 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3DocRAG: Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding
Nov 07, 2024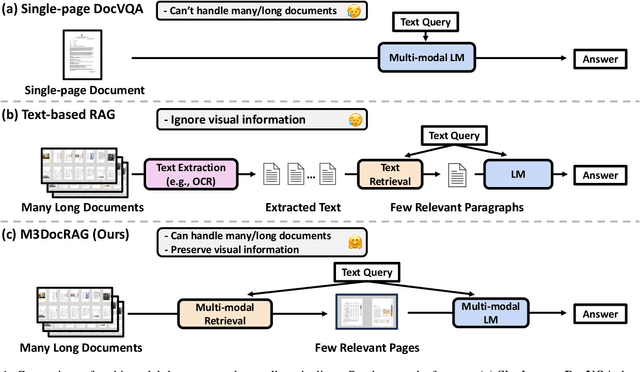
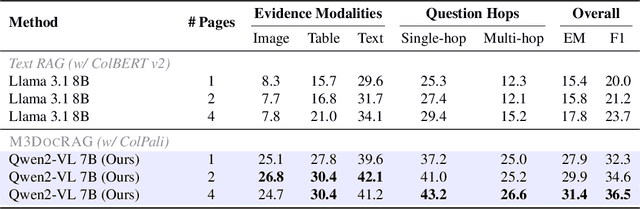
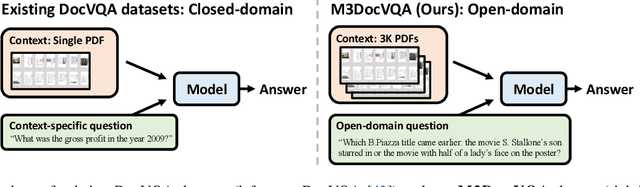
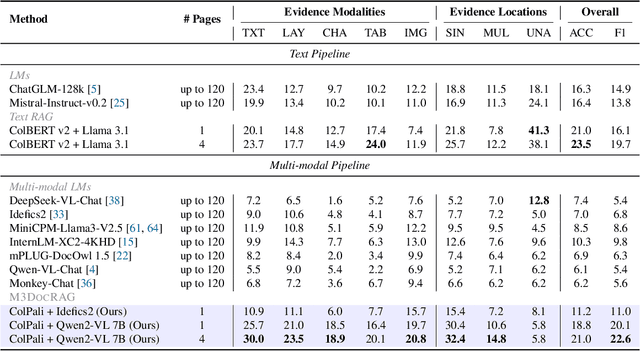
Document visual question answering (DocVQA) pipelines that answer questions from documents have broad applications. Existing methods focus on handling single-page documents with multi-modal language models (MLMs), or rely on text-based retrieval-augmented generation (RAG) that uses text extraction tools such as optical character recognition (OCR). However, there are difficulties in applying these methods in real-world scenarios: (a) questions often require information across different pages or documents, where MLMs cannot handle many long documents; (b) documents often have important information in visual elements such as figures, but text extraction tools ignore them. We introduce M3DocRAG, a novel multi-modal RAG framework that flexibly accommodates various document contexts (closed-domain and open-domain), question hops (single-hop and multi-hop), and evidence modalities (text, chart, figure, etc.). M3DocRAG finds relevant documents and answers questions using a multi-modal retriever and an MLM, so that it can efficiently handle single or many documents while preserving visual information. Since previous DocVQA datasets ask questions in the context of a specific document, we also present M3DocVQA, a new benchmark for evaluating open-domain DocVQA over 3,000+ PDF documents with 40,000+ pages. In three benchmarks (M3DocVQA/MMLongBench-Doc/MP-DocVQA), empirical results show that M3DocRAG with ColPali and Qwen2-VL 7B achieves superior performance than many strong baselines, including state-of-the-art performance in MP-DocVQA. We provide comprehensive analyses of different indexing, MLMs, and retrieval models. Lastly, we qualitatively show that M3DocRAG can successfully handle various scenarios, such as when relevant information exists across multiple pages and when answer evidence only exists in images.
