 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrasODM: A Dual Stream Optical Flow Mamba Network for 3D Freehand Ultrasound Reconstruction
Dec 08, 2025Clinical ultrasound acquisition is highly operator-dependent, where rapid probe motion and brightness fluctuations often lead to reconstruction errors that reduce trust and clinical utility. We present UltrasODM, a dual-stream framework that assists sonographers during acquisition through calibrated per-frame uncertainty, saliency-based diagnostics, and actionable prompts. UltrasODM integrates (i) a contrastive ranking module that groups frames by motion similarity, (ii) an optical-flow stream fused with Dual-Mamba temporal modules for robust 6-DoF pose estimation, and (iii) a Human-in-the-Loop (HITL) layer combining Bayesian uncertainty, clinician-calibrated thresholds, and saliency maps highlighting regions of low confidence. When uncertainty exceeds the threshold, the system issues unobtrusive alerts suggesting corrective actions such as re-scanning highlighted regions or slowing the sweep. Evaluated on a clinical freehand ultrasound dataset, UltrasODM reduces drift by 15.2%, distance error by 12.1%, and Hausdorff distance by 10.1% relative to UltrasOM, while producing per-frame uncertainty and saliency outputs. By emphasizing transparency and clinician feedback, UltrasODM improves reconstruction reliability and supports safer, more trustworthy clinical workflows. Our code is publicly available at https://github.com/AnandMayank/UltrasODM.
GRIM: Task-Oriented Grasping with Conditioning on Generative Examples
Jun 18, 2025



Task-Oriented Grasping (TOG) presents a significant challenge, requiring a nuanced understanding of task semantics, object affordances, and the functional constraints dictating how an object should be grasped for a specific task. To address these challenges, we introduce GRIM (Grasp Re-alignment via Iterative Matching), a novel training-free framework for task-oriented grasping. Initially, a coarse alignment strategy is developed using a combination of geometric cues and principal component analysis (PCA)-reduced DINO features for similarity scoring. Subsequently, the full grasp pose associated with the retrieved memory instance is transferred to the aligned scene object and further refined against a set of task-agnostic, geometrically stable grasps generated for the scene object, prioritizing task compatibility. In contrast to existing learning-based methods, GRIM demonstrates strong generalization capabilities, achieving robust performance with only a small number of conditioning examples.
Vision-Based Intelligent Robot Grasping Using Sparse Neural Network
Aug 22, 2023



In the modern era of Deep Learning, network parameters play a vital role in models efficiency but it has its own limitations like extensive computations and memory requirements, which may not be suitable for real time intelligent robot grasping tasks. Current research focuses on how the model efficiency can be maintained by introducing sparsity but without compromising accuracy of the model in the robot grasping domain. More specifically, in this research two light-weighted neural networks have been introduced, namely Sparse-GRConvNet and Sparse-GINNet, which leverage sparsity in the robotic grasping domain for grasp pose generation by integrating the Edge-PopUp algorithm. This algorithm facilitates the identification of the top K% of edges by considering their respective score values. Both the Sparse-GRConvNet and Sparse-GINNet models are designed to generate high-quality grasp poses in real-time at every pixel location, enabling robots to effectively manipulate unfamiliar objects. We extensively trained our models using two benchmark datasets: Cornell Grasping Dataset (CGD) and Jacquard Grasping Dataset (JGD). Both Sparse-GRConvNet and Sparse-GINNet models outperform the current state-of-the-art methods in terms of performance, achieving an impressive accuracy of 97.75% with only 10% of the weight of GR-ConvNet and 50% of the weight of GI-NNet, respectively, on CGD. Additionally, Sparse-GRConvNet achieve an accuracy of 85.77% with 30% of the weight of GR-ConvNet and Sparse-GINNet achieve an accuracy of 81.11% with 10% of the weight of GI-NNet on JGD. To validate the performance of our proposed models, we conducted extensive experiments using the Anukul (Baxter) hardware cobot.
