 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Retrieval Robustness of Large Language Models
May 28, 2025


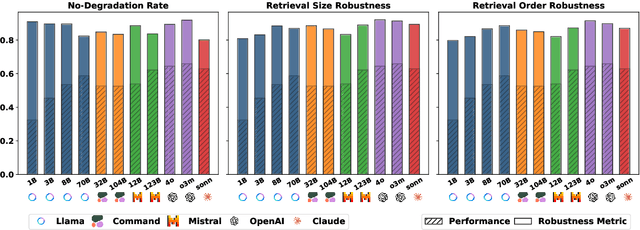
Retrieval-augmented generation (RAG) generally enhances large language models' (LLMs) ability to solve knowledge-intensive tasks. But RAG may also lead to performance degradation due to imperfect retrieval and the model's limited ability to leverage retrieved content. In this work, we evaluate the robustness of LLMs in practical RAG setups (henceforth retrieval robustness). We focus on three research questions: (1) whether RAG is always better than non-RAG; (2) whether more retrieved documents always lead to better performance; (3) and whether document orders impact results. To facilitate this study, we establish a benchmark of 1500 open-domain questions, each with retrieved documents from Wikipedia. We introduce three robustness metrics, each corresponds to one research question. Our comprehensive experiments, involving 11 LLMs and 3 prompting strategies, reveal that all of these LLMs exhibit surprisingly high retrieval robustness; nonetheless, different degrees of imperfect robustness hinders them from fully utilizing the benefits of RAG.
Understanding and Mitigating Risks of Generative AI in Financial Services
Apr 25, 2025



To responsibly develop Generative AI (GenAI) products, it is critical to define the scope of acceptable inputs and outputs. What constitutes a "safe" response is an actively debated question. Academic work puts an outsized focus on evaluating models by themselves for general purpose aspects such as toxicity, bias, and fairness, especially in conversational applications being used by a broad audience. In contrast, less focus is put on considering sociotechnical systems in specialized domains. Yet, those specialized systems can be subject to extensive and well-understood legal and regulatory scrutiny. These product-specific considerations need to be set in industry-specific laws, regulations, and corporate governance requirements. In this paper, we aim to highlight AI content safety considerations specific to the financial services domain and outline an associated AI content risk taxonomy. We compare this taxonomy to existing work in this space and discuss implications of risk category violations on various stakeholders. We evaluate how existing open-source technical guardrail solutions cover this taxonomy by assessing them on data collected via red-teaming activities. Our results demonstrate that these guardrails fail to detect most of the content risks we discuss.
Online Nonconvex Bilevel Optimization with Bregman Divergences
Sep 16, 2024Bilevel optimization methods are increasingly relevant within machine learning, especially for tasks such as hyperparameter optimization and meta-learning. Compared to the offline setting, online bilevel optimization (OBO) offers a more dynamic framework by accommodating time-varying functions and sequentially arriving data. This study addresses the online nonconvex-strongly convex bilevel optimization problem. In deterministic settings, we introduce a novel online Bregman bilevel optimizer (OBBO) that utilizes adaptive Bregman divergences. We demonstrate that OBBO enhances the known sublinear rates for bilevel local regret through a novel hypergradient error decomposition that adapts to the underlying geometry of the problem. In stochastic contexts, we introduce the first stochastic online bilevel optimizer (SOBBO), which employs a window averaging method for updating outer-level variables using a weighted average of recent stochastic approximations of hypergradients. This approach not only achieves sublinear rates of bilevel local regret but also serves as an effective variance reduction strategy, obviating the need for additional stochastic gradient samples at each timestep. Experiments on online hyperparameter optimization and online meta-learning highlight the superior performance, efficiency, and adaptability of our Bregman-based algorithms compared to established online and offline bilevel benchmarks.
