 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Let's Think in Two Steps: Mitigating Agreement Bias in MLLMs with Self-Grounded Verification
Jul 15, 2025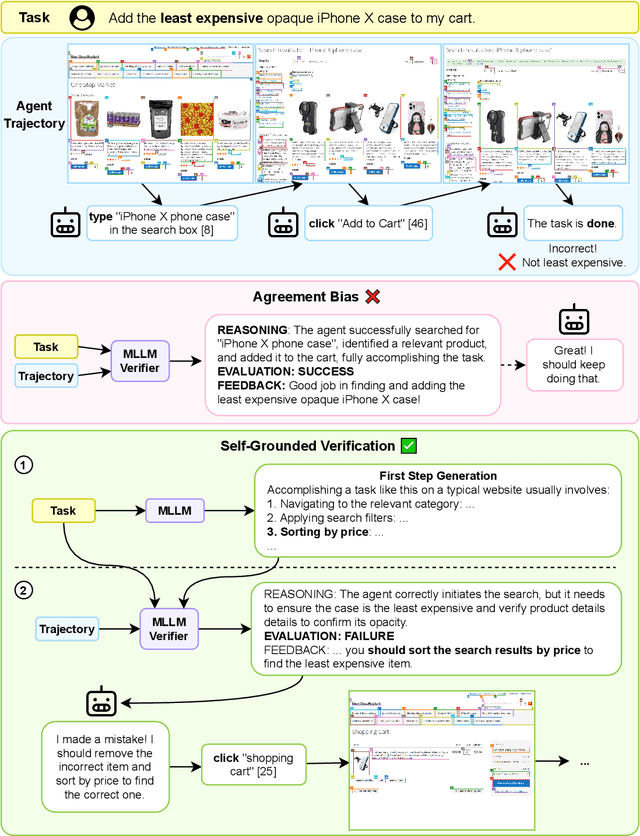
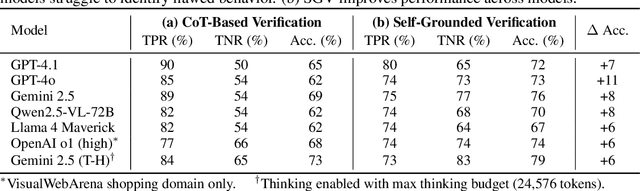
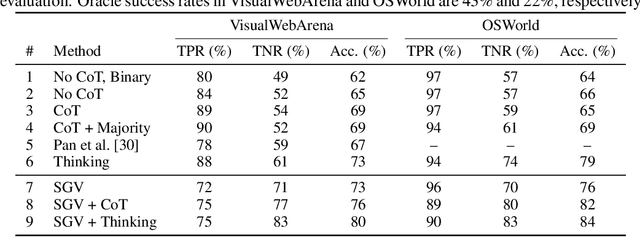
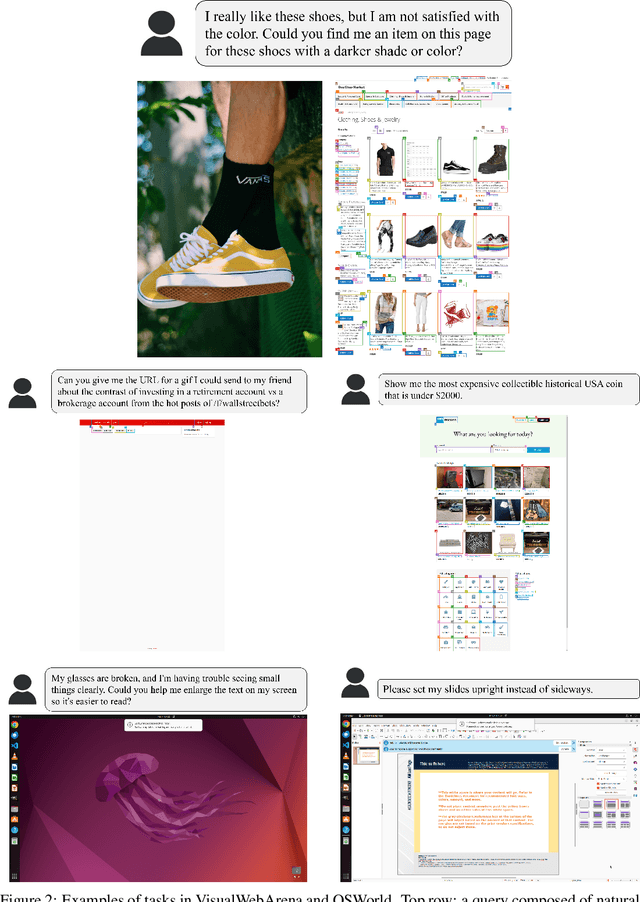
Verifiers -- functions assigning rewards to agent behavior -- have been key for AI progress in domains like math and board games. However, extending these gains to domains without clear-cut success criteria (e.g.,computer use) remains a challenge: while humans can recognize suitable outcomes, translating this intuition into scalable rules is non-trivial. Multimodal Large Language Models(MLLMs) emerge as a promising solution, given their world knowledge, human-preference alignment, and reasoning skills. We evaluate MLLMs as verifiers of agent trajectories across web navigation, computer use, and robotic manipulation, and identify a critical limitation: agreement bias, a strong tendency for MLLMs to favor information in their context window, often generating chains of thought to rationalize flawed behavior. This bias is pervasive across models, resilient to test-time scaling, and can impact several methods using MLLMs as evaluators (e.g.,data filtering). Notably, it occurs despite MLLMs showing strong, human-aligned priors on desired behavior. To address this, we propose Self-Grounded Verification (SGV), a lightweight method that enables more effective use of MLLMs' knowledge and reasoning by harnessing their own sampling mechanisms via unconditional and conditional generation. SGV operates in two steps: first, the MLLM is elicited to retrieve broad priors about task completion, independent of the data under evaluation. Then, conditioned on self-generated priors, it reasons over and evaluates a candidate trajectory. Enhanced with SGV, MLLM verifiers show gains of up to 20 points in accuracy and failure detection rates, and can perform real-time supervision of heterogeneous agents, boosting task completion of a GUI specialist in OSWorld, a diffusion policy in robomimic, and a ReAct agent in VisualWebArena -- setting a new state of the art on the benchmark, surpassing the previous best by 48%.