Context-aware 6D Pose Estimation of Known Objects using RGB-D data
Dec 11, 2022



6D object pose estimation has been a research topic in the field of computer vision and robotics. Many modern world applications like robot grasping, manipulation, autonomous navigation etc, require the correct pose of objects present in a scene to perform their specific task. It becomes even harder when the objects are placed in a cluttered scene and the level of occlusion is high. Prior works have tried to overcome this problem but could not achieve accuracy that can be considered reliable in real-world applications. In this paper, we present an architecture that, unlike prior work, is context-aware. It utilizes the context information available to us about the objects. Our proposed architecture treats the objects separately according to their types i.e; symmetric and non-symmetric. A deeper estimator and refiner network pair is used for non-symmetric objects as compared to symmetric due to their intrinsic differences. Our experiments show an enhancement in the accuracy of about 3.2% over the LineMOD dataset, which is considered a benchmark for pose estimation in the occluded and cluttered scenes, against the prior state-of-the-art DenseFusion. Our results also show that the inference time we got is sufficient for real-time usage.
Generating Quality Grasp Rectangle using Pix2Pix GAN for Intelligent Robot Grasping
Feb 20, 2022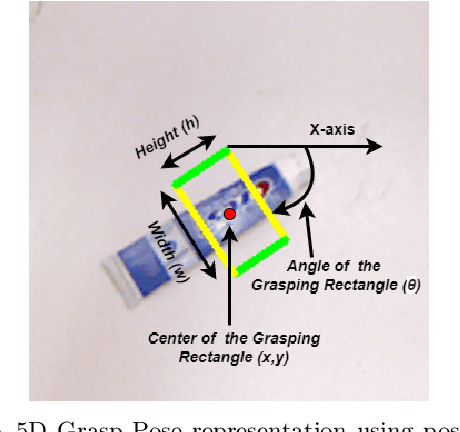
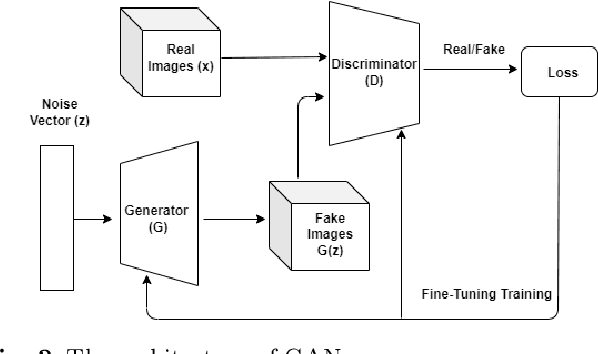
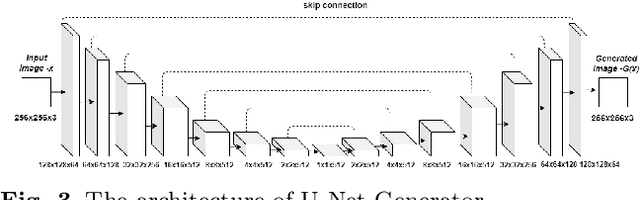
Intelligent robot grasping is a very challenging task due to its inherent complexity and non availability of sufficient labelled data. Since making suitable labelled data available for effective training for any deep learning based model including deep reinforcement learning is so crucial for successful grasp learning, in this paper we propose to solve the problem of generating grasping Poses/Rectangles using a Pix2Pix Generative Adversarial Network (Pix2Pix GAN), which takes an image of an object as input and produces the grasping rectangle tagged with the object as output. Here, we have proposed an end-to-end grasping rectangle generating methodology and embedding it to an appropriate place of an object to be grasped. We have developed two modules to obtain an optimal grasping rectangle. With the help of the first module, the pose (position and orientation) of the generated grasping rectangle is extracted from the output of Pix2Pix GAN, and then the extracted grasp pose is translated to the centroid of the object, since here we hypothesize that like the human way of grasping of regular shaped objects, the center of mass/centroids are the best places for stable grasping. For other irregular shaped objects, we allow the generated grasping rectangles as it is to be fed to the robot for grasp execution. The accuracy has significantly improved for generating the grasping rectangle with limited number of Cornell Grasping Dataset augmented by our proposed approach to the extent of 87.79%. Experiments show that our proposed generative model based approach gives the promising results in terms of executing successful grasps for seen as well as unseen objects.
