 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Based Intelligent Robot Grasping Using Sparse Neural Network
Aug 22, 2023



In the modern era of Deep Learning, network parameters play a vital role in models efficiency but it has its own limitations like extensive computations and memory requirements, which may not be suitable for real time intelligent robot grasping tasks. Current research focuses on how the model efficiency can be maintained by introducing sparsity but without compromising accuracy of the model in the robot grasping domain. More specifically, in this research two light-weighted neural networks have been introduced, namely Sparse-GRConvNet and Sparse-GINNet, which leverage sparsity in the robotic grasping domain for grasp pose generation by integrating the Edge-PopUp algorithm. This algorithm facilitates the identification of the top K% of edges by considering their respective score values. Both the Sparse-GRConvNet and Sparse-GINNet models are designed to generate high-quality grasp poses in real-time at every pixel location, enabling robots to effectively manipulate unfamiliar objects. We extensively trained our models using two benchmark datasets: Cornell Grasping Dataset (CGD) and Jacquard Grasping Dataset (JGD). Both Sparse-GRConvNet and Sparse-GINNet models outperform the current state-of-the-art methods in terms of performance, achieving an impressive accuracy of 97.75% with only 10% of the weight of GR-ConvNet and 50% of the weight of GI-NNet, respectively, on CGD. Additionally, Sparse-GRConvNet achieve an accuracy of 85.77% with 30% of the weight of GR-ConvNet and Sparse-GINNet achieve an accuracy of 81.11% with 10% of the weight of GI-NNet on JGD. To validate the performance of our proposed models, we conducted extensive experiments using the Anukul (Baxter) hardware cobot.
Context-aware 6D Pose Estimation of Known Objects using RGB-D data
Dec 11, 2022



6D object pose estimation has been a research topic in the field of computer vision and robotics. Many modern world applications like robot grasping, manipulation, autonomous navigation etc, require the correct pose of objects present in a scene to perform their specific task. It becomes even harder when the objects are placed in a cluttered scene and the level of occlusion is high. Prior works have tried to overcome this problem but could not achieve accuracy that can be considered reliable in real-world applications. In this paper, we present an architecture that, unlike prior work, is context-aware. It utilizes the context information available to us about the objects. Our proposed architecture treats the objects separately according to their types i.e; symmetric and non-symmetric. A deeper estimator and refiner network pair is used for non-symmetric objects as compared to symmetric due to their intrinsic differences. Our experiments show an enhancement in the accuracy of about 3.2% over the LineMOD dataset, which is considered a benchmark for pose estimation in the occluded and cluttered scenes, against the prior state-of-the-art DenseFusion. Our results also show that the inference time we got is sufficient for real-time usage.
Generating Quality Grasp Rectangle using Pix2Pix GAN for Intelligent Robot Grasping
Feb 20, 2022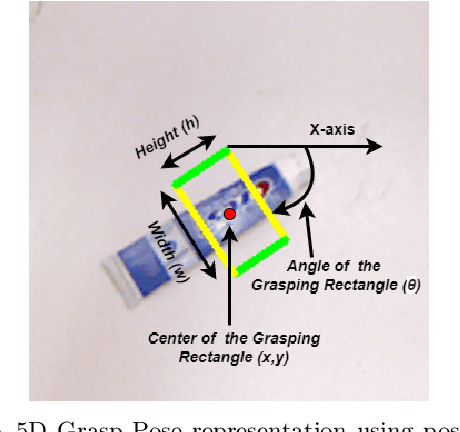
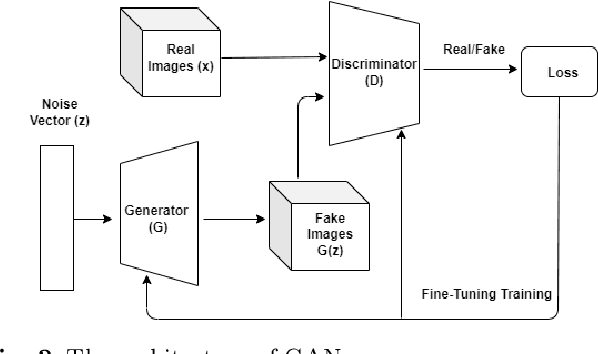
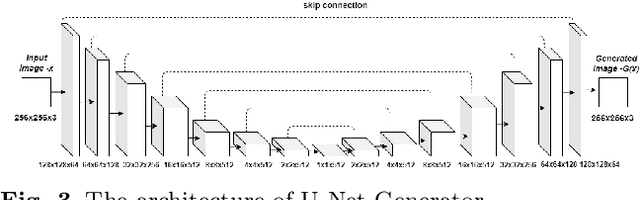
Intelligent robot grasping is a very challenging task due to its inherent complexity and non availability of sufficient labelled data. Since making suitable labelled data available for effective training for any deep learning based model including deep reinforcement learning is so crucial for successful grasp learning, in this paper we propose to solve the problem of generating grasping Poses/Rectangles using a Pix2Pix Generative Adversarial Network (Pix2Pix GAN), which takes an image of an object as input and produces the grasping rectangle tagged with the object as output. Here, we have proposed an end-to-end grasping rectangle generating methodology and embedding it to an appropriate place of an object to be grasped. We have developed two modules to obtain an optimal grasping rectangle. With the help of the first module, the pose (position and orientation) of the generated grasping rectangle is extracted from the output of Pix2Pix GAN, and then the extracted grasp pose is translated to the centroid of the object, since here we hypothesize that like the human way of grasping of regular shaped objects, the center of mass/centroids are the best places for stable grasping. For other irregular shaped objects, we allow the generated grasping rectangles as it is to be fed to the robot for grasp execution. The accuracy has significantly improved for generating the grasping rectangle with limited number of Cornell Grasping Dataset augmented by our proposed approach to the extent of 87.79%. Experiments show that our proposed generative model based approach gives the promising results in terms of executing successful grasps for seen as well as unseen objects.