MixCE: Training Autoregressive Language Models by Mixing Forward and Reverse Cross-Entropies
May 26, 2023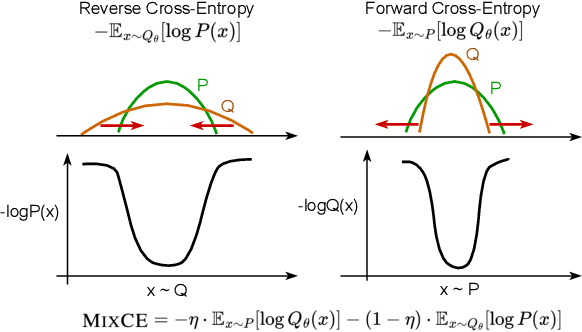
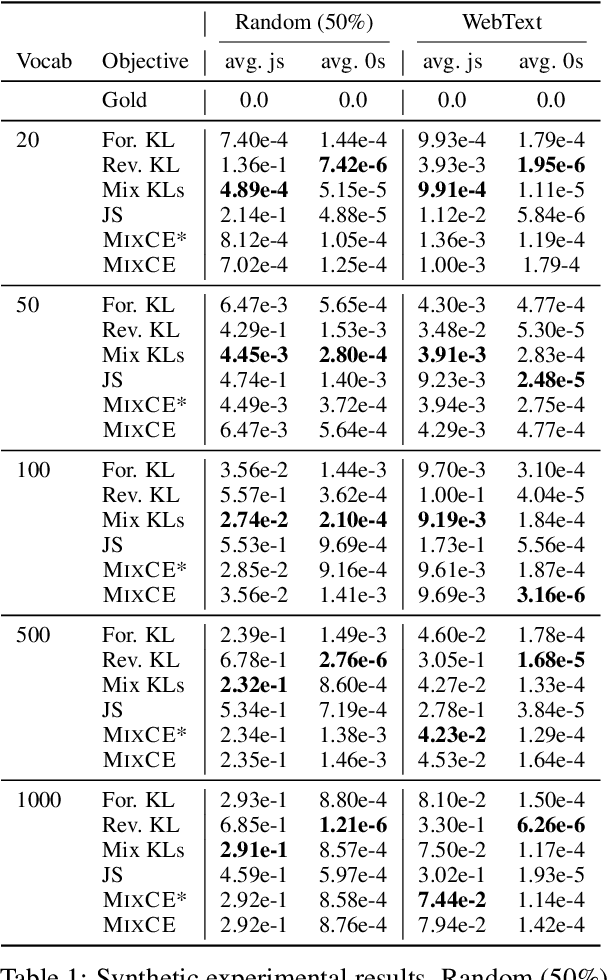
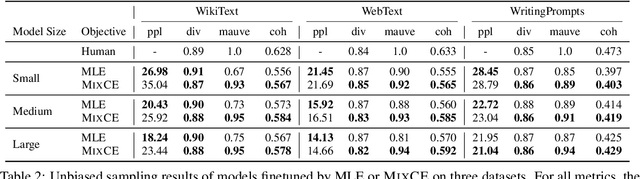
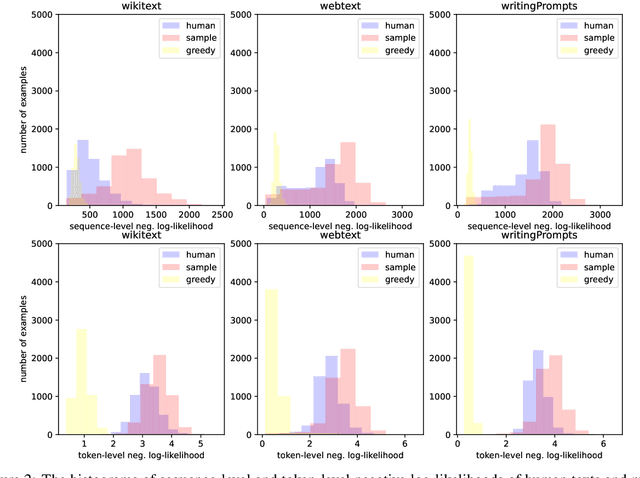
Autoregressive language models are trained by minimizing the cross-entropy of the model distribution Q relative to the data distribution P -- that is, minimizing the forward cross-entropy, which is equivalent to maximum likelihood estimation (MLE). We have observed that models trained in this way may "over-generalize", in the sense that they produce non-human-like text. Moreover, we believe that reverse cross-entropy, i.e., the cross-entropy of P relative to Q, is a better reflection of how a human would evaluate text generated by a model. Hence, we propose learning with MixCE, an objective that mixes the forward and reverse cross-entropies. We evaluate models trained with this objective on synthetic data settings (where P is known) and real data, and show that the resulting models yield better generated text without complex decoding strategies. Our code and models are publicly available at https://github.com/bloomberg/mixce-acl2023
BloombergGPT: A Large Language Model for Finance
Mar 30, 2023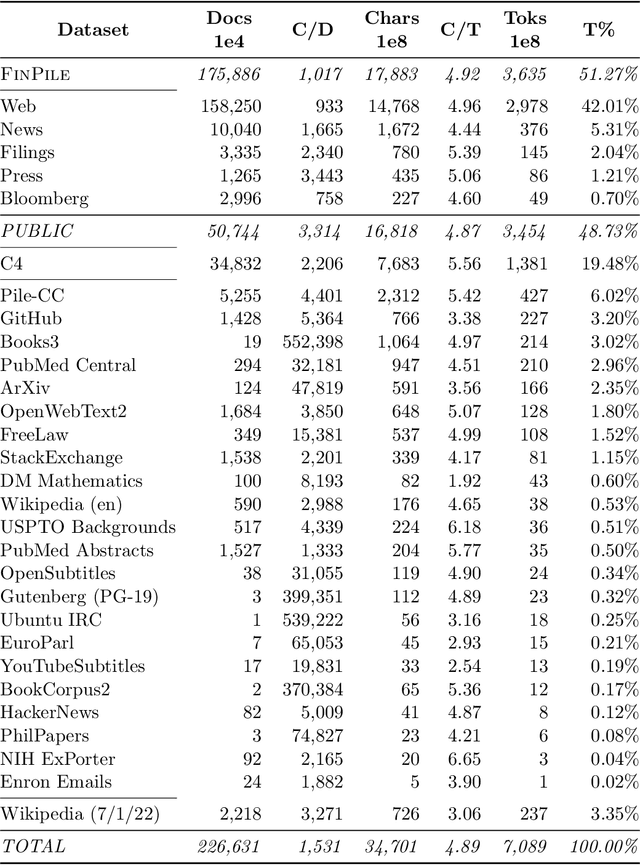