GI-NNet \& RGI-NNet: Development of Robotic Grasp Pose Models, Trainable with Large as well as Limited Labelled Training Datasets, under supervised and semi supervised paradigms
Jul 15, 2021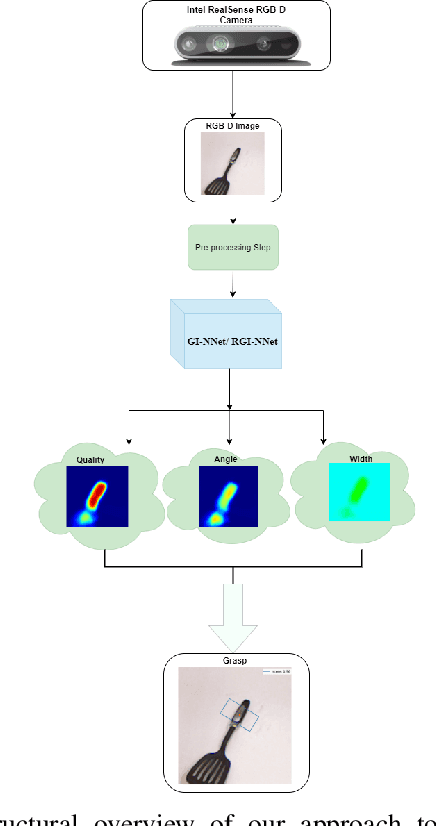
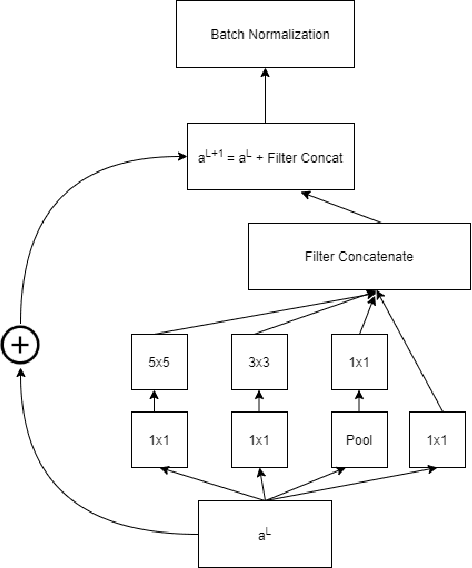

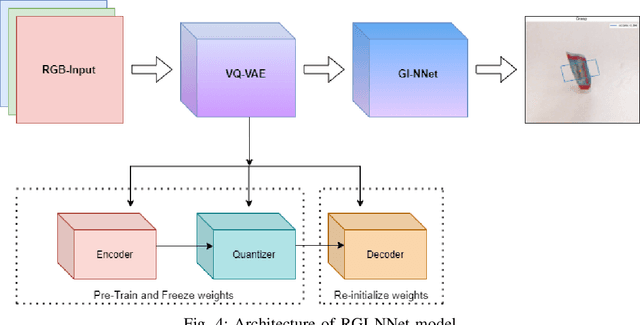
Our way of grasping objects is challenging for efficient, intelligent and optimal grasp by COBOTs. To streamline the process, here we use deep learning techniques to help robots learn to generate and execute appropriate grasps quickly. We developed a Generative Inception Neural Network (GI-NNet) model, capable of generating antipodal robotic grasps on seen as well as unseen objects. It is trained on Cornell Grasping Dataset (CGD) and attained 98.87% grasp pose accuracy for detecting both regular and irregular shaped objects from RGB-Depth (RGB-D) images while requiring only one third of the network trainable parameters as compared to the existing approaches. However, to attain this level of performance the model requires the entire 90% of the available labelled data of CGD keeping only 10% labelled data for testing which makes it vulnerable to poor generalization. Furthermore, getting sufficient and quality labelled dataset is becoming increasingly difficult keeping in pace with the requirement of gigantic networks. To address these issues, we attach our model as a decoder with a semi-supervised learning based architecture known as Vector Quantized Variational Auto Encoder (VQVAE), which works efficiently when trained both with the available labelled and unlabelled data. The proposed model, which we name as Representation based GI-NNet (RGI-NNet), has been trained with various splits of label data on CGD with as minimum as 10% labelled dataset together with latent embedding generated from VQVAE up to 50% labelled data with latent embedding obtained from VQVAE. The performance level, in terms of grasp pose accuracy of RGI-NNet, varies between 92.13% to 95.6% which is far better than several existing models trained with only labelled dataset. For the performance verification of both GI-NNet and RGI-NNet models, we use Anukul (Baxter) hardware cobot.