DP-TBART: A Transformer-based Autoregressive Model for Differentially Private Tabular Data Generation
Jul 19, 2023The generation of synthetic tabular data that preserves differential privacy is a problem of growing importance. While traditional marginal-based methods have achieved impressive results, recent work has shown that deep learning-based approaches tend to lag behind. In this work, we present Differentially-Private TaBular AutoRegressive Transformer (DP-TBART), a transformer-based autoregressive model that maintains differential privacy and achieves performance competitive with marginal-based methods on a wide variety of datasets, capable of even outperforming state-of-the-art methods in certain settings. We also provide a theoretical framework for understanding the limitations of marginal-based approaches and where deep learning-based approaches stand to contribute most. These results suggest that deep learning-based techniques should be considered as a viable alternative to marginal-based methods in the generation of differentially private synthetic tabular data.
MixCE: Training Autoregressive Language Models by Mixing Forward and Reverse Cross-Entropies
May 26, 2023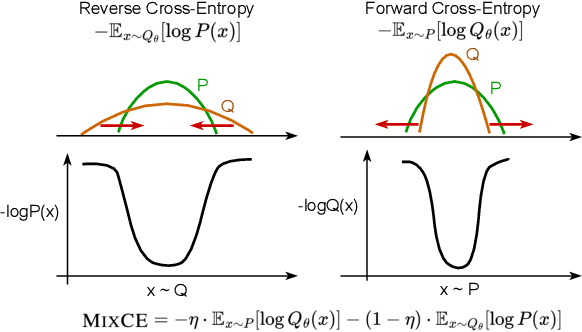
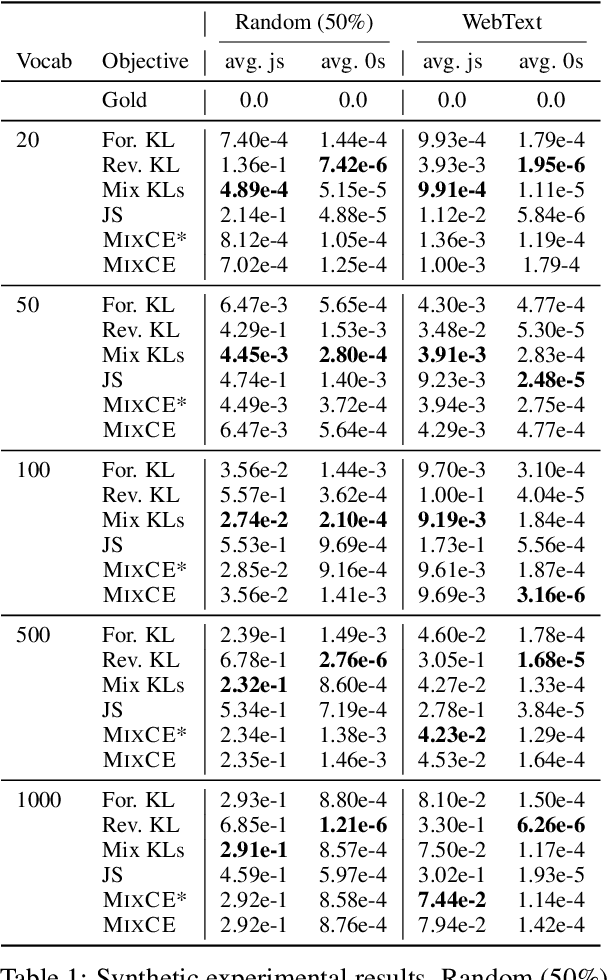
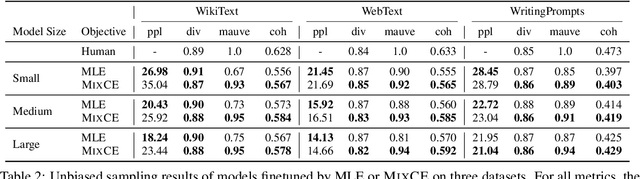
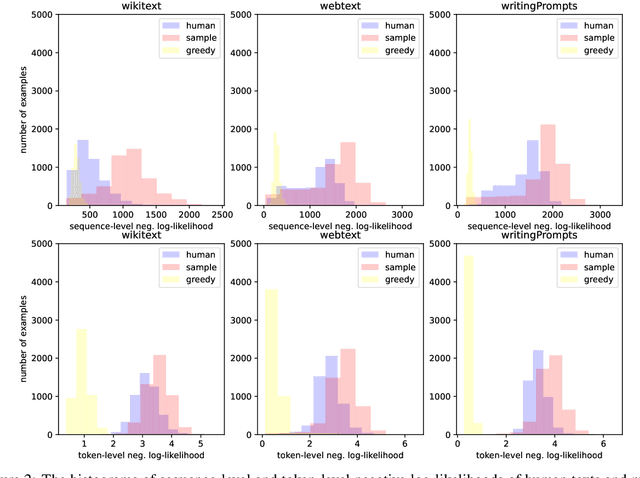
Autoregressive language models are trained by minimizing the cross-entropy of the model distribution Q relative to the data distribution P -- that is, minimizing the forward cross-entropy, which is equivalent to maximum likelihood estimation (MLE). We have observed that models trained in this way may "over-generalize", in