 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFINCH: Financial Intelligence using Natural language for Contextualized SQL Handling
Oct 02, 2025Text-to-SQL, the task of translating natural language questions into SQL queries, has long been a central challenge in NLP. While progress has been significant, applying it to the financial domain remains especially difficult due to complex schema, domain-specific terminology, and high stakes of error. Despite this, there is no dedicated large-scale financial dataset to advance research, creating a critical gap. To address this, we introduce a curated financial dataset (FINCH) comprising 292 tables and 75,725 natural language-SQL pairs, enabling both fine-tuning and rigorous evaluation. Building on this resource, we benchmark reasoning models and language models of varying scales, providing a systematic analysis of their strengths and limitations in financial Text-to-SQL tasks. Finally, we propose a finance-oriented evaluation metric (FINCH Score) that captures nuances overlooked by existing measures, offering a more faithful assessment of model performance.
EnK: Encoding time-information in convolution
Jun 07, 2020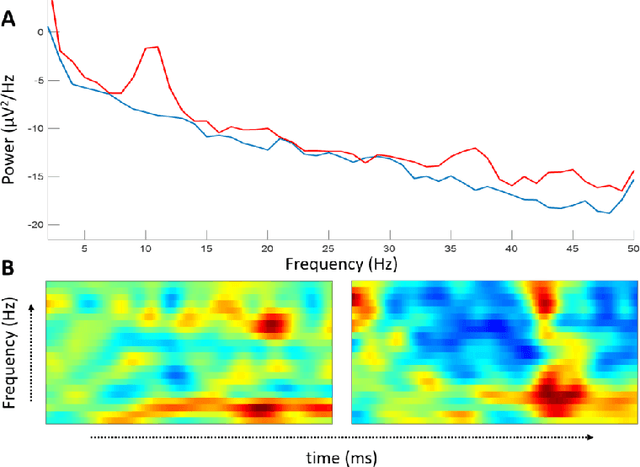

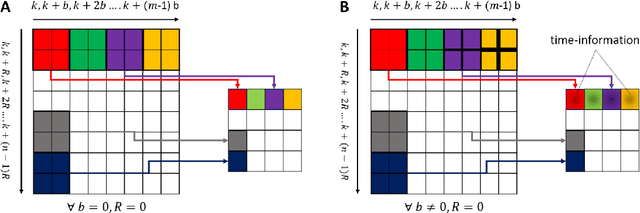
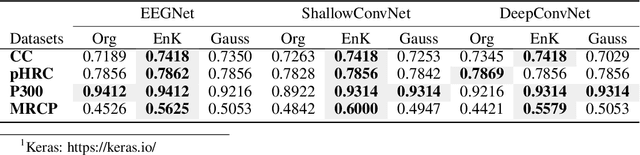
Recent development in deep learning techniques has attracted attention in decoding and classification in EEG signals. Despite several efforts utilizing different features of EEG signals, a significant research challenge is to use time-dependent features in combination with local and global features. There have been several efforts to remodel the deep learning convolution neural networks (CNNs) to capture time-dependency information by incorporating hand-crafted features, slicing the input data in a smaller time-windows, and recurrent convolution. However, these approaches partially solve the problem, but simultaneously hinder the CNN's capability to learn from unknown information that might be present in the data. To solve this, we have proposed a novel time encoding kernel (EnK) approach, which introduces the increasing time information during convolution operation in CNN. The encoded information by EnK lets CNN learn time-dependent features in-addition to local and global features. We performed extensive experiments on several EEG datasets: cognitive conflict (CC), physical-human robot collaboration (pHRC), P300 visual-evoked potentials, movement-related cortical potentials (MRCP). EnK outperforms the state-of-art by 12\% (F1 score). Moreover, the EnK approach required only one additional parameter to learn and can be applied to a virtually any CNN architectures with minimal efforts. These results support our methodology and show high potential to improve CNN performance in the context of time-series data in general.
Conflict Detection and Resolution in Table Top Scenarios for Human-Robot Interaction
Dec 29, 2019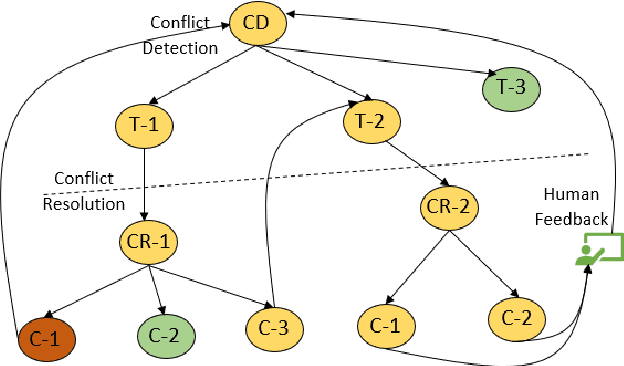

