 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueST: Persistent Queries as Semantic Monitors for Drift Suppression in Long-Horizon Tracking
May 10, 2026Tracking points in videos is typically formulated as frame-to-frame correspondence, where each point is matched locally to the next frame. While this works over short horizons, errors accumulate under articulation, occlusion, and viewpoint change, leading to silent semantic drift that existing trackers cannot detect or correct. In this work, we revisit long-horizon tracking from a monitoring perspective and introduce QueST, a monitoring-by-design framework that treats interaction-relevant entities as persistent semantic queries rather than transient point tracks. Instead of local propagation, each query attends globally over spatio-temporal video features at every time-step, providing a stable semantic anchor across time. We further constrain query trajectories with lightweight 3D physical grounding, using geometric plausibility to suppress unbounded drift under occlusion. We evaluate QueST on long-horizon articulated sequences from PartNet-Mobility in SAPIEN and compare against RAFT-3D, CoTracker, and TAP-Net. QueST substantially reduces terminal drift achieving a 67.7% Absolute Point Error (APE) improvement over TAP-Net while better preserving identity over extended horizons. Our results show that embedding semantic monitoring directly into perception enables more reliable long-horizon tracking under distribution shift.
UltrasODM: A Dual Stream Optical Flow Mamba Network for 3D Freehand Ultrasound Reconstruction
Dec 08, 2025Clinical ultrasound acquisition is highly operator-dependent, where rapid probe motion and brightness fluctuations often lead to reconstruction errors that reduce trust and clinical utility. We present UltrasODM, a dual-stream framework that assists sonographers during acquisition through calibrated per-frame uncertainty, saliency-based diagnostics, and actionable prompts. UltrasODM integrates (i) a contrastive ranking module that groups frames by motion similarity, (ii) an optical-flow stream fused with Dual-Mamba temporal modules for robust 6-DoF pose estimation, and (iii) a Human-in-the-Loop (HITL) layer combining Bayesian uncertainty, clinician-calibrated thresholds, and saliency maps highlighting regions of low confidence. When uncertainty exceeds the threshold, the system issues unobtrusive alerts suggesting corrective actions such as re-scanning highlighted regions or slowing the sweep. Evaluated on a clinical freehand ultrasound dataset, UltrasODM reduces drift by 15.2%, distance error by 12.1%, and Hausdorff distance by 10.1% relative to UltrasOM, while producing per-frame uncertainty and saliency outputs. By emphasizing transparency and clinician feedback, UltrasODM improves reconstruction reliability and supports safer, more trustworthy clinical workflows. Our code is publicly available at https://github.com/AnandMayank/UltrasODM.
GRIM: Task-Oriented Grasping with Conditioning on Generative Examples
Jun 18, 2025



Task-Oriented Grasping (TOG) presents a significant challenge, requiring a nuanced understanding of task semantics, object affordances, and the functional constraints dictating how an object should be grasped for a specific task. To address these challenges, we introduce GRIM (Grasp Re-alignment via Iterative Matching), a novel training-free framework for task-oriented grasping. Initially, a coarse alignment strategy is developed using a combination of geometric cues and principal component analysis (PCA)-reduced DINO features for similarity scoring. Subsequently, the full grasp pose associated with the retrieved memory instance is transferred to the aligned scene object and further refined against a set of task-agnostic, geometrically stable grasps generated for the scene object, prioritizing task compatibility. In contrast to existing learning-based methods, GRIM demonstrates strong generalization capabilities, achieving robust performance with only a small number of conditioning examples.
SplatR : Experience Goal Visual Rearrangement with 3D Gaussian Splatting and Dense Feature Matching
Nov 21, 2024



Experience Goal Visual Rearrangement task stands as a foundational challenge within Embodied AI, requiring an agent to construct a robust world model that accurately captures the goal state. The agent uses this world model to restore a shuffled scene to its original configuration, making an accurate representation of the world essential for successfully completing the task. In this work, we present a novel framework that leverages on 3D Gaussian Splatting as a 3D scene representation for experience goal visual rearrangement task. Recent advances in volumetric scene representation like 3D Gaussian Splatting, offer fast rendering of high quality and photo-realistic novel views. Our approach enables the agent to have consistent views of the current and the goal setting of the rearrangement task, which enables the agent to directly compare the goal state and the shuffled state of the world in image space. To compare these views, we propose to use a dense feature matching method with visual features extracted from a foundation model, leveraging its advantages of a more universal feature representation, which facilitates robustness, and generalization. We validate our approach on the AI2-THOR rearrangement challenge benchmark and demonstrate improvements over the current state of the art methods
Towards Open-World Mobile Manipulation in Homes: Lessons from the Neurips 2023 HomeRobot Open Vocabulary Mobile Manipulation Challenge
Jul 09, 2024



