 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Based Intelligent Robot Grasping Using Sparse Neural Network
Aug 22, 2023



In the modern era of Deep Learning, network parameters play a vital role in models efficiency but it has its own limitations like extensive computations and memory requirements, which may not be suitable for real time intelligent robot grasping tasks. Current research focuses on how the model efficiency can be maintained by introducing sparsity but without compromising accuracy of the model in the robot grasping domain. More specifically, in this research two light-weighted neural networks have been introduced, namely Sparse-GRConvNet and Sparse-GINNet, which leverage sparsity in the robotic grasping domain for grasp pose generation by integrating the Edge-PopUp algorithm. This algorithm facilitates the identification of the top K% of edges by considering their respective score values. Both the Sparse-GRConvNet and Sparse-GINNet models are designed to generate high-quality grasp poses in real-time at every pixel location, enabling robots to effectively manipulate unfamiliar objects. We extensively trained our models using two benchmark datasets: Cornell Grasping Dataset (CGD) and Jacquard Grasping Dataset (JGD). Both Sparse-GRConvNet and Sparse-GINNet models outperform the current state-of-the-art methods in terms of performance, achieving an impressive accuracy of 97.75% with only 10% of the weight of GR-ConvNet and 50% of the weight of GI-NNet, respectively, on CGD. Additionally, Sparse-GRConvNet achieve an accuracy of 85.77% with 30% of the weight of GR-ConvNet and Sparse-GINNet achieve an accuracy of 81.11% with 10% of the weight of GI-NNet on JGD. To validate the performance of our proposed models, we conducted extensive experiments using the Anukul (Baxter) hardware cobot.
Generating Quality Grasp Rectangle using Pix2Pix GAN for Intelligent Robot Grasping
Feb 20, 2022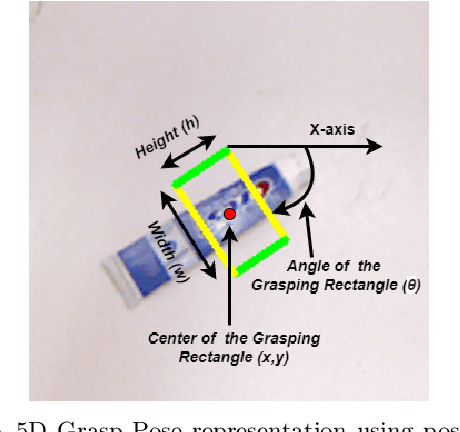
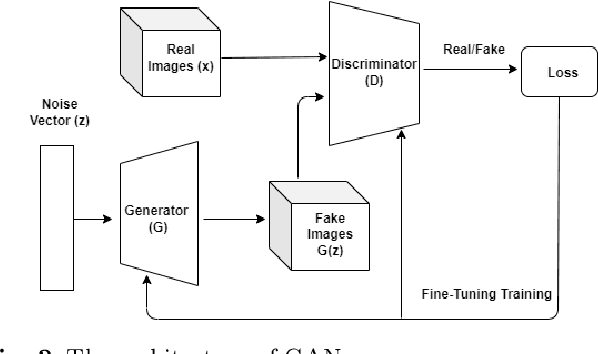
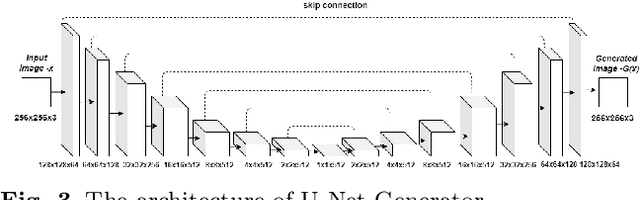
Intelligent robot grasping is a very challenging task due to its inherent complexity and non availability of sufficient labelled data. Since making suitable labelled data available for effective training for any deep learning based model including deep reinforcement learning is so crucial for successful grasp learning, in this paper we propose to solve the problem of generating grasping Poses/Rectangles using a Pix2Pix Generative Adversarial Network (Pix2Pix GAN), which takes an image of an object as input and produces the grasping rectangle tagged with the object as output. Here, we have proposed an end-to-end grasping rectangle generating methodology and embedding it to an appropriate place of an object to be grasped. We have developed two modules to obtain an optimal grasping rectangle. With the help of the first module, the pose (position and orientation) of the generated grasping rectangle is extracted from the output of Pix2Pix GAN, and then the extracted grasp pose is translated to the centroid of the object, since here we hypothesize that like the human way of grasping of regular shaped objects, the center of mass/centroids are the best places for stable grasping. For other irregular shaped objects, we allow the generated grasping rectangles as it is to be fed to the robot for grasp execution. The accuracy has significantly improved for generating the grasping rectangle with limited number of Cornell Grasping Dataset augmented by our proposed approach to the extent of 87.79%. Experiments show that our proposed generative model based approach gives the promising results in terms of executing successful grasps for seen as well as unseen objects.