As in any interaction process, misunderstandings, ambiguity, and failures to correctly understand the interaction partner are bound to happen in human-robot interaction. We term these failures 'conflicts' and are interested in both conflict detection and conflict resolution. In that, we focus on the robot's perspective. For the robot, conflicts may occur because of errors in its perceptual processes or because of ambiguity stemming from human input. This poster presents a brief system overview, and details Here, we briefly outline the project's motivation and setting, introduce the general processing framework, and then present two kinds of conflicts in some more detail: 1) a failure to identify a relevant object at all; 2) ambiguity emerging from multiple matches in scene perception.
On effective human robot interaction based on recognition and association
Dec 08, 2018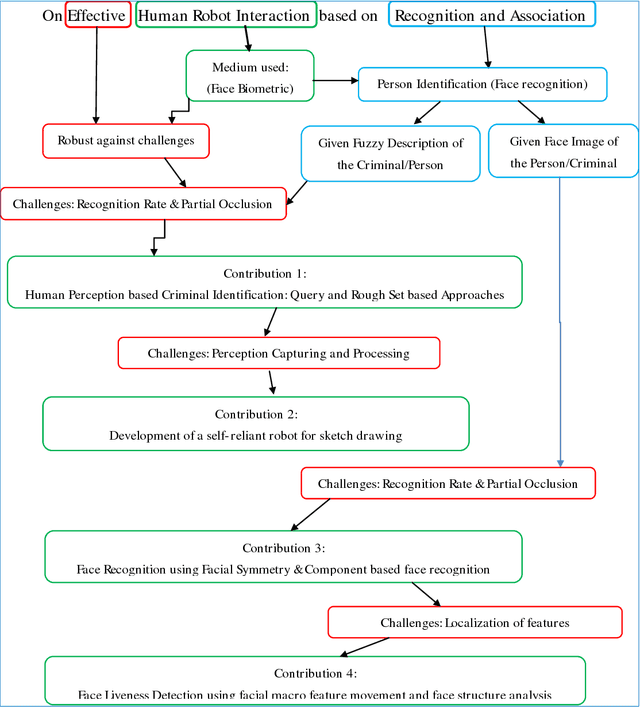

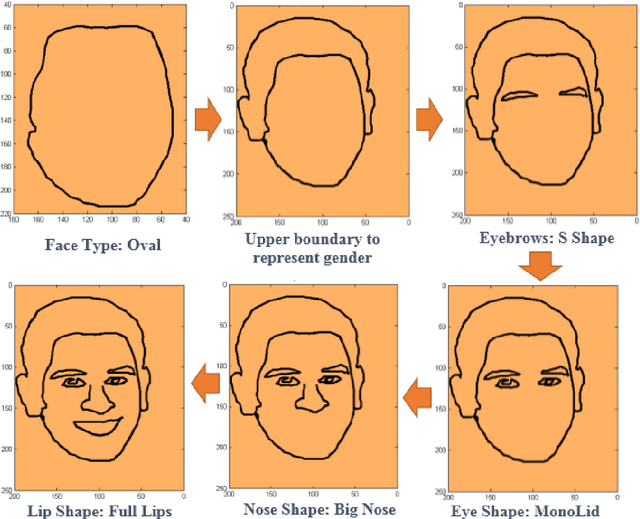

Faces play a magnificent role in human robot interaction, as they do in our daily life. The inherent ability of the human mind facilitates us to recognize a person by exploiting various challenges such as bad illumination, occlusions, pose variation etc. which are involved in face recognition. But it is a very complex task in nature to identify a human face by humanoid robots. The recent literatures on face biometric recognition are extremely rich in its application on structured environment for solving human identification problem. But the application of face biometric on mobile robotics is limited for its inability to produce accurate identification in uneven circumstances. The existing face recognition problem has been tackled with our proposed component based fragmented face recognition framework. The proposed framework uses only a subset of the full face such as eyes, nose and mouth to recognize a person. It's less searching cost, encouraging accuracy and ability to handle various challenges of face recognition offers its applicability on humanoid robots. The second problem in face recognition is the face spoofing, in which a face recognition system is not able to distinguish between a person and an imposter (photo/video of the genuine user). The problem will become more detrimental when robots are used as an authenticator. A depth analysis method has been investigated in our research work to test the liveness of imposters to discriminate them from the legitimate users. The implication of the previous earned techniques has been used with respect to criminal identification with NAO robot. An eyewitness can interact with NAO through a user interface. NAO asks several questions about the suspect, such as age, height, her/his facial shape and size etc., and then making a guess about her/his face.
Development of a Fuzzy Expert System based Liveliness Detection Scheme for Biometric Authentication
Sep 17, 2016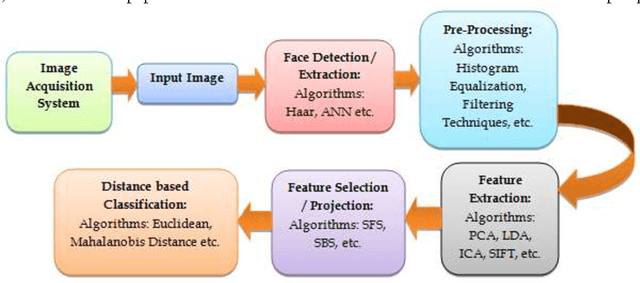


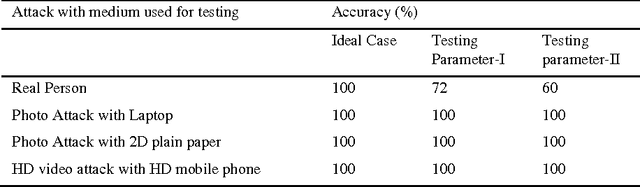
Liveliness detection acts as a safe guard against spoofing attacks. Most of the researchers used vision based techniques to detect liveliness of the user, but they are highly sensitive to illumination effects. Therefore it is very hard to design a system, which will work robustly under all circumstances. Literature shows that most of the research utilize eye blink or mouth movement to detect the liveliness, while the other group used face texture to distinguish between real and imposter. The classification results of all these approaches decreases drastically in variable light conditions. Hence in this paper we are introducing fuzzy expert system which is sufficient enough to handle most of the cases comes in real time. We have used two testing parameters, (a) under bad illumination and (b) less movement in eyes and mouth in case of real user to evaluate the performance of the system. The system is behaving well in all, while in first case its False Rejection Rate (FRR) is 0.28, and in second case its FRR is 0.4.