 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware 6D Pose Estimation of Known Objects using RGB-D data
Dec 11, 2022



6D object pose estimation has been a research topic in the field of computer vision and robotics. Many modern world applications like robot grasping, manipulation, autonomous navigation etc, require the correct pose of objects present in a scene to perform their specific task. It becomes even harder when the objects are placed in a cluttered scene and the level of occlusion is high. Prior works have tried to overcome this problem but could not achieve accuracy that can be considered reliable in real-world applications. In this paper, we present an architecture that, unlike prior work, is context-aware. It utilizes the context information available to us about the objects. Our proposed architecture treats the objects separately according to their types i.e; symmetric and non-symmetric. A deeper estimator and refiner network pair is used for non-symmetric objects as compared to symmetric due to their intrinsic differences. Our experiments show an enhancement in the accuracy of about 3.2% over the LineMOD dataset, which is considered a benchmark for pose estimation in the occluded and cluttered scenes, against the prior state-of-the-art DenseFusion. Our results also show that the inference time we got is sufficient for real-time usage.
Development of Human Motion Prediction Strategy using Inception Residual Block
Aug 09, 2021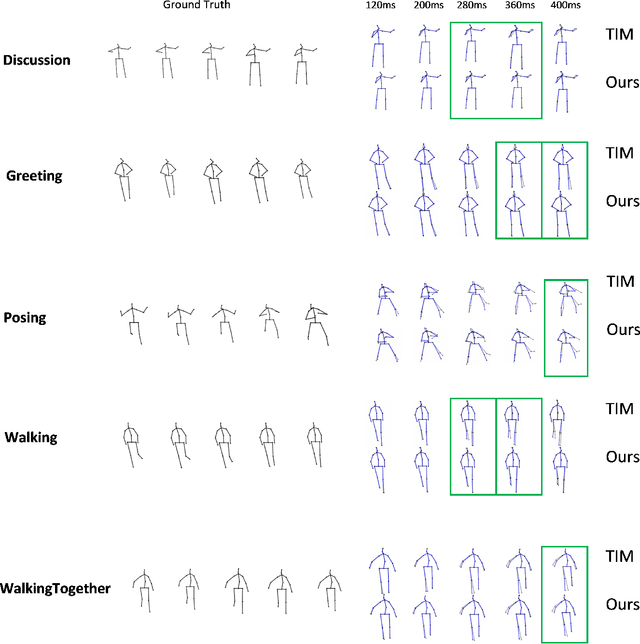
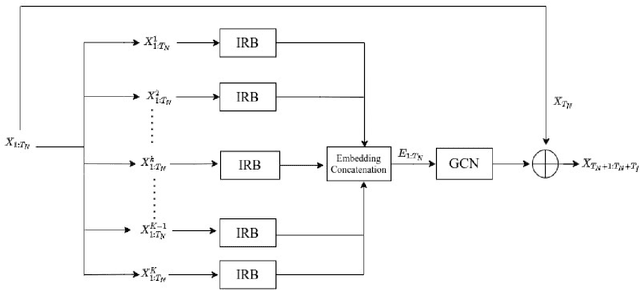
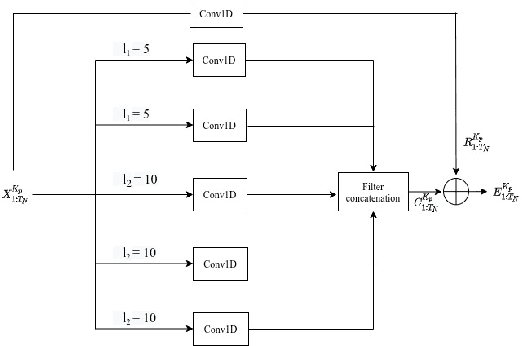
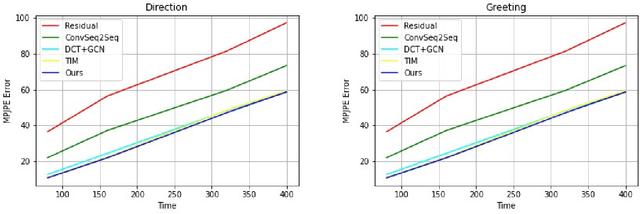
Human Motion Prediction is a crucial task in computer vision and robotics. It has versatile application potentials such as in the area of human-robot interactions, human action tracking for airport security systems, autonomous car navigation, computer gaming to name a few. However, predicting human motion based on past actions is an extremely challenging task due to the difficulties in detecting spatial and temporal features correctly. To detect temporal features in human poses, we propose an Inception Residual Block(IRB), due to its inherent capability of processing multiple kernels to capture salient features. Here, we propose to use multiple 1-D Convolution Neural Network (CNN) with different kernel sizes and input sequence lengths and concatenate