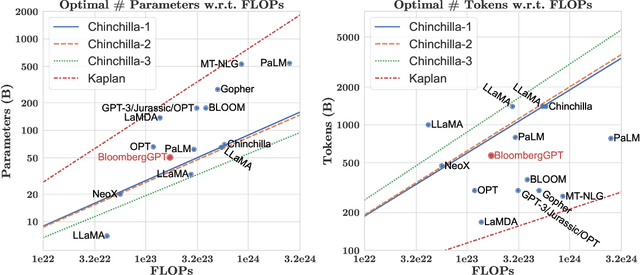
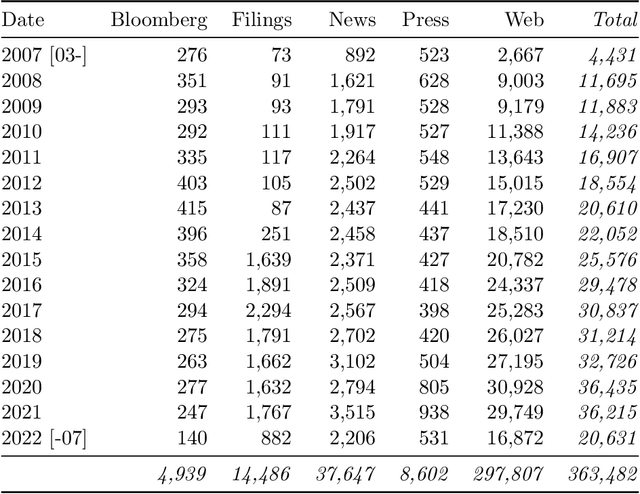
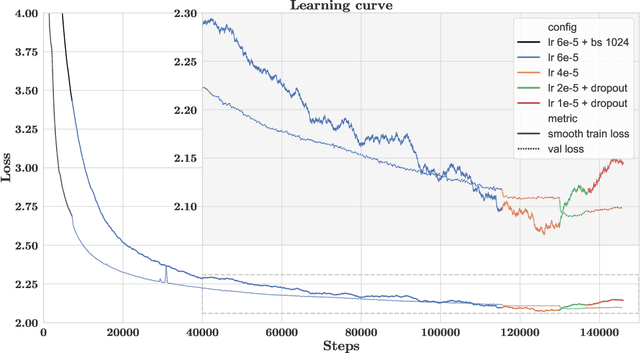
The use of NLP in the realm of financial technology is broad and complex, with applications ranging from sentiment analysis and named entity recognition to question answering. Large Language Models (LLMs) have been shown to be effective on a variety of tasks; however, no LLM specialized for the financial domain has been reported in literature. In this work, we present BloombergGPT, a 50 billion parameter language model that is trained on a wide range of financial data. We construct a 363 billion token dataset based on Bloomberg's extensive data sources, perhaps the largest domain-specific dataset yet, augmented with 345 billion tokens from general purpose datasets. We validate BloombergGPT on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that most accurately reflect our intended usage. Our mixed dataset training leads to a model that outperforms existing models on financial tasks by significant margins without sacrificing performance on general LLM benchmarks. Additionally, we explain our modeling choices, training process, and evaluation methodology. As a next step, we plan to release training logs (Chronicles) detailing our experience in training BloombergGPT.