Semi-supervised Grasp Detection by Representation Learning in a Vector Quantized Latent Space
Jan 30, 2020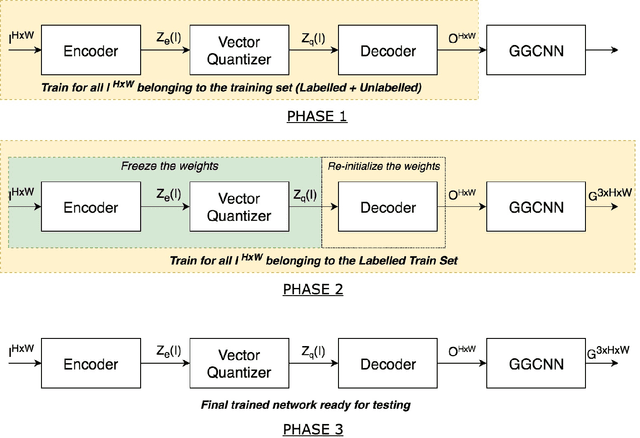
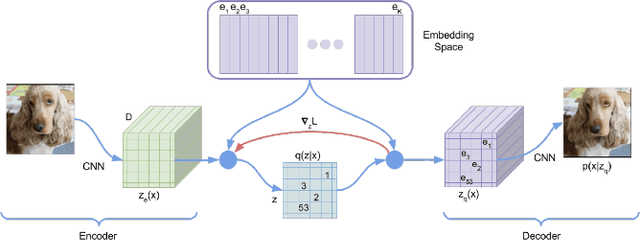
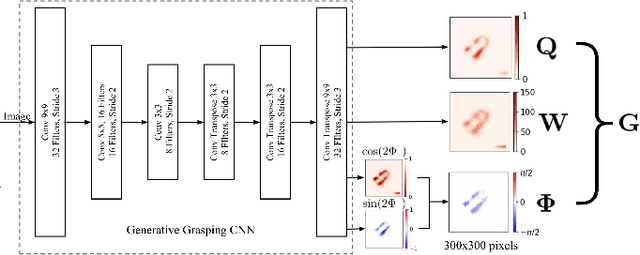
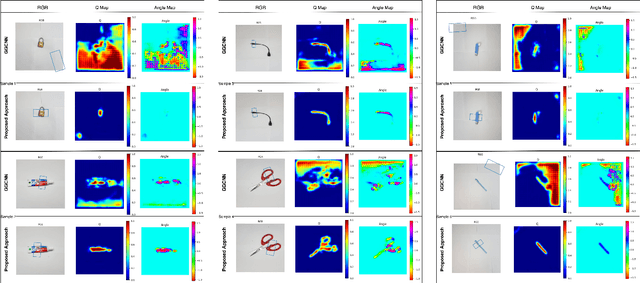
For a robot to perform complex manipulation tasks, it is necessary for it to have a good grasping ability. However, vision based robotic grasp detection is hindered by the unavailability of sufficient labelled data. Furthermore, the application of semi-supervised learning techniques to grasp detection is under-explored. In this paper, a semi-supervised learning based grasp detection approach has been presented, which models a discrete latent space using a Vector Quantized Variational AutoEncoder (VQ-VAE). To the best of our knowledge, this is the first time a Variational AutoEncoder (VAE) has been applied in the domain of robotic grasp detection. The VAE helps the model in generalizing beyond the Cornell Grasping Dataset (CGD) despite having a limited amount of labelled data by also utilizing the unlabelled data. This claim has been validated by testing the model on images, which are not available in the CGD. Along with this, we augment the Generative Grasping Convolutional Neural Network (GGCNN) architecture with the decoder structure used in the VQ-VAE model with the intuition that it should help to regress in the vector-quantized latent space. Subsequently, the model performs significantly better than the existing approaches which do not make use of unlabelled images to improve the grasp.
