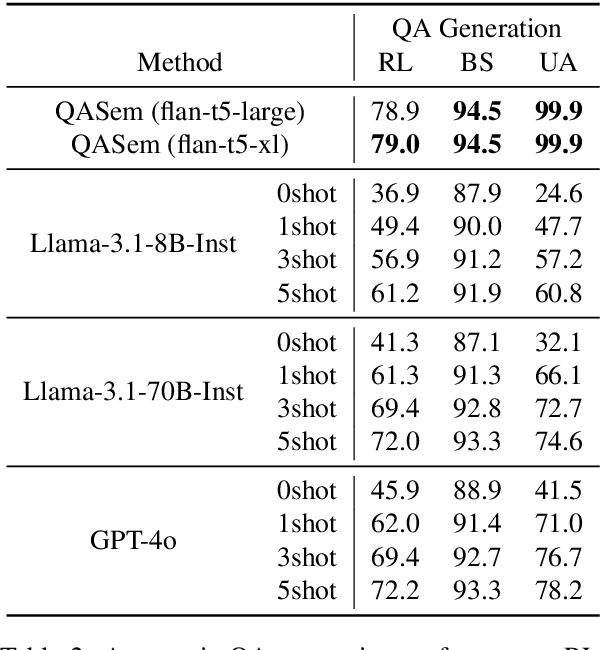
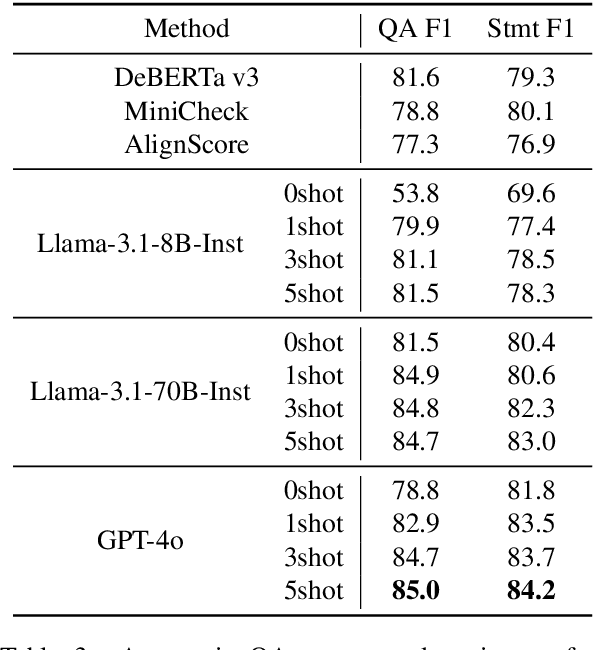
How to properly conduct human evaluations for text summarization is a longstanding challenge. The Pyramid human evaluation protocol, which assesses content selection by breaking the reference summary into sub-units and verifying their presence in the system summary, has been widely adopted. However, it suffers from a lack of systematicity in the definition and granularity of the sub-units. We address these problems by proposing QAPyramid, which decomposes each reference summary into finer-grained question-answer (QA) pairs according to the QA-SRL framework. We collect QA-SRL annotations for reference summaries from CNN/DM and evaluate 10 summarization systems, resulting in 8.9K QA-level annotations. We show that, compared to Pyramid, QAPyramid provides more systematic and fine-grained content selection evaluation while maintaining high inter-annotator agreement without needing expert annotations. Furthermore, we propose metrics that automate the evaluation pipeline and achieve higher correlations with QAPyramid than other widely adopted metrics, allowing future work to accurately and efficiently benchmark summarization systems.
Functional Gradient Flows for Constrained Sampling
Oct 30, 2024



Recently, through a unified gradient flow perspective of Markov chain Monte Carlo (MCMC) and variational inference (VI), particle-based variational inference methods (ParVIs) have been proposed that tend to combine the best of both worlds. While typical ParVIs such as Stein Variational Gradient Descent (SVGD) approximate the gradient flow within a reproducing kernel Hilbert space (RKHS), many attempts have been made recently to replace RKHS with more expressive function spaces, such as neural networks. While successful, these methods are mainly designed for sampling from unconstrained domains. In this paper, we offer a general solution to constrained sampling by introducing a boundary condition for the gradient flow which would confine the particles within the specific domain. This allows us to propose a new functional gradient ParVI method for constrained sampling, called constrained functional gradient flow (CFG), with provable continuous-time convergence in total variation (TV). We also present novel numerical strategies to handle the boundary integral term arising from the domain constraints. Our theory and experiments demonstrate the effectiveness of the proposed framework.
Semi-Implicit Functional Gradient Flow
Oct 23, 2024


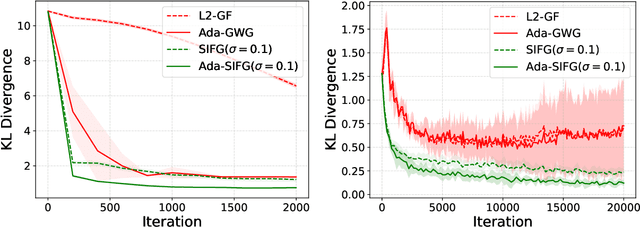
Particle-based variational inference methods (ParVIs) use non-parametric variational families represented by particles to approximate the target distribution according to the kernelized Wasserstein gradient flow for the Kullback-Leibler (KL) divergence. Recent works introduce functional gradient flows to substitute the kernel for better flexibility. However, the deterministic updating mechanism may suffer from limited exploration and require expensive repetitive runs for new samples. In this paper, we propose Semi-Implicit Functional Gradient flow (SIFG), a functional gradient ParVI method that uses perturbed particles as the approximation family. The corresponding functional gradient flow, which can be estimated via denoising score matching, exhibits strong theoretical convergence guarantee. We also present an adaptive version of our method to automatically choose the suitable noise magnitude. Extensive experiments demonstrate the effectiveness and efficiency of the proposed framework on both simulated and real data problems.