In order to develop robots that can effectively serve as versatile and capable home assistants, it is crucial for them to reliably perceive and interact with a wide variety of objects across diverse environments. To this end, we proposed Open Vocabulary Mobile Manipulation as a key benchmark task for robotics: finding any object in a novel environment and placing it on any receptacle surface within that environment. We organized a NeurIPS 2023 competition featuring both simulation and real-world components to evaluate solutions to this task. Our baselines on the most challenging version of this task, using real perception in simulation, achieved only an 0.8% success rate; by the end of the competition, the best participants achieved an 10.8\% success rate, a 13x improvement. We observed that the most successful teams employed a variety of methods, yet two common threads emerged among the best solutions: enhancing error detection and recovery, and improving the integration of perception with decision-making processes. In this paper, we detail the results and methodologies used, both in simulation and real-world settings. We discuss the lessons learned and their implications for future research. Additionally, we compare performance in real and simulated environments, emphasizing the necessity for robust generalization to novel settings.
Exploring Unseen Environments with Robots using Large Language and Vision Models through a Procedurally Generated 3D Scene Representation
Mar 30, 2024



Recent advancements in Generative Artificial Intelligence, particularly in the realm of Large Language Models (LLMs) and Large Vision Language Models (LVLMs), have enabled the prospect of leveraging cognitive planners within robotic systems. This work focuses on solving the object goal navigation problem by mimicking human cognition to attend, perceive and store task specific information and generate plans with the same. We introduce a comprehensive framework capable of exploring an unfamiliar environment in search of an object by leveraging the capabilities of Large Language Models(LLMs) and Large Vision Language Models (LVLMs) in understanding the underlying semantics of our world. A challenging task in using LLMs to generate high level sub-goals is to efficiently represent the environment around the robot. We propose to use a 3D scene modular representation, with semantically rich descriptions of the object, to provide the LLM with task relevant information. But providing the LLM with a mass of contextual information (rich 3D scene semantic representation), can lead to redundant and inefficient plans. We propose to use an LLM based pruner that leverages the capabilities of in-context learning to prune out irrelevant goal specific information.
UniTeam: Open Vocabulary Mobile Manipulation Challenge
Dec 14, 2023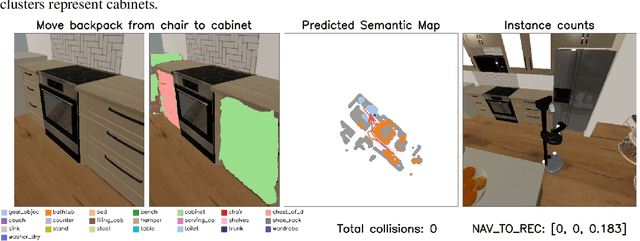
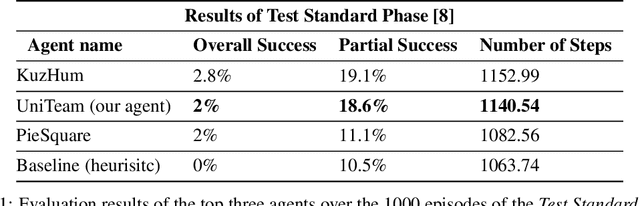


This report introduces our UniTeam agent - an improved baseline for the "HomeRobot: Open Vocabulary Mobile Manipulation" challenge. The challenge poses problems of navigation in unfamiliar environments, manipulation of novel objects, and recognition of open-vocabulary object classes. This challenge aims to facilitate cross-cutting research in embodied AI using recent advances in machine learning, computer vision, natural language, and robotics. In this work, we conducted an exhaustive evaluation of the provided baseline agent; identified deficiencies in perception, navigation, and manipulation skills; and improved the baseline agent's performance. Notably, enhancements were made in perception - minimizing misclassifications; navigation - preventing infinite loop commitments; picking - addressing failures due to changing object visibility; and placing - ensuring accurate positioning for successful object placement.
Language-Conditioned Semantic Search-Based Policy for Robotic Manipulation Tasks
Dec 10, 2023



