 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning with RL and episodic-memory behavioral priors
Jul 07, 2022
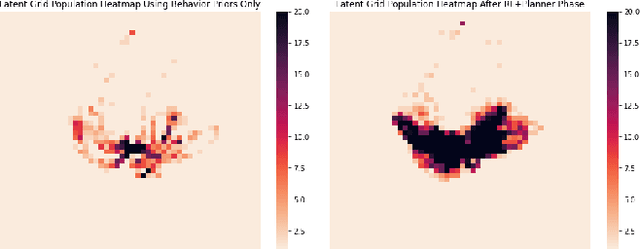

The practical application of learning agents requires sample efficient and interpretable algorithms. Learning from behavioral priors is a promising way to bootstrap agents with a better-than-random exploration policy or a safe-guard against the pitfalls of early learning. Existing solutions for imitation learning require a large number of expert demonstrations and rely on hard-to-interpret learning methods like Deep Q-learning. In this work we present a planning-based approach that can use these behavioral priors for effective exploration and learning in a reinforcement learning environment, and we demonstrate that curated exploration policies in the form of behavioral priors can help an agent learn faster.
Solving Learn-to-Race Autonomous Racing Challenge by Planning in Latent Space
Jul 05, 2022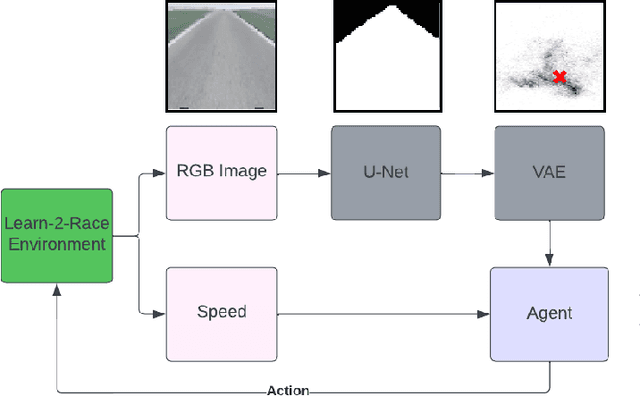
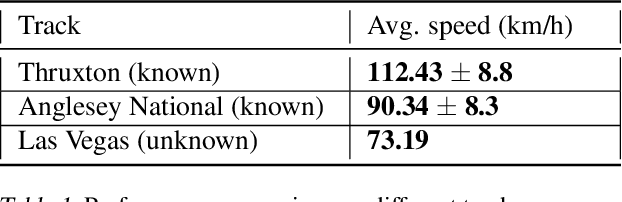

Learn-to-Race Autonomous Racing Virtual Challenge hosted on www<dot>aicrowd<dot>com platform consisted of two tracks: Single and Multi Camera. Our UniTeam team was among the final winners in the Single Camera track. The agent is required to pass the previously unknown F1-style track in the minimum time with the least amount of off-road driving violations. In our approach, we used the U-Net architecture for road segmentation, variational autocoder for encoding a road binary mask, and a nearest-neighbor search strategy that selects the best action for a given state. Our agent achieved an average speed of 105 km/h on stage 1 (known track) and 73 km/h on stage 2 (unknown track) without any off-road driving violations. Here we present our solution and results.