Robotic Grasp Manipulation Using Evolutionary Computing and Deep Reinforcement Learning
Jan 15, 2020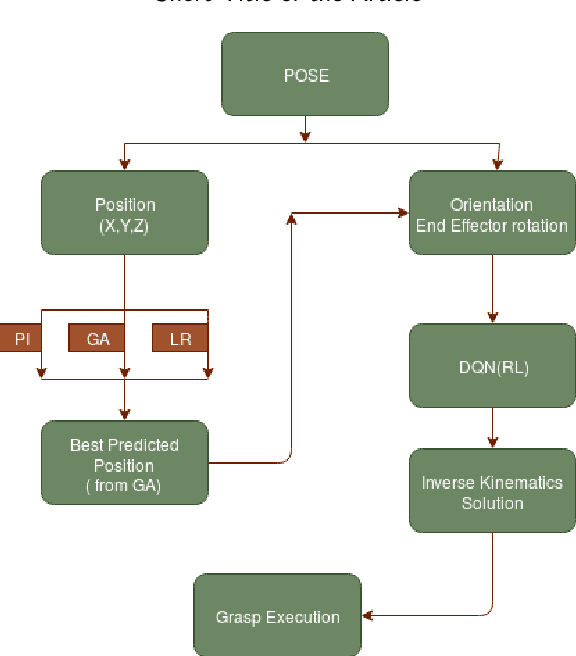
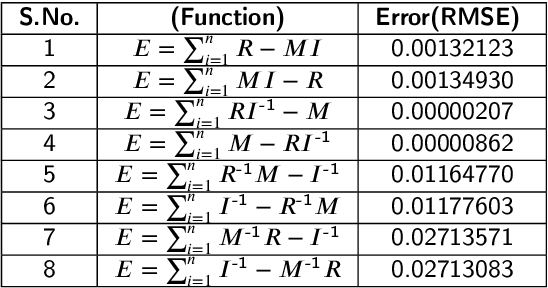
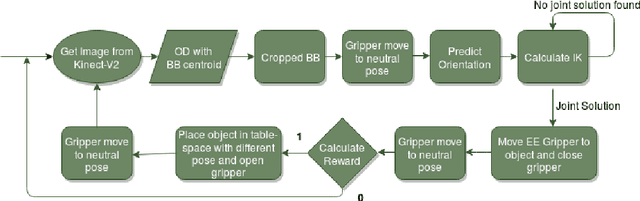

Intelligent Object manipulation for grasping is a challenging problem for robots. Unlike robots, humans almost immediately know how to manipulate objects for grasping due to learning over the years. A grown woman can grasp objects more skilfully than a child because of learning skills developed over years, the absence of which in the present day robotic grasping compels it to perform well below the human object grasping benchmarks. In this paper we have taken up the challenge of developing learning based pose estimation by decomposing the problem into both position and orientation learning. More specifically, for grasp position estimation, we explore three different methods - a Genetic Algorithm (GA) based optimization method to minimize error between calculated image points and predicted end-effector (EE) position, a regression based method (RM) where collected data points of robot EE and image points have been regressed with a linear model, a PseudoInverse (PI) model which has been formulated in the form of a mapping matrix with robot EE position and image points for several observations. Further for grasp orientation learning, we develop a deep reinforcement learning (DRL) model which we name as Grasp Deep Q-Network (GDQN) and benchmarked our results with Modified VGG16 (MVGG16). Rigorous experimentations show that due to inherent capability of producing very high-quality solutions for optimization problems and search problems, GA based predictor performs much better than the other two models for position estimation. For orientation learning results indicate that off policy learning through GDQN outperforms MVGG16, since GDQN architecture is specially made suitable for the reinforcement learning. Based on our proposed architectures and algorithms, the robot is capable of grasping all rigid body objects having regular shapes.