the sense that they produce non-human-like text. Moreover, we believe that reverse cross-entropy, i.e., the cross-entropy of P relative to Q, is a better reflection of how a human would evaluate text generated by a model. Hence, we propose learning with MixCE, an objective that mixes the forward and reverse cross-entropies. We evaluate models trained with this objective on synthetic data settings (where P is known) and real data, and show that the resulting models yield better generated text without complex decoding strategies. Our code and models are publicly available at https://github.com/bloomberg/mixce-acl2023
BloombergGPT: A Large Language Model for Finance
Mar 30, 2023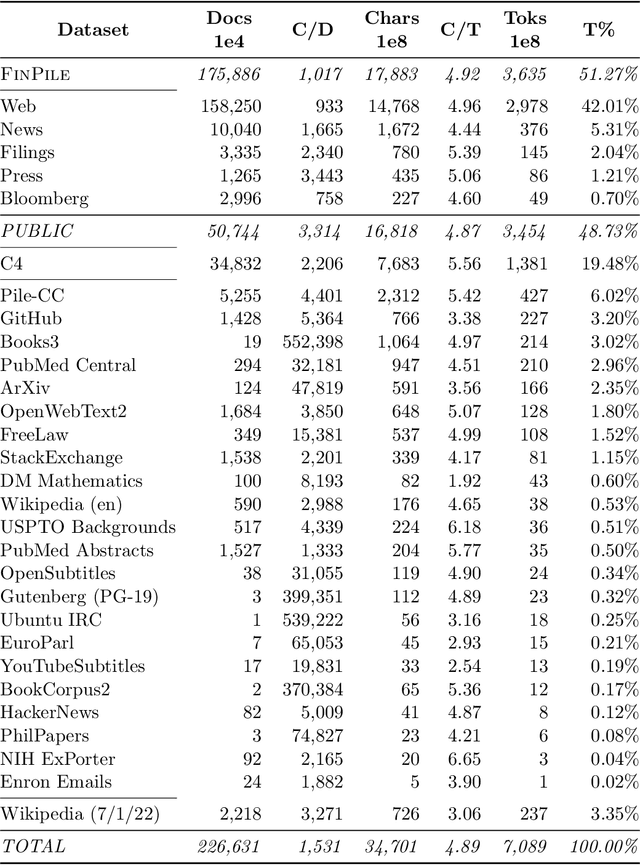
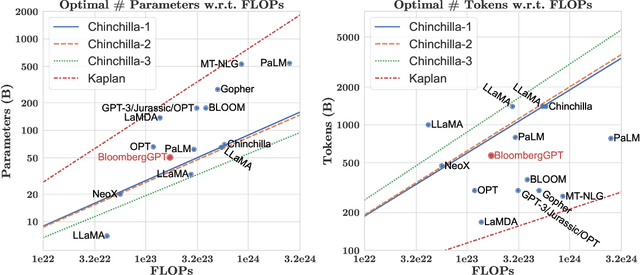
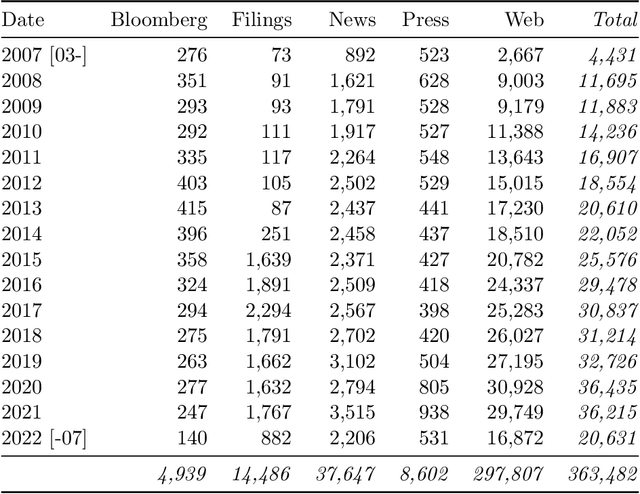
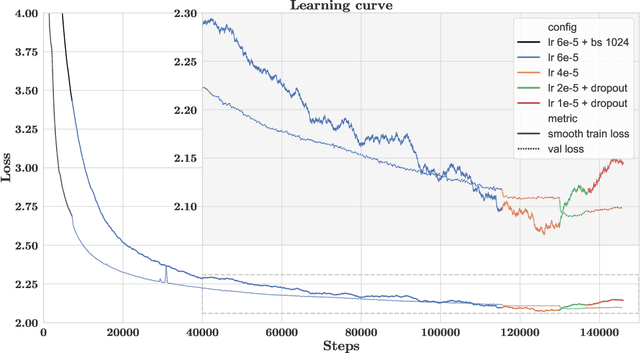
The use of NLP in the realm of financial technology is broad and complex, with applications ranging from sentiment analysis and named entity recognition to question answering. Large Language Models (LLMs) have been shown to be effective on a variety of tasks; however, no LLM specialized for the financial domain has been reported in literature. In this work, we present BloombergGPT, a 50 billion parameter language model that is trained on a wide range of financial data. We construct a 363 billion token dataset based on Bloomberg's extensive data sources, perhaps the largest domain-specific dataset yet, augmented with 345 billion tokens from general purpose datasets. We validate BloombergGPT on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that most accurately reflect our intended usage. Our mixed dataset training leads to