them to get proper embedding. As kernels strides over different receptive fields, they detect smaller and bigger salient features at multiple temporal scales. Our main contribution is to propose a residual connection between input and the output of the inception block to have a continuity between the previously observed pose and the next predicted pose. With this proposed architecture, it learns prior knowledge much better about human poses and we achieve much higher prediction accuracy as detailed in the paper. Subsequently, we further propose to feed the output of the inception residual block as an input to the Graph Convolution Neural Network (GCN) due to its better spatial feature learning capability. We perform a parametric analysis for better designing of our model and subsequently, we evaluate our approach on the Human 3.6M dataset and compare our short-term as well as long-term predictions with the state of the art papers, where our model outperforms most of the pose results, the detailed reasons of which have been elaborated in the paper.
GI-NNet \& RGI-NNet: Development of Robotic Grasp Pose Models, Trainable with Large as well as Limited Labelled Training Datasets, under supervised and semi supervised paradigms
Jul 15, 2021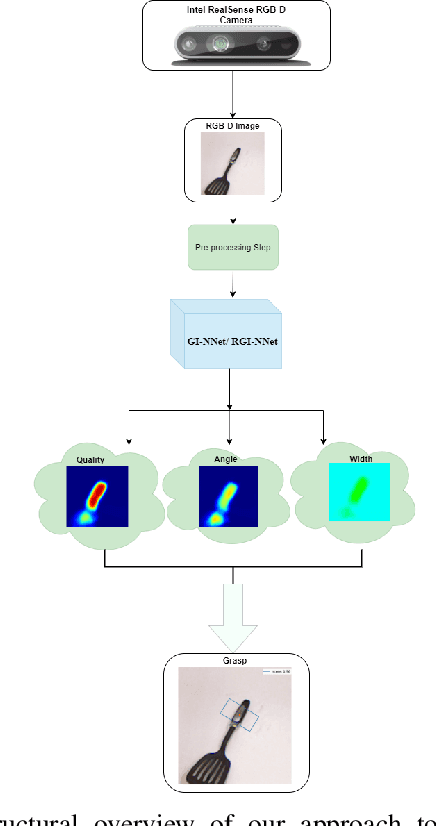
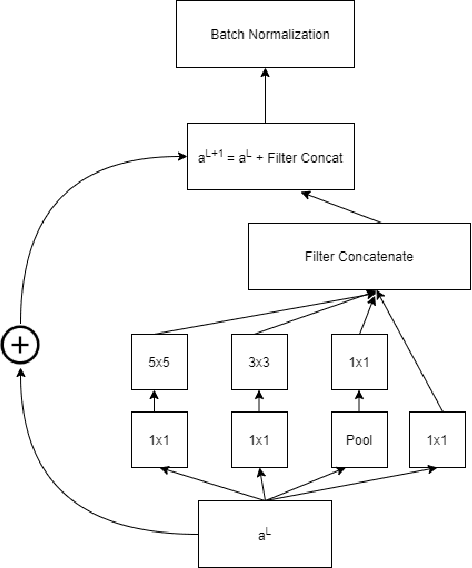

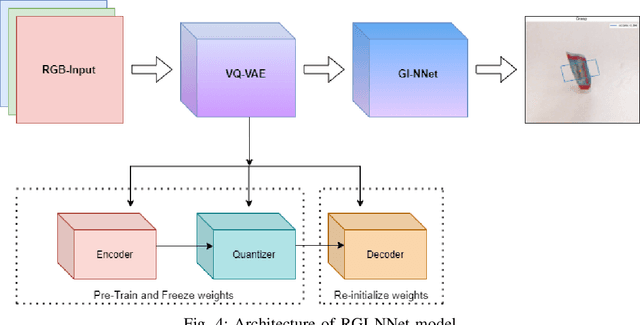
Our way of grasping objects is challenging for efficient, intelligent and optimal grasp by COBOTs. To streamline the process, here we use deep learning techniques to help robots learn to generate and execute appropriate grasps quickly. We developed a Generative Inception Neural Network (GI-NNet) model, capable of generating antipodal robotic grasps on seen as well as unseen objects. It is trained on Cornell Grasping Dataset (CGD) and attained 98.87% grasp pose accuracy for detecting both regular and irregular shaped objects from RGB-Depth (RGB-D) images while requiring only one third of the network trainable parameters as compared to the existing approaches. However, to attain this level of performance the model requires the entire 90% of the available labelled data of CGD keeping only 10% labelled data for testing which makes it vulnerable to poor generalization. Furthermore, getting sufficient and quality labelled dataset is becoming increasingly difficult keeping in pace with the requirement of gigantic