Reinforcement learning and Imitation Learning approaches utilize policy learning strategies that are difficult to generalize well with just a few examples of a task. In this work, we propose a language-conditioned semantic search-based method to produce an online search-based policy from the available demonstration dataset of state-action trajectories. Here we directly acquire actions from the most similar manipulation trajectories found in the dataset. Our approach surpasses the performance of the baselines on the CALVIN benchmark and exhibits strong zero-shot adaptation capabilities. This holds great potential for expanding the use of our online search-based policy approach to tasks typically addressed by Imitation Learning or Reinforcement Learning-based policies.
Hyperparameters optimization for Deep Learning based emotion prediction for Human Robot Interaction
Jan 12, 2020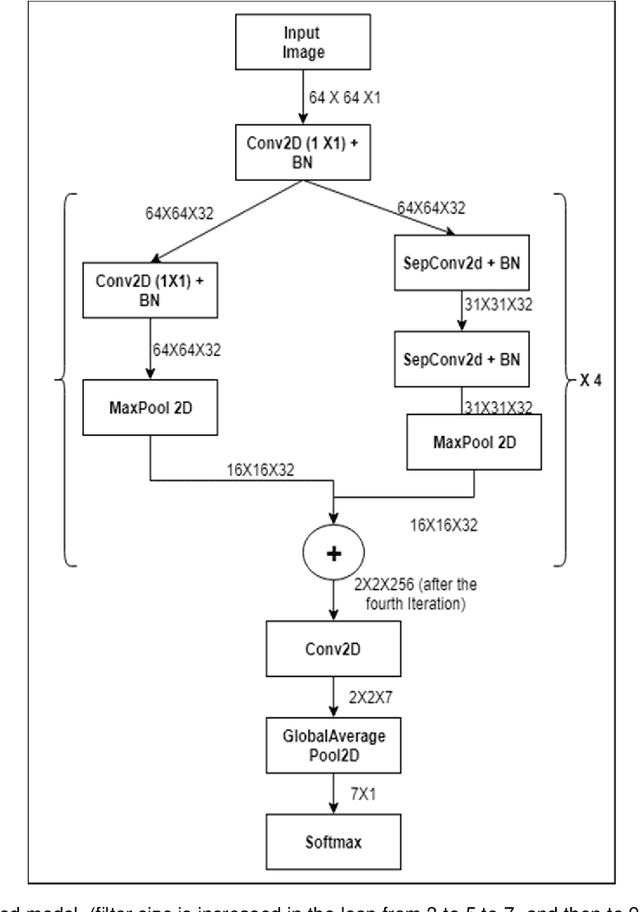
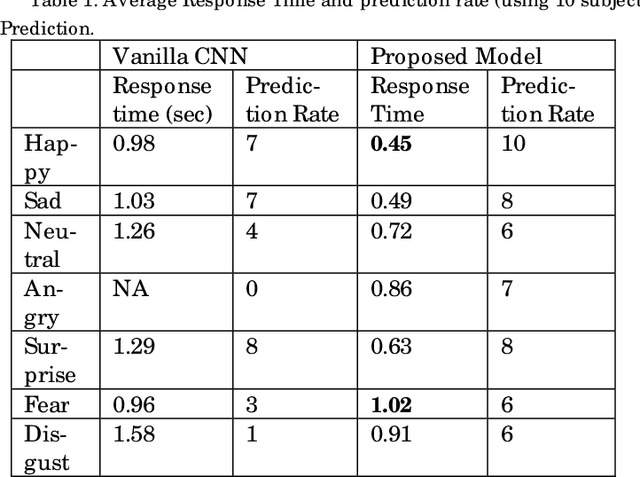

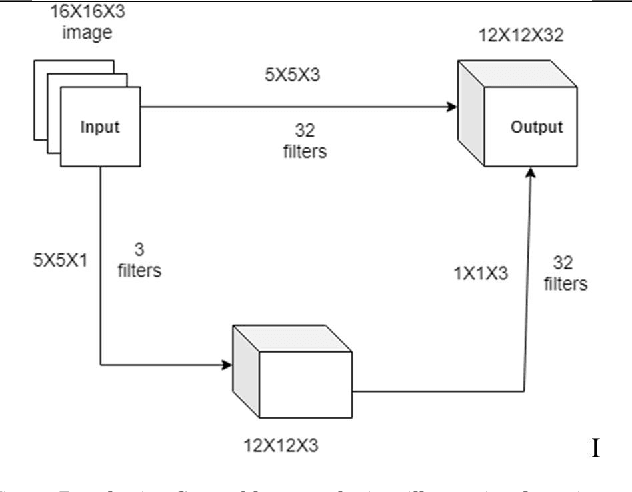
To enable humanoid robots to share our social space we need to develop technology for easy interaction with the robots using multiple modes such as speech, gestures and share our emotions with them. We have targeted this research towards addressing the core issue of emotion recognition problem which would require less computation resources and much lesser number of network hyperparameters which will be more adaptive to be computed on low resourced social robots for real time communication. More specifically, here we have proposed an Inception module based Convolutional Neural Network Architecture which has achieved improved accuracy of upto 6% improvement over the existing network architecture for emotion classification when combinedly tested over multiple datasets when tried over humanoid robots in real - time. Our proposed model is reducing the trainable Hyperparameters to an extent of 94% as compared to vanilla CNN model which clearly indicates that it can be used in real time based application such as human robot interaction. Rigorous experiments have been performed to validate our methodology which is sufficiently robust and could achieve high level of accuracy. Finally, the model is implemented in a humanoid robot, NAO in real time and robustness of the model is evaluated.