a model that outperforms existing models on financial tasks by significant margins without sacrificing performance on general LLM benchmarks. Additionally, we explain our modeling choices, training process, and evaluation methodology. As a next step, we plan to release training logs (Chronicles) detailing our experience in training BloombergGPT.
Identifying and mitigating bias in algorithms used to manage patients in a pandemic
Oct 30, 2021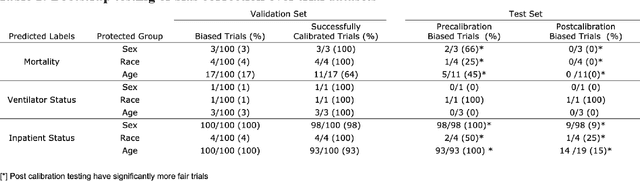
Numerous COVID-19 clinical decision support systems have been developed. However many of these systems do not have the merit for validity due to methodological shortcomings including algorithmic bias. Methods Logistic regression models were created to predict COVID-19 mortality, ventilator status and inpatient status using a real-world dataset consisting of four hospitals in New York City and analyzed for biases against race, gender and age. Simple thresholding adjustments were applied in the training process to establish more equitable models. Results Compared to the naively trained models, the calibrated models showed a 57% decrease in the number of biased trials, while predictive performance, measured by area under the receiver/operating curve (AUC), remained unchanged. After calibration, the average sensitivity of the predictive models increased from 0.527 to 0.955. Conclusion We demonstrate that naively training and deploying machine learning models on real world data for predictive analytics of COVID-19 has a high risk of bias. Simple implemented adjustments or calibrations during model training can lead to substantial and sustained gains in fairness on subsequent deployment.