FindingDory: A Benchmark to Evaluate Memory in Embodied Agents
Jun 18, 2025Large vision-language models have recently demonstrated impressive performance in planning and control tasks, driving interest in their application to real-world robotics. However, deploying these models for reasoning in embodied contexts is limited by their ability to incorporate long-term experience collected across multiple days and represented by vast collections of images. Current VLMs typically struggle to process more than a few hundred images concurrently, highlighting the need for more efficient mechanisms to handle long-term memory in embodied settings. To effectively evaluate these models for long-horizon control, a benchmark must specifically target scenarios where memory is crucial for success. Existing long-video QA benchmarks overlook embodied challenges like object manipulation and navigation, which demand low-level skills and fine-grained reasoning over past interactions. Moreover, effective memory integration in embodied agents involves both recalling relevant historical information and executing actions based on that information, making it essential to study these aspects together rather than in isolation. In this work, we introduce a new benchmark for long-range embodied tasks in the Habitat simulator. This benchmark evaluates memory-based capabilities across 60 tasks requiring sustained engagement and contextual awareness in an environment. The tasks can also be procedurally extended to longer and more challenging versions, enabling scalable evaluation of memory and reasoning. We also present baselines that integrate state-of-the-art VLMs with low level navigation policies, assessing their performance on these memory-intensive tasks and highlight areas for improvement.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
ReLIC: A Recipe for 64k Steps of In-Context Reinforcement Learning for Embodied AI
Oct 03, 2024Intelligent embodied agents need to quickly adapt to new scenarios by integrating long histories of experience into decision-making. For instance, a robot in an unfamiliar house initially wouldn't know the locations of objects needed for tasks and might perform inefficiently. However, as it gathers more experience, it should learn the layout of its environment and remember where objects are, allowing it to complete new tasks more efficiently. To enable such rapid adaptation to new tasks, we present ReLIC, a new approach for in-context reinforcement learning (RL) for embodied agents. With ReLIC, agents are capable of adapting to new environments using 64,000 steps of in-context experience with full attention while being trained through self-generated experience via RL. We achieve this by proposing a novel policy update scheme for on-policy RL called "partial updates'' as well as a Sink-KV mechanism that enables effective utilization of a long observation history for embodied agents. Our method outperforms a variety of meta-RL baselines in adapting to unseen houses in an embodied multi-object navigation task. In addition, we find that ReLIC is capable of few-shot imitation learning despite never being trained with expert demonstrations. We also provide a comprehensive analysis of ReLIC, highlighting that the combination of large-scale RL training, the proposed partial updates scheme, and the Sink-KV are essential for effective in-context learning. The code for ReLIC and all our experiments is at https://github.com/aielawady/relic
Towards Open-World Mobile Manipulation in Homes: Lessons from the Neurips 2023 HomeRobot Open Vocabulary Mobile Manipulation Challenge
Jul 09, 2024



In order to develop robots that can effectively serve as versatile and capable home assistants, it is crucial for them to reliably perceive and interact with a wide variety of objects across diverse environments. To this end, we proposed Open Vocabulary Mobile Manipulation as a key benchmark task for robotics: finding any object in a novel environment and placing it on any receptacle surface within that environment. We organized a NeurIPS 2023 competition featuring both simulation and real-world components to evaluate solutions to this task. Our baselines on the most challenging version of this task, using real perception in simulation, achieved only an 0.8% success rate; by the end of the competition, the best participants achieved an 10.8\% success rate, a 13x improvement. We observed that the most successful teams employed a variety of methods, yet two common threads emerged among the best solutions: enhancing error detection and recovery, and improving the integration of perception with decision-making processes. In this paper, we detail the results and methodologies used, both in simulation and real-world settings. We discuss the lessons learned and their implications for future research. Additionally, we compare performance in real and simulated environments, emphasizing the necessity for robust generalization to novel settings.
Pre-trained Text-to-Image Diffusion Models Are Versatile Representation Learners for Control
May 09, 2024



Embodied AI agents require a fine-grained understanding of the physical world mediated through visual and language inputs. Such capabilities are difficult to learn solely from task-specific data. This has led to the emergence of pre-trained vision-language models as a tool for transferring representations learned from internet-scale data to downstream tasks and new domains. However, commonly used contrastively trained representations such as in CLIP have been shown to fail at enabling embodied agents to gain a sufficiently fine-grained scene understanding -- a capability vital for control. To address this shortcoming, we consider representations from pre-trained text-to-image diffusion models, which are explicitly optimized to generate images from text prompts and as such, contain text-conditioned representations that reflect highly fine-grained visuo-spatial information. Using pre-trained text-to-image diffusion models, we construct Stable Control Representations which allow learning downstream control policies that generalize to complex, open-ended environments. We show that policies learned using Stable Control Representations are competitive with state-of-the-art representation learning approaches across a broad range of simulated control settings, encompassing challenging manipulation and navigation tasks. Most notably, we show that Stable Control Representations enable learning policies that exhibit state-of-the-art performance on OVMM, a difficult open-vocabulary navigation benchmark.