networks. To address these issues, we attach our model as a decoder with a semi-supervised learning based architecture known as Vector Quantized Variational Auto Encoder (VQVAE), which works efficiently when trained both with the available labelled and unlabelled data. The proposed model, which we name as Representation based GI-NNet (RGI-NNet), has been trained with various splits of label data on CGD with as minimum as 10% labelled dataset together with latent embedding generated from VQVAE up to 50% labelled data with latent embedding obtained from VQVAE. The performance level, in terms of grasp pose accuracy of RGI-NNet, varies between 92.13% to 95.6% which is far better than several existing models trained with only labelled dataset. For the performance verification of both GI-NNet and RGI-NNet models, we use Anukul (Baxter) hardware cobot.
Human Gait State Prediction Using Cellular Automata and Classification Using ELM
May 08, 2021In this research article, we have reported periodic cellular automata rules for different gait state prediction and classification of the gait data using extreme machine Leaning (ELM). This research is the first attempt to use cellular automaton to understand the complexity of bipedal walk. Due to nonlinearity, varying configurations throughout the gait cycle and the passive joint located at the unilateral foot-ground contact in bipedal walk resulting variation of dynamic descriptions and control laws from phase to phase for human gait is making difficult to predict the bipedal walk states. We have designed the cellular automata rules which will predict the next gait state of bipedal steps based on the previous two neighbour states. We have designed cellular automata rules for normal walk. The state prediction will help to correctly design the bipedal walk. The normal walk depends on next two states and has total 8 states. We have considered the current and previous states to predict next state. So we have formulated 16 rules using cellular automata, 8 rules for each leg. The priority order maintained using the fact that if right leg in swing phase then left leg will be in stance phase. To validate the model we have classified the gait Data using ELM [1] and achieved accuracy 60%. We have explored the trajectories and compares with another gait trajectories. Finally we have presented the error analysis for different joints.