Dual Reinforcement-Based Specification Generation for Image De-Rendering
Mar 02, 2021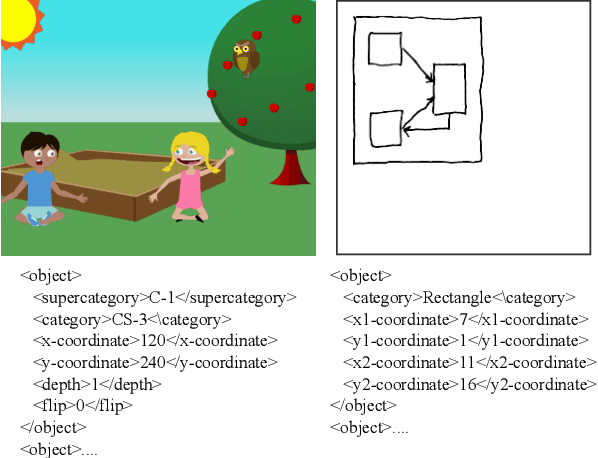
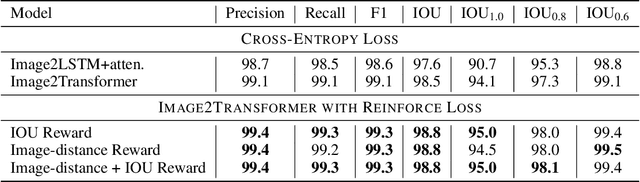
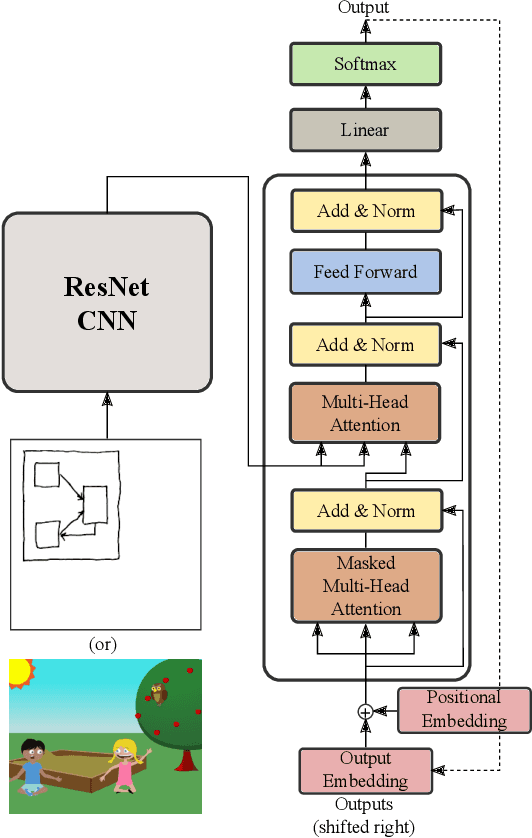
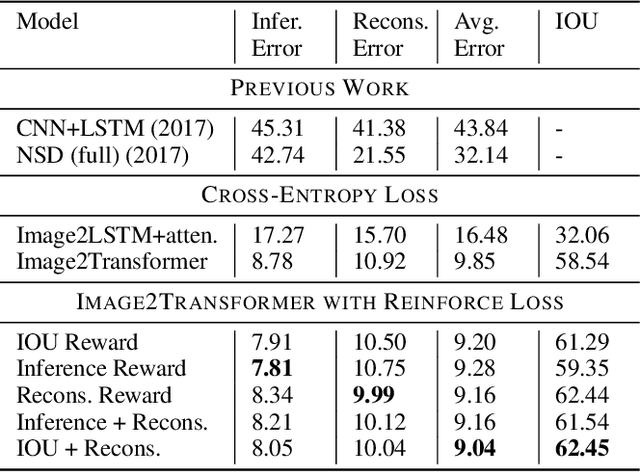
Advances in deep learning have led to promising progress in inferring graphics programs by de-rendering computer-generated images. However, current methods do not explore which decoding methods lead to better inductive bias for inferring graphics programs. In our work, we first explore the effectiveness of LSTM-RNN versus Transformer networks as decoders for order-independent graphics programs. Since these are sequence models, we must choose an ordering of the objects in the graphics programs for likelihood training. We found that the LSTM performance was highly sensitive to the sequence ordering (random order vs. pattern-based order), while Transformer performance was roughly independent of the sequence ordering. Further, we present a policy gradient based reinforcement learning approach for better inductive bias in the decoder via multiple diverse rewards based both on the graphics program specification and the rendered image. We also explore the combination of these complementary rewards. We achieve state-of-the-art results on two graphics program generation datasets.
