 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlove2Hand: Synthesizing Natural Hand-Object Interaction from Multi-Modal Sensing Gloves
Mar 21, 2026Understanding hand-object interaction (HOI) is fundamental to computer vision, robotics, and AR/VR. However, conventional hand videos often lack essential physical information such as contact forces and motion signals, and are prone to frequent occlusions. To address the challenges, we present Glove2Hand, a framework that translates multi-modal sensing glove HOI videos into photorealistic bare hands, while faithfully preserving the underlying physical interaction dynamics. We introduce a novel 3D Gaussian hand model that ensures temporal rendering consistency. The rendered hand is seamlessly integrated into the scene using a diffusion-based hand restorer, which effectively handles complex hand-object interactions and non-rigid deformations. Leveraging Glove2Hand, we create HandSense, the first multi-modal HOI dataset featuring glove-to-hand videos with synchronized tactile and IMU signals. We demonstrate that HandSense significantly enhances downstream bare-hand applications, including video-based contact estimation and hand tracking under severe occlusion.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
FGA: Fourier-Guided Attention Network for Crowd Count Estimation
Jul 08, 2024



Crowd counting is gaining societal relevance, particularly in domains of Urban Planning, Crowd Management, and Public Safety. This paper introduces Fourier-guided attention (FGA), a novel attention mechanism for crowd count estimation designed to address the inefficient full-scale global pattern capture in existing works on convolution-based attention networks. FGA efficiently captures multi-scale information, including full-scale global patterns, by utilizing Fast-Fourier Transformations (FFT) along with spatial attention for global features and convolutions with channel-wise attention for semi-global and local features. The architecture of FGA involves a dual-path approach: (1) a path for processing full-scale global features through FFT, allowing for efficient extraction of information in the frequency domain, and (2) a path for processing remaining feature maps for semi-global and local features using traditional convolutions and channel-wise attention. This dual-path architecture enables FGA to seamlessly integrate frequency and spatial information, enhancing its ability to capture diverse crowd patterns. We apply FGA in the last layers of two popular crowd-counting works, CSRNet and CANNet, to evaluate the module's performance on benchmark datasets such as ShanghaiTech-A, ShanghaiTech-B, UCF-CC-50, and JHU++ crowd. The experiments demonstrate a notable improvement across all datasets based on Mean-Squared-Error (MSE) and Mean-Absolute-Error (MAE) metrics, showing comparable performance to recent state-of-the-art methods. Additionally, we illustrate the interpretability using qualitative analysis, leveraging Grad-CAM heatmaps, to show the effectiveness of FGA in capturing crowd patterns.
From Text to Transformation: A Comprehensive Review of Large Language Models' Versatility
Feb 25, 2024



This groundbreaking study explores the expanse of Large Language Models (LLMs), such as Generative Pre-Trained Transformer (GPT) and Bidirectional Encoder Representations from Transformers (BERT) across varied domains ranging from technology, finance, healthcare to education. Despite their established prowess in Natural Language Processing (NLP), these LLMs have not been systematically examined for their impact on domains such as fitness, and holistic well-being, urban planning, climate modelling as well as disaster management. This review paper, in addition to furnishing a comprehensive analysis of the vast expanse and extent of LLMs' utility in diverse domains, recognizes the research gaps and realms where the potential of LLMs is yet to be harnessed. This study uncovers innovative ways in which LLMs can leave a mark in the fields like fitness and wellbeing, urban planning, climate modelling and disaster response which could inspire future researches and applications in the said avenues.
A Lightweight Feature Fusion Architecture For Resource-Constrained Crowd Counting
Jan 11, 2024Crowd counting finds direct applications in real-world situations, making computational efficiency and performance crucial. However, most of the previous methods rely on a heavy backbone and a complex downstream architecture that restricts the deployment. To address this challenge and enhance the versatility of crowd-counting models, we introduce two lightweight models. These models maintain the same downstream architecture while incorporating two distinct backbones: MobileNet and MobileViT. We leverage Adjacent Feature Fusion to extract diverse scale features from a Pre-Trained Model (PTM) and subsequently combine these features seamlessly. This approach empowers our models to achieve improved performance while maintaining a compact and efficient design. With the comparison of our proposed models with previously available state-of-the-art (SOTA) methods on ShanghaiTech-A ShanghaiTech-B and UCF-CC-50 dataset, it achieves comparable results while being the most computationally efficient model. Finally, we present a comparative study, an extensive ablation study, along with pruning to show the effectiveness of our models.
Impact of Urban Street Geometry on the Detection Probability of Automotive Radars
Dec 09, 2023