Robotic Grasp Manipulation Using Evolutionary Computing and Deep Reinforcement Learning
Jan 15, 2020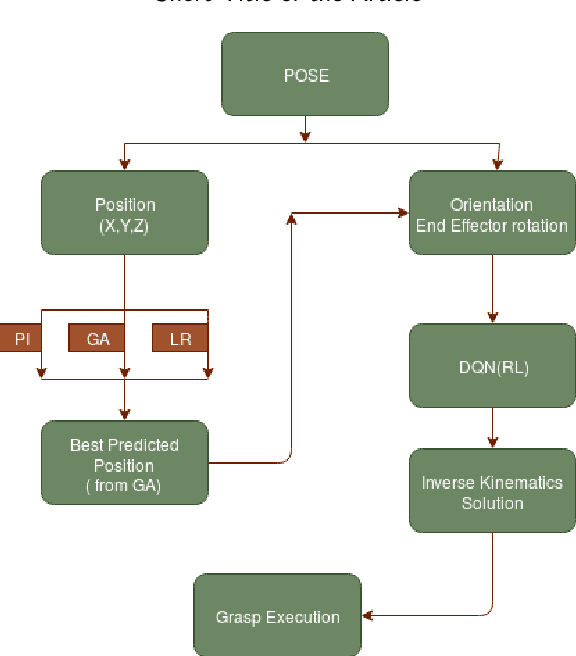
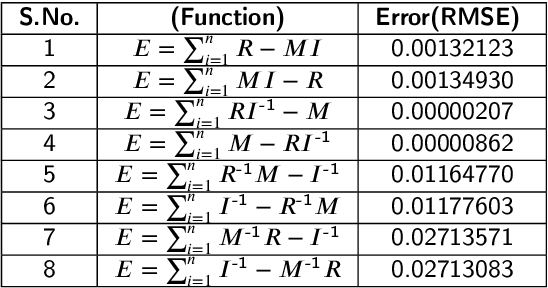
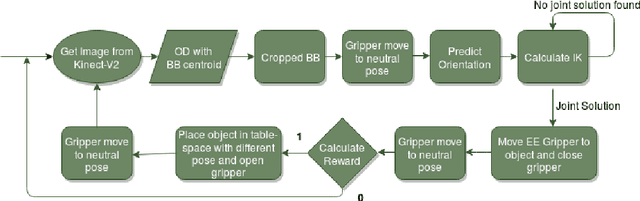

Intelligent Object manipulation for grasping is a challenging problem for robots. Unlike robots, humans almost immediately know how to manipulate objects for grasping due to learning over the years. A grown woman can grasp objects more skilfully than a child because of learning skills developed over years, the absence of which in the present day robotic grasping compels it to perform well below the human object grasping benchmarks. In this paper we have taken up the challenge of developing learning based pose estimation by decomposing the problem into both position and orientation learning. More specifically, for grasp position estimation, we explore three different methods - a Genetic Algorithm (GA) based optimization method to minimize error between calculated image points and predicted end-effector (EE) position, a regression based method (RM) where collected data points of robot EE and image points have been regressed with a linear model, a PseudoInverse (PI) model which has been formulated in the form of a mapping matrix with robot EE position and image points for several observations. Further for grasp orientation learning, we develop a deep reinforcement learning (DRL) model which we name as Grasp Deep Q-Network (GDQN) and benchmarked our results with Modified VGG16 (MVGG16). Rigorous experimentations show that due to inherent capability of producing very high-quality solutions for optimization problems and search problems, GA based predictor performs much better than the other two models for position estimation. For orientation learning results indicate that off policy learning through GDQN outperforms MVGG16, since GDQN architecture is specially made suitable for the reinforcement learning. Based on our proposed architectures and algorithms, the robot is capable of grasping all rigid body objects having regular shapes.