Improving Grey-Box Fuzzing by Modeling Program Behavior
Nov 21, 2018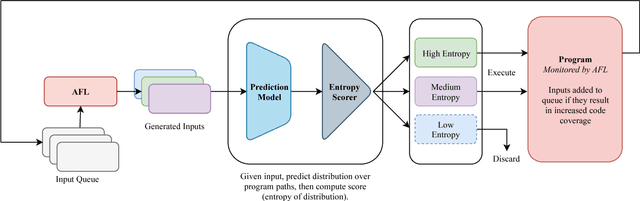

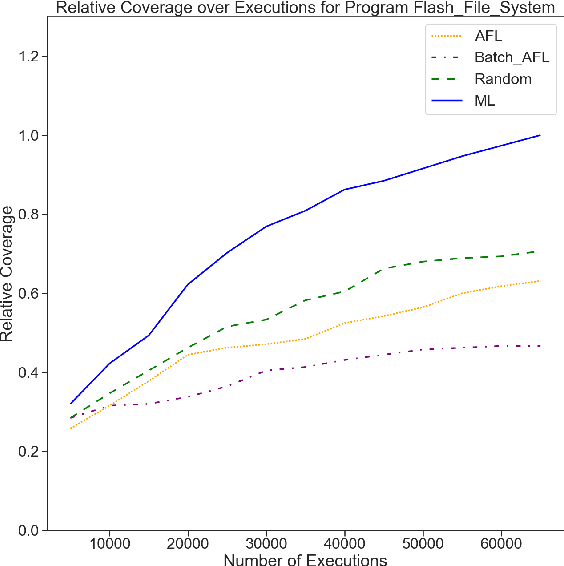
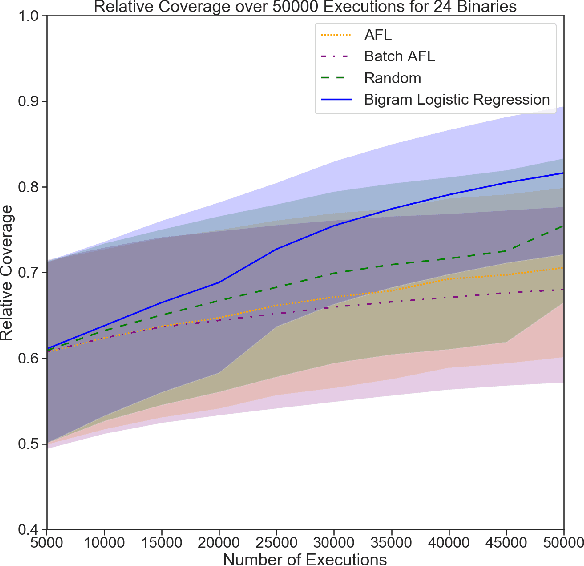
Grey-box fuzzers such as American Fuzzy Lop (AFL) are popular tools for finding bugs and potential vulnerabilities in programs. While these fuzzers have been able to find vulnerabilities in many widely used programs, they are not efficient; of the millions of inputs executed by AFL in a typical fuzzing run, only a handful discover unseen behavior or trigger a crash. The remaining inputs are redundant, exhibiting behavior that has already been observed. Here, we present an approach to increase the efficiency of fuzzers like AFL by applying machine learning to directly model how programs behave. We learn a forward prediction model that maps program inputs to execution traces, training on the thousands of inputs collected during standard fuzzing. This learned model guides exploration by focusing on fuzzing inputs on which our model is the most uncertain (measured via the entropy of the predicted execution trace distribution). By focusing on executing inputs our learned model is unsure about, and ignoring any input whose behavior our model is certain about, we show that we can significantly limit wasteful execution. Through testing our approach on a set of binaries released as part of the DARPA Cyber Grand Challenge, we show that our approach is able to find a set of inputs that result in more code coverage and discovered crashes than baseline fuzzers with significantly fewer executions.
