 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Open-World Mobile Manipulation in Homes: Lessons from the Neurips 2023 HomeRobot Open Vocabulary Mobile Manipulation Challenge
Jul 09, 2024



In order to develop robots that can effectively serve as versatile and capable home assistants, it is crucial for them to reliably perceive and interact with a wide variety of objects across diverse environments. To this end, we proposed Open Vocabulary Mobile Manipulation as a key benchmark task for robotics: finding any object in a novel environment and placing it on any receptacle surface within that environment. We organized a NeurIPS 2023 competition featuring both simulation and real-world components to evaluate solutions to this task. Our baselines on the most challenging version of this task, using real perception in simulation, achieved only an 0.8% success rate; by the end of the competition, the best participants achieved an 10.8\% success rate, a 13x improvement. We observed that the most successful teams employed a variety of methods, yet two common threads emerged among the best solutions: enhancing error detection and recovery, and improving the integration of perception with decision-making processes. In this paper, we detail the results and methodologies used, both in simulation and real-world settings. We discuss the lessons learned and their implications for future research. Additionally, we compare performance in real and simulated environments, emphasizing the necessity for robust generalization to novel settings.
UniTeam: Open Vocabulary Mobile Manipulation Challenge
Dec 14, 2023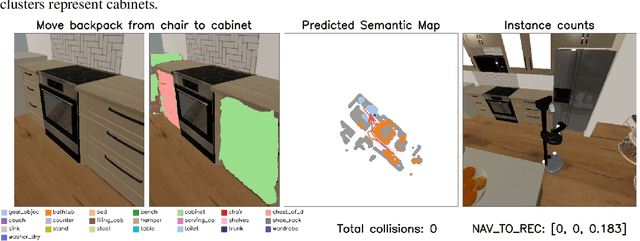
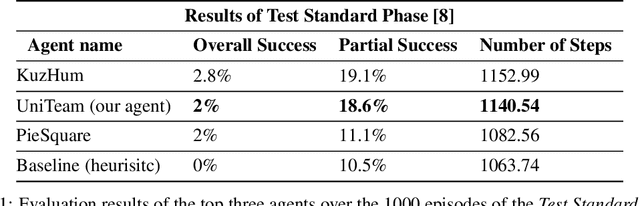


This report introduces our UniTeam agent - an improved baseline for the "HomeRobot: Open Vocabulary Mobile Manipulation" challenge. The challenge poses problems of navigation in unfamiliar environments, manipulation of novel objects, and recognition of open-vocabulary object classes. This challenge aims to facilitate cross-cutting research in embodied AI using recent advances in machine learning, computer vision, natural language, and robotics. In this work, we conducted an exhaustive evaluation of the provided baseline agent; identified deficiencies in perception, navigation, and manipulation skills; and improved the baseline agent's performance. Notably, enhancements were made in perception - minimizing misclassifications; navigation - preventing infinite loop commitments; picking - addressing failures due to changing object visibility; and placing - ensuring accurate positioning for successful object placement.
Solving Learn-to-Race Autonomous Racing Challenge by Planning in Latent Space
Jul 05, 2022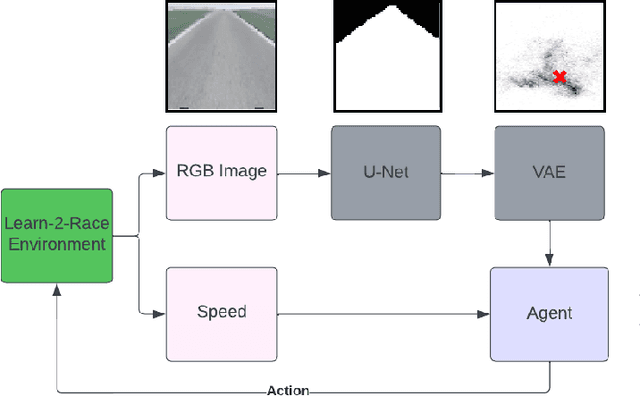
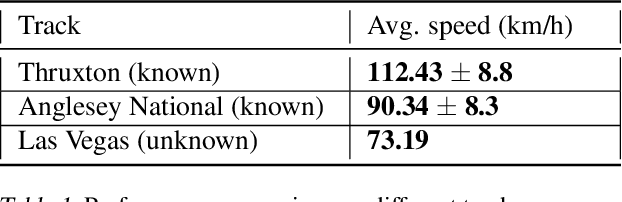