Supervised Q-walk for Learning Vector Representation of Nodes in Networks
Oct 03, 2017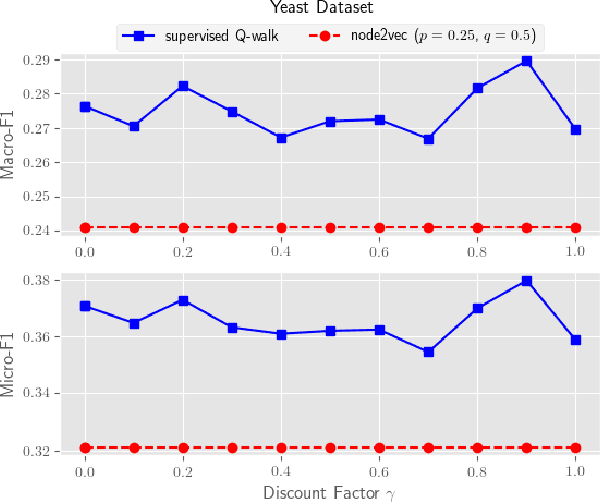
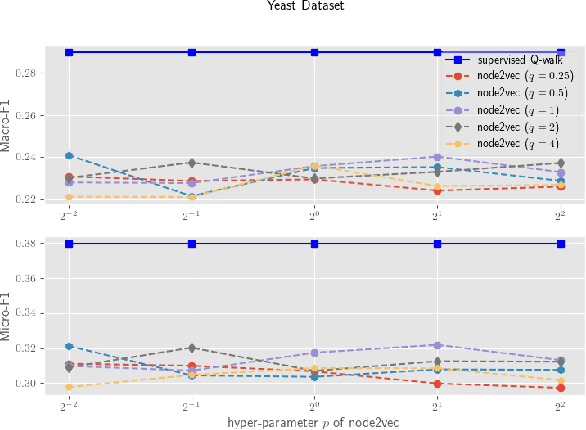
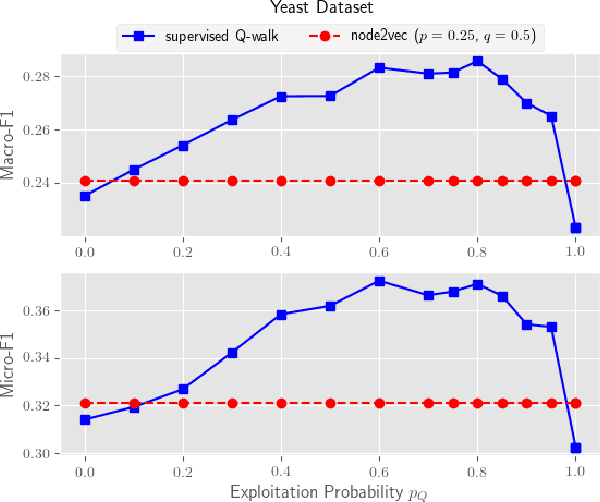
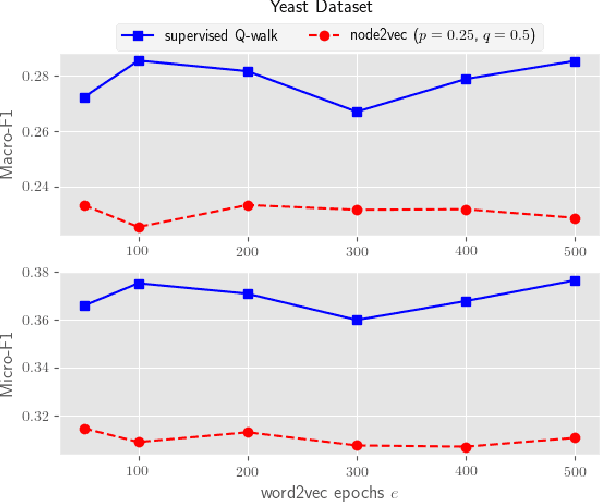
Automatic feature learning algorithms are at the forefront of modern day machine learning research. We present a novel algorithm, supervised Q-walk, which applies Q-learning to generate random walks on graphs such that the walks prove to be useful for learning node features suitable for tackling with the node classification problem. We present another novel algorithm, k-hops neighborhood based confidence values learner, which learns confidence values of labels for unlabelled nodes in the network without first learning the node embedding. These confidence values aid in learning an apt reward function for Q-learning. We demonstrate the efficacy of supervised Q-walk approach over existing state-of-the-art random walk based node embedding learners in solving the single / multi-label multi-class node classification problem using several real world datasets. Summarising, our approach represents a novel state-of-the-art technique to learn features, for nodes in networks, tailor-made for dealing with the node classification problem.