Adaptive Grey-Box Fuzz-Testing with Thompson Sampling
Aug 24, 2018
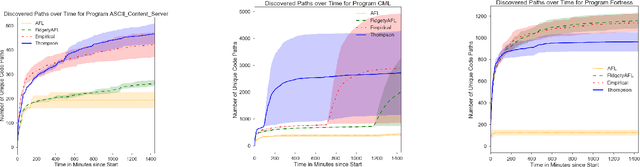
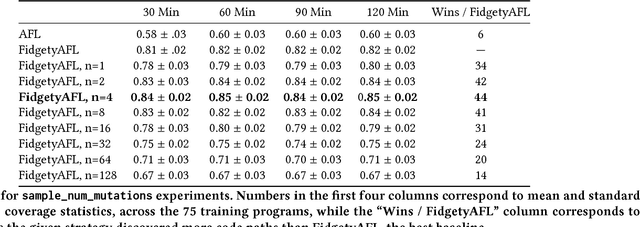
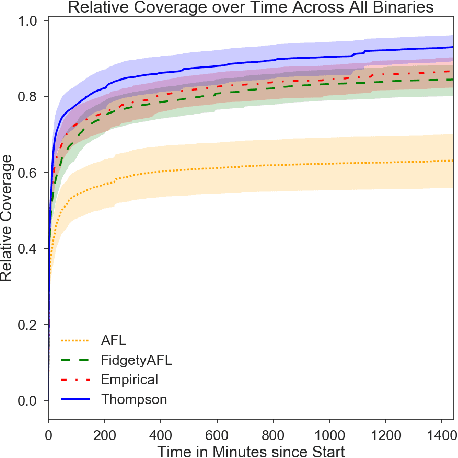
Fuzz testing, or "fuzzing," refers to a widely deployed class of techniques for testing programs by generating a set of inputs for the express purpose of finding bugs and identifying security flaws. Grey-box fuzzing, the most popular fuzzing strategy, combines light program instrumentation with a data driven process to generate new program inputs. In this work, we present a machine learning approach that builds on AFL, the preeminent grey-box fuzzer, by adaptively learning a probability distribution over its mutation operators on a program-specific basis. These operators, which are selected uniformly at random in AFL and mutational fuzzers in general, dictate how new inputs are generated, a core part of the fuzzer's efficacy. Our main contributions are two-fold: First, we show that a sampling distribution over mutation operators estimated from training programs can significantly improve performance of AFL. Second, we introduce a Thompson Sampling, bandit-based optimization approach that fine-tunes the mutator distribution adaptively, during the course of fuzzing an individual program. A set of experiments across complex programs demonstrates that tuning the mutational operator distribution generates sets of inputs that yield significantly higher code coverage and finds more crashes faster and more reliably than both baseline versions of AFL as well as other AFL-based learning approaches.