Learn-to-Race Autonomous Racing Virtual Challenge hosted on www<dot>aicrowd<dot>com platform consisted of two tracks: Single and Multi Camera. Our UniTeam team was among the final winners in the Single Camera track. The agent is required to pass the previously unknown F1-style track in the minimum time with the least amount of off-road driving violations. In our approach, we used the U-Net architecture for road segmentation, variational autocoder for encoding a road binary mask, and a nearest-neighbor search strategy that selects the best action for a given state. Our agent achieved an average speed of 105 km/h on stage 1 (known track) and 73 km/h on stage 2 (unknown track) without any off-road driving violations. Here we present our solution and results.
METEOR: A Massive Dense & Heterogeneous Behavior Dataset for Autonomous Driving
Sep 30, 2021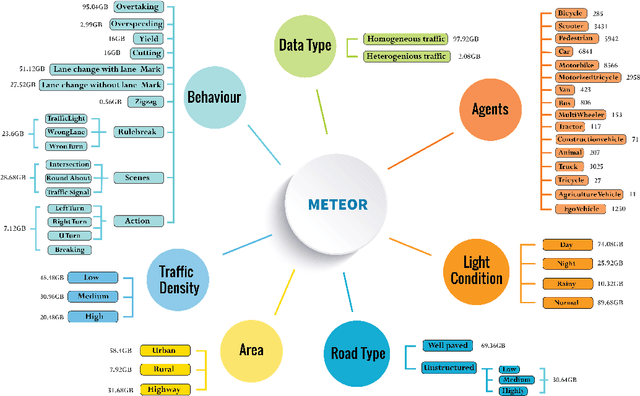

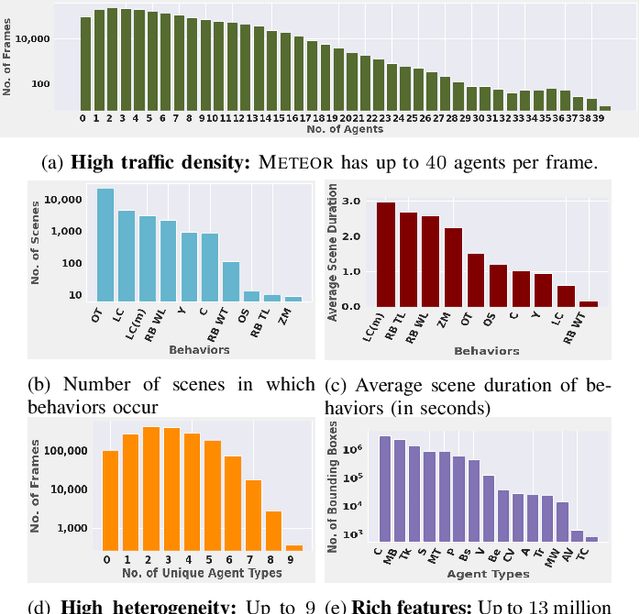

We present a new and complex traffic dataset, METEOR, which captures traffic patterns in unstructured scenarios in India. METEOR consists of more than 1000 one-minute video clips, over 2 million annotated frames with ego-vehicle trajectories, and more than 13 million bounding boxes for surrounding vehicles or traffic agents. METEOR is a unique dataset in terms of capturing the heterogeneity of microscopic and macroscopic traffic characteristics. Furthermore, we provide annotations for rare and interesting driving behaviors such as cut-ins, yielding, overtaking, overspeeding, zigzagging, sudden lane changing, running traffic signals, driving in the wrong lanes, taking wrong turns, lack of right-of-way rules at intersections, etc. We also present diverse traffic scenarios corresponding to rainy weather, nighttime driving, driving in rural areas with unmarked roads, and high-density traffic scenarios. We use our novel dataset to evaluate the performance of object detection and behavior prediction algorithms. We show that state-of-the-art object detectors fail in these challenging conditions and also propose a new benchmark test: action-behavior prediction with a baseline mAP score of 70.74.
Offline Handwriting Recognition using Genetic Algorithm
Apr 19, 2010

Handwriting Recognition enables a person to scribble something on a piece of paper and then convert it into text. If we look into the practical reality there are enumerable styles in which a character may be written. These styles can be self combined to generate more styles. Even if a small child knows the basic styles a character can be written, he would be able to recognize characters written in styles intermediate between them or formed by their mixture. This motivates the use of Genetic Algorithms for the problem. In order to prove this, we made a pool of images of characters. We converted them to graphs. The graph of every character was intermixed to generate styles intermediate between the styles of parent character. Character recognition involved the matching of the graph generated from the unknown character image with the graphs generated by mixing. Using this method we received an accuracy of 98.44%.
* International Journal of Computer Science Issues at http://ijcsi.org/articles/Offline-Handwriting-Recognition-using-Genetic-Algorithm.php