Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning with RL and episodic-memory behavioral priors
Paper and Code
Jul 07, 2022
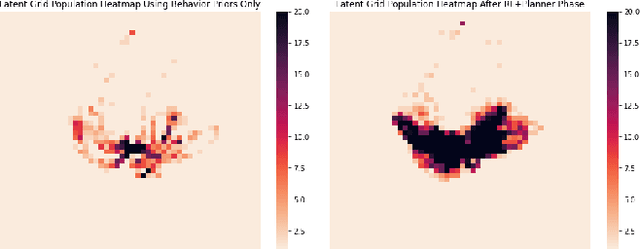
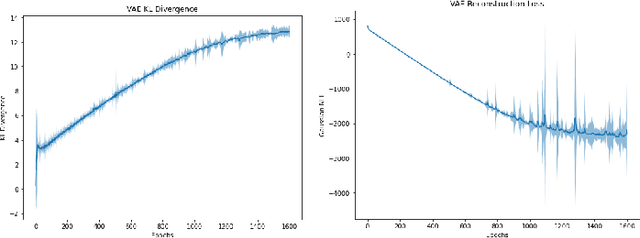

The practical application of learning agents requires sample efficient and interpretable algorithms. Learning from behavioral priors is a promising way to bootstrap agents with a better-than-random exploration policy or a safe-guard against the pitfalls of early learning. Existing solutions for imitation learning require a large number of expert demonstrations and rely on hard-to-interpret learning methods like Deep Q-learning. In this work we present a planning-based approach that can use these behavioral priors for effective exploration and learning in a reinforcement learning environment, and we demonstrate that curated exploration policies in the form of behavioral priors can help an agent learn faster.
* Published in ICRA 2022 BPRL Workshop
View paper on