 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixCE: Training Autoregressive Language Models by Mixing Forward and Reverse Cross-Entropies
Paper and Code
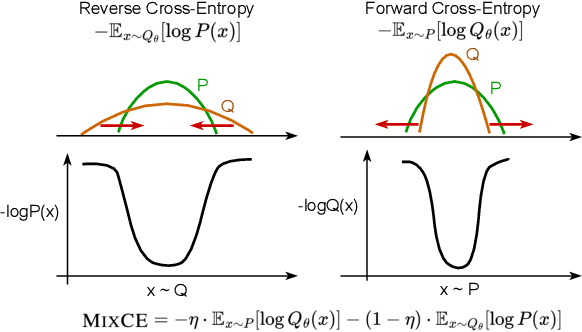
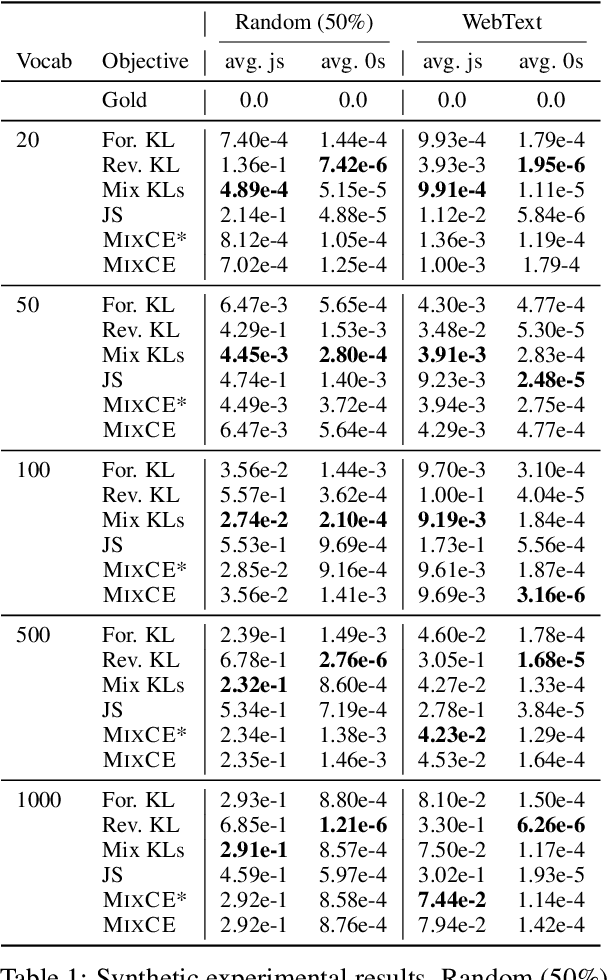
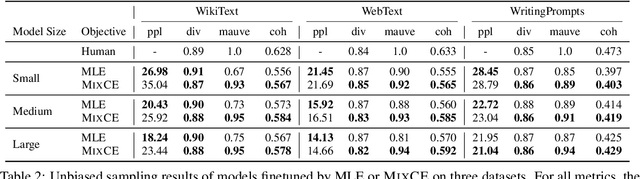
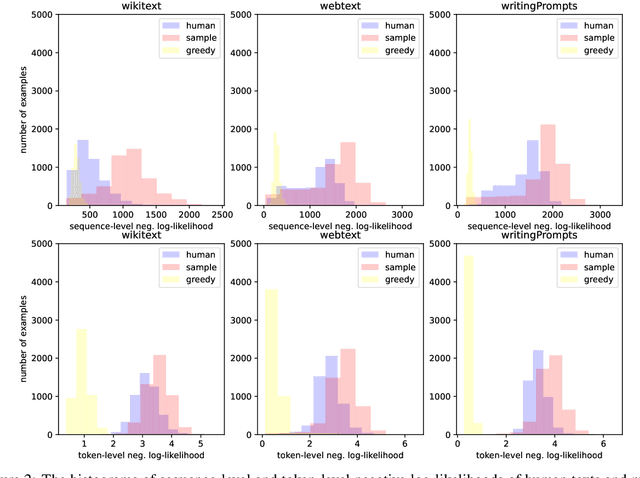
Autoregressive language models are trained by minimizing the cross-entropy of the model distribution Q relative to the data distribution P -- that is, minimizing the forward cross-entropy, which is equivalent to maximum likelihood estimation (MLE). We have observed that models trained in this way may "over-generalize", in the sense that they produce non-human-like text. Moreover, we believe that reverse cross-entropy, i.e., the cross-entropy of P relative to Q, is a better reflection of how a human would evaluate text generated by a model. Hence, we propose learning with MixCE, an objective that mixes the forward and reverse cross-entropies. We evaluate models trained with this objective on synthetic data settings (where P is known) and real data, and show that the resulting models yield better generated text without complex decoding strategies. Our code and models are publicly available at https://github.com/bloomberg/mixce-acl2023