Collective Entity Disambiguation with Structured Gradient Tree Boosting
Apr 24, 2018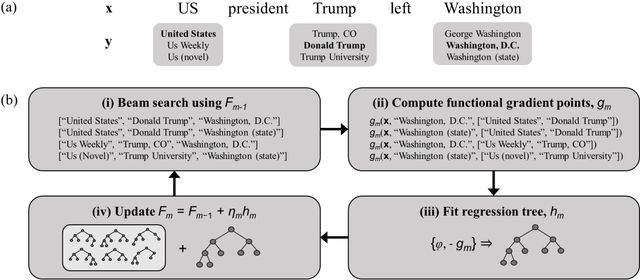


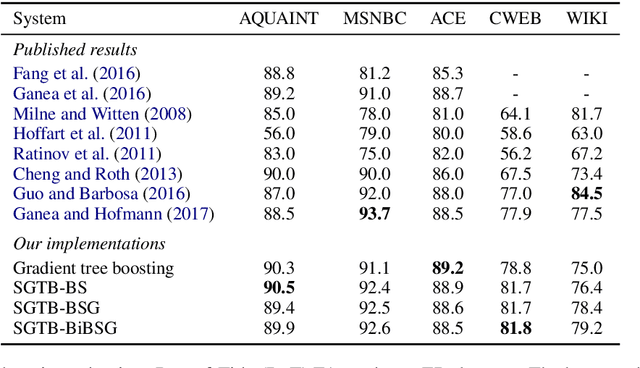
We present a gradient-tree-boosting-based structured learning model for jointly disambiguating named entities in a document. Gradient tree boosting is a widely used machine learning algorithm that underlies many top-performing natural language processing systems. Surprisingly, most works limit the use of gradient tree boosting as a tool for regular classification or regression problems, despite the structured nature of language. To the best of our knowledge, our work is the first one that employs the structured gradient tree boosting (SGTB) algorithm for collective entity disambiguation. By defining global features over previous disambiguation decisions and jointly modeling them with local features, our system is able to produce globally optimized entity assignments for mentions in a document. Exact inference is prohibitively expensive for our globally normalized model. To solve this problem, we propose Bidirectional Beam Search with Gold path (BiBSG), an approximate inference algorithm that is a variant of the standard beam search algorithm. BiBSG makes use of global information from both past and future to perform better local search. Experiments on standard benchmark datasets show that SGTB significantly improves upon published results. Specifically, SGTB outperforms the previous state-of-the-art neural system by near 1\% absolute accuracy on the popular AIDA-CoNLL dataset.
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
Mar 05, 2016
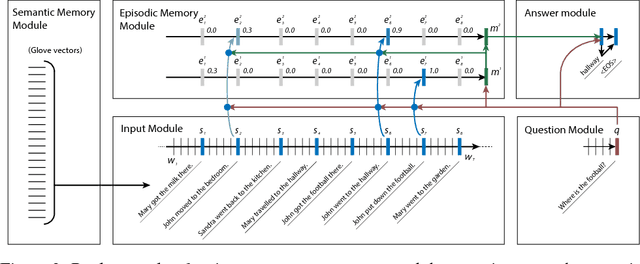
Most tasks in natural language processing can be cast into question answering (QA) problems over language input. We introduce the dynamic memory network (DMN), a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers. Questions trigger an iterative attention process which allows the model to condition its attention on the inputs and the result of previous iterations. These results are then reasoned over in a hierarchical recurrent sequence model to generate answers. The DMN can be trained end-to-end and obtains state-of-the-art results on several types of tasks and datasets: question answering (Facebook's bAbI dataset), text classification for sentiment analysis (Stanford Sentiment Treebank) and sequence modeling for part-of-speech tagging (WSJ-PTB). The training for these different tasks relies exclusively on trained word vector representations and input-question-answer triplets.