Semi-supervised Grasp Detection by Representation Learning in a Vector Quantized Latent Space
Jan 30, 2020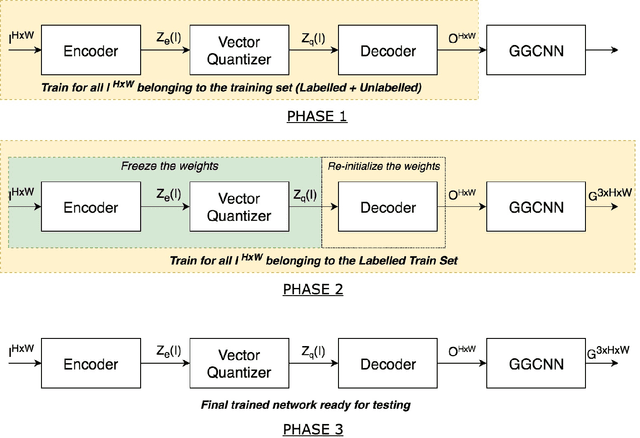
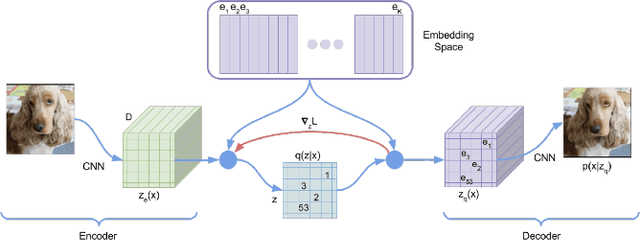
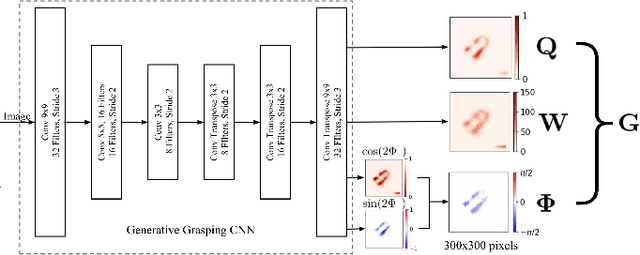
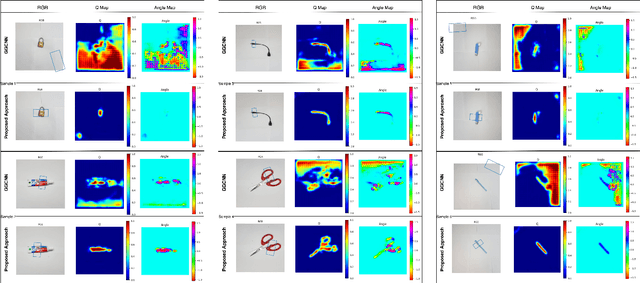
For a robot to perform complex manipulation tasks, it is necessary for it to have a good grasping ability. However, vision based robotic grasp detection is hindered by the unavailability of sufficient labelled data. Furthermore, the application of semi-supervised learning techniques to grasp detection is under-explored. In this paper, a semi-supervised learning based grasp detection approach has been presented, which models a discrete latent space using a Vector Quantized Variational AutoEncoder (VQ-VAE). To the best of our knowledge, this is the first time a Variational AutoEncoder (VAE) has been applied in the domain of robotic grasp detection. The VAE helps the model in generalizing beyond the Cornell Grasping Dataset (CGD) despite having a limited amount of labelled data by also utilizing the unlabelled data. This claim has been validated by testing the model on images, which are not available in the CGD. Along with this, we augment the Generative Grasping Convolutional Neural Network (GGCNN) architecture with the decoder structure used in the VQ-VAE model with the intuition that it should help to regress in the vector-quantized latent space. Subsequently, the model performs significantly better than the existing approaches which do not make use of unlabelled images to improve the grasp.
Development of a Fuzzy Expert System based Liveliness Detection Scheme for Biometric Authentication
Sep 17, 2016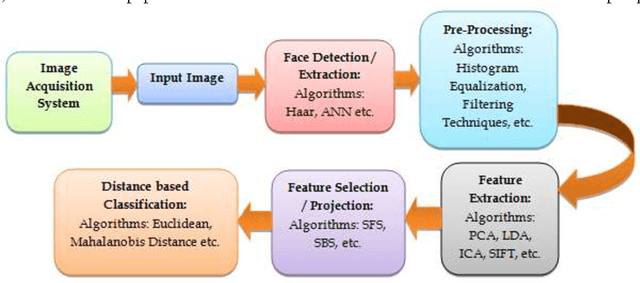


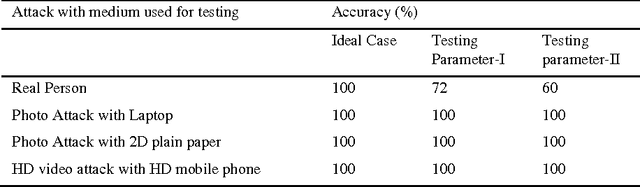
Liveliness detection acts as a safe guard against spoofing attacks. Most of the researchers used vision based techniques to detect liveliness of the user, but they are highly sensitive to illumination effects. Therefore it is very hard to design a system, which will work robustly under all circumstances. Literature shows that most of the research utilize eye blink or mouth movement to detect the liveliness, while the other group used face texture to distinguish between real and imposter. The classification results of all these approaches decreases drastically in variable light conditions. Hence in this paper we are introducing fuzzy expert system which is sufficient enough to handle most of the cases comes in real time. We have used two testing parameters, (a) under bad illumination and (b) less movement in eyes and mouth in case of real user to evaluate the performance of the system. The system is behaving well in all, while in first case its False Rejection Rate (FRR) is 0.28, and in second case its FRR is 0.4.