Rescue Robotics in Bore well Environment
Jun 09, 2014
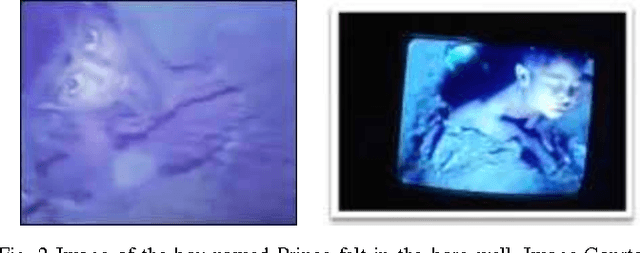


A technique for rescue task in bore well environment has been proposed. India is facing a distressed cruel situation where in the previous years a number of child deaths have been reported falling in the bore well. As the diameter of the bore well is quiet narrow for any adult person and the lights goes dark inside it, the rescue task in those situations is a challenging task. Here we are proposing a robotic system which will attach a harness to the child using pneumatic arms for picking up. A teleconferencing system will also be attached to the robot for communicating with the child.
Study of Humanoid Push Recovery Based on Experiments
May 18, 2014Human can negotiate and recovers from Push up to certain extent. The push recovery capability grows with age (a child has poor push recovery than an adult) and it is based on learning. A wrestler, for example, has better push recovery than an ordinary man. However, the mechanism of reactive push recovery is not known to us. We tried to understand the human learning mechanism by conducting several experiments. The subjects for the experiments were selected both as right handed and left handed. Pushes were induced from the behind with close eyes to observe the motor action as well as with open eyes to observe learning based reactive behaviors. Important observations show that the left handed and right handed persons negotiate pushes differently (in opposite manner). The present research describes some details about the experiments and the analyses of the results mainly obtained from the joint angle variations (both for ankle and hip joints) as the manifestation of perturbation. After smoothening the captured data through higher order polynomials, we feed them to our model which was developed exploiting the physics of an inverted pendulum and configured it as a representative of the subjects in the Webot simulation framework available in our laboratory. In each cases the model also could recover from the push for the same rage of perturbation which proves the correctness of the model. Hence the model now can provide greater insight to push recovery mechanism and can be used for determining push recovery strategy for humanoid robots. The paper claimed the push recovery is software engineering problem rather than hardware.
Bipedal Model Based on Human Gait Pattern Parameters for Sagittal Plane Movement
May 17, 2014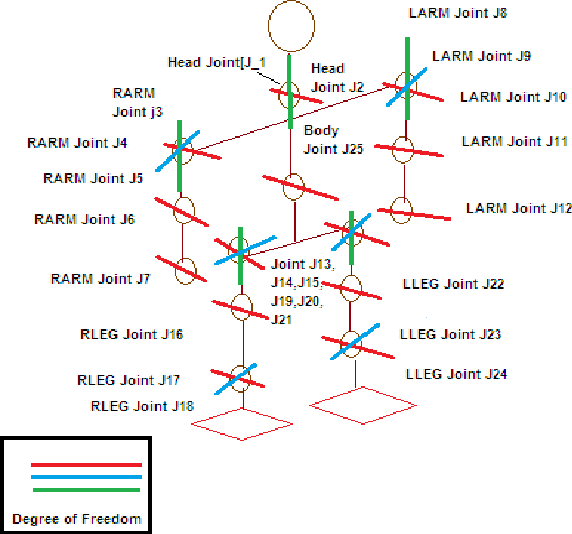



The present research as described in this paper tries to impart how imitation based learning for behavior-based programming can be used to teach the robot. This development is a big step in way to prove that push recovery is a software engineering problem and not hardware engineering problem. The walking algorithm used here aims to select a subset of push recovery problem i.e. disturbance from environment. We applied the physics at each joint of Halo with some degree of freedom. The proposed model, Halo is different from other models as previously developed model were inconsistent with data for different persons. This would lead to development of the generalized biped model in future and will bridge the gap between performance and inconsistency. In this paper the proposed model is applied to data of different persons. Accuracy of model, performance and result is measured using the behavior negotiation capability of model developed. In order to improve the performance, proposed model gives the freedom to handle each joint independently based on the belongingness value for each joint. The development can be considered as important development for future world of robotics. The accuracy of model is 70% in one go.