 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ferret-UI Lite: Lessons from Building Small On-Device GUI Agents
Sep 30, 2025
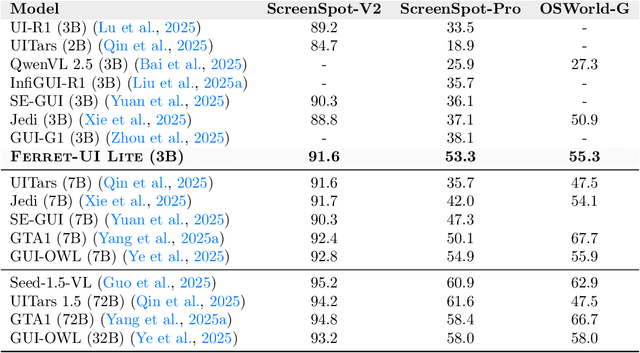
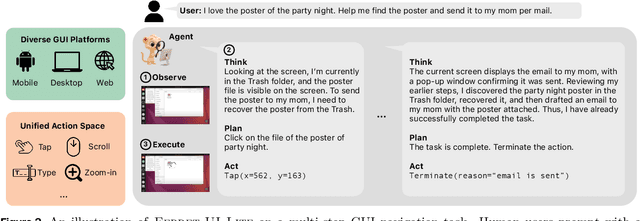
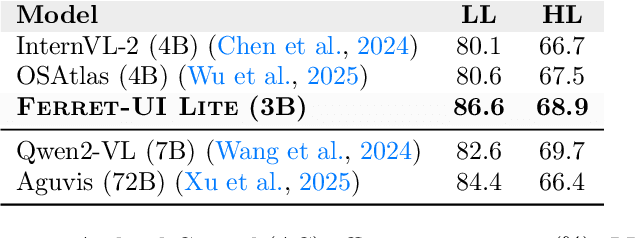
Developing autonomous agents that effectively interact with Graphic User Interfaces (GUIs) remains a challenging open problem, especially for small on-device models. In this paper, we present Ferret-UI Lite, a compact, end-to-end GUI agent that operates across diverse platforms, including mobile, web, and desktop. Utilizing techniques optimized for developing small models, we build our 3B Ferret-UI Lite agent through curating a diverse GUI data mixture from real and synthetic sources, strengthening inference-time performance through chain-of-thought reasoning and visual tool-use, and reinforcement learning with designed rewards. Ferret-UI Lite achieves competitive performance with other small-scale GUI agents. In GUI grounding, Ferret-UI Lite attains scores of $91.6\%$, $53.3\%$, and $61.2\%$ on the ScreenSpot-V2, ScreenSpot-Pro, and OSWorld-G benchmarks, respectively. For GUI navigation, Ferret-UI Lite achieves success rates of $28.0\%$ on AndroidWorld and $19.8\%$ on OSWorld. We share our methods and lessons learned from developing compact, on-device GUI agents.
Grounding Multimodal LLMs to Embodied