 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Grasp Detection by Representation Learning in a Vector Quantized Latent Space
Jan 30, 2020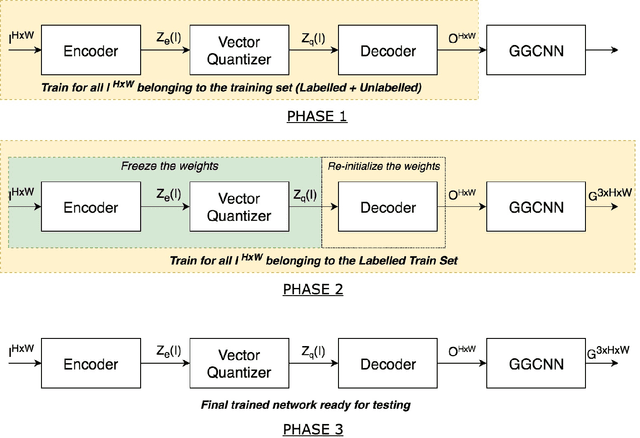
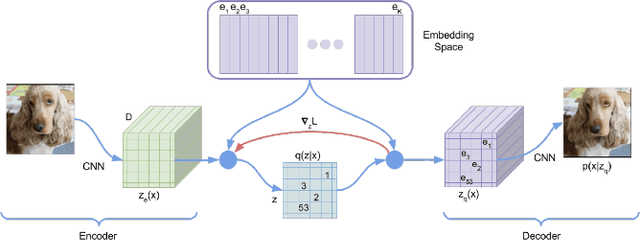
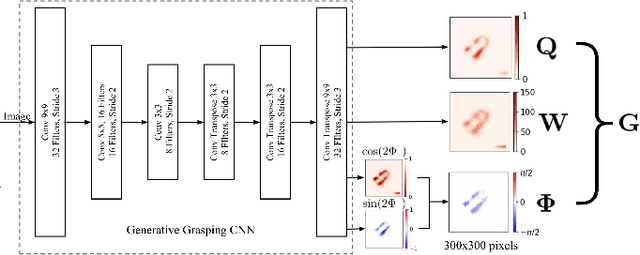
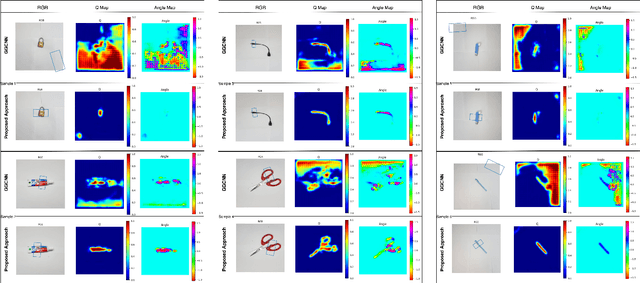
For a robot to perform complex manipulation tasks, it is necessary for it to have a good grasping ability. However, vision based robotic grasp detection is hindered by the unavailability of sufficient labelled data. Furthermore, the application of semi-supervised learning techniques to grasp detection is under-explored. In this paper, a semi-supervised learning based grasp detection approach has been presented, which models a discrete latent space using a Vector Quantized Variational AutoEncoder (VQ-VAE). To the best of our knowledge, this is the first time a Variational AutoEncoder (VAE) has been applied in the domain of robotic grasp detection. The VAE helps the model in generalizing beyond the Cornell Grasping Dataset (CGD) despite having a limited amount of labelled data by also utilizing the unlabelled data. This claim has been validated by testing the model on images, which are not available in the CGD. Along with this, we augment the Generative Grasping Convolutional Neural Network (GGCNN) architecture with the decoder structure used in the VQ-VAE model with the intuition that it should help to regress in the vector-quantized latent space. Subsequently, the model performs significantly better than the existing approaches which do not make use of unlabelled images to improve the grasp.