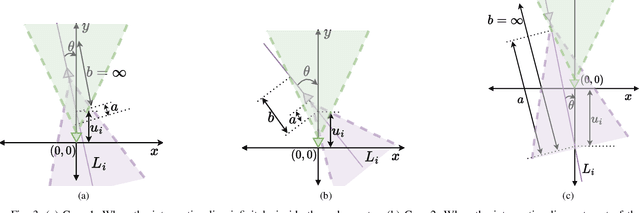
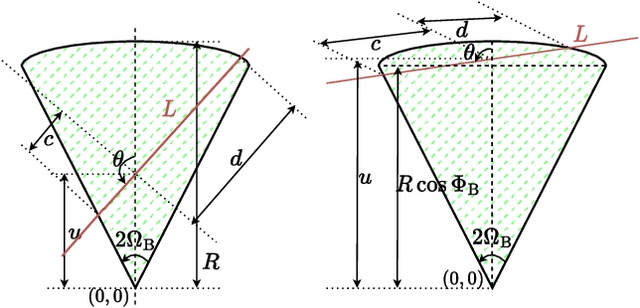
Prior works have analyzed the performance of millimeter wave automotive radars in the presence of diverse clutter and interference scenarios using stochastic geometry tools instead of more time-consuming measurement studies or system-level simulations. In these works, the distributions of radars or discrete clutter scatterers were modeled as Poisson point processes in the Euclidean space. However, since most automotive radars are likely to be mounted on vehicles and road infrastructure, road geometries are an important factor that must be considered. Instead of considering each road geometry as an individual case for study, in this work, we model each case as a specific instance of an underlying Poisson line process and further model the distribution of vehicles on the road as a Poisson point process - forming a Poisson line Cox process. Then, through the use of stochastic geometry tools, we estimate the average number of interfering radars for specific road and vehicular densities and the effect of radar parameters such as noise and beamwidth on the radar detection metrics. The numerical results are validated with Monte Carlo simulations.
From Simulations to Reality: Enhancing Multi-Robot Exploration for Urban Search and Rescue
Nov 28, 2023



In this study, we present a novel hybrid algorithm, combining Levy Flight (LF) and Particle Swarm Optimization (PSO) (LF-PSO), tailored for efficient multi-robot exploration in unknown environments with limited communication and no global positioning information. The research addresses the growing interest in employing multiple autonomous robots for exploration tasks, particularly in scenarios such as Urban Search and Rescue (USAR) operations. Multiple robots offer advantages like increased task coverage, robustness, flexibility, and scalability. However, existing approaches often make assumptions such as search area, robot positioning, communication restrictions, and target information that may not hold in real-world situations. The hybrid algorithm leverages LF, known for its effectiveness in large space exploration with sparse targets, and incorporates inter-robot repulsion as a social component through PSO. This combination enhances area exploration efficiency. We redefine the local best and global best positions to suit scenarios without continuous target information. Experimental simulations in a controlled environment demonstrate the algorithm's effectiveness, showcasing improved area coverage compared to traditional methods. In the process of refining our approach and testing it in complex, obstacle-rich environments, the presented work holds promise for enhancing multi-robot exploration in scenarios with limited information and communication capabilities.
Context-aware 6D Pose Estimation of Known Objects using RGB-D data
Dec 11, 2022



6D object pose estimation has been a research topic in the field of computer vision and robotics. Many modern world applications like robot grasping, manipulation, autonomous navigation etc, require the correct pose of objects present in a scene to perform their specific task. It becomes even harder when the objects are placed in a cluttered scene and the level of occlusion is high. Prior works have tried to overcome this problem but could not achieve accuracy that can be considered reliable in real-world applications. In this paper, we present an architecture that, unlike prior work, is context-aware. It utilizes the context information available to us about the objects. Our proposed architecture treats the objects separately according to their types i.e; symmetric and non-symmetric. A deeper estimator and refiner network pair is used for non-symmetric objects as compared to symmetric due to their intrinsic differences. Our experiments show an enhancement in the accuracy of about 3.2% over the LineMOD dataset, which is considered a benchmark for pose estimation in the occluded and cluttered scenes, against the prior state-of-the-art DenseFusion. Our results also show that the inference time we got is sufficient for real-time usage.
Noisy Text Data: Achilles' Heel of popular transformer based NLP models
Oct 07, 2021



In the last few years, the ML community has created a number of new NLP models based on transformer architecture. These models have shown great performance for various NLP tasks on benchmark datasets, often surpassing SOTA results. Buoyed with this success, one often finds industry practitioners actively experimenting with fine-tuning these models to build NLP applications for industry use cases. However, for most datasets that are used by practitioners to build industrial NLP applications, it is hard to guarantee the presence of any noise in the data. While most transformer based NLP models have performed exceedingly well in transferring the learnings from one dataset to another, it remains unclear how these models perform when fine-tuned on noisy text. We address the open question by Kumar et al. (2020) to explore the sensitivity of popular transformer based NLP models to noise in the text data. We continue working with the noise as defined by them -- spelling mistakes & typos (which are the most commonly occurring noise). We show (via experimental results) that these models perform badly on most common NLP tasks namely text classification, textual similarity, NER, question answering, text summarization on benchmark datasets. We further show that as the noise in data increases, the performance degrades. Our findings suggest that one must be vary of the presence of noise in their datasets while fine-tuning popular transformer based NLP models.
Mondegreen: A Post-Processing Solution to Speech Recognition Error Correction for Voice Search Queries
May 20, 2021
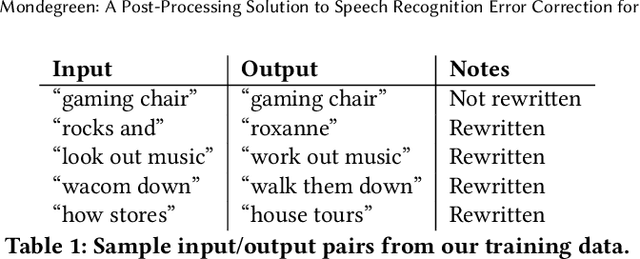


As more and more online search queries come from voice, automatic speech recognition becomes a key component to deliver relevant search results. Errors introduced by automatic speech recognition (ASR) lead to irrelevant search results returned to the user, thus causing user dissatisfaction. In this paper, we introduce an approach, Mondegreen, to correct voice queries in text space without depending on audio signals, which may not always be available due to system constraints or privacy or bandwidth (for example, some ASR systems run on-device) considerations. We focus on voice queries transcribed via several proprietary commercial ASR systems. These queries come from users making internet, or online service search queries. We first present an analysis showing how different the language distribution coming from user voice queries is from that in traditional text corpora used to train off-the-shelf ASR systems. We then demonstrate that Mondegreen can achieve significant improvements in increased user interaction by correcting user voice queries in one of the largest search systems in Google. Finally, we see Mondegreen as complementing existing highly-optimized production ASR systems, which may not be frequently retrained and thus lag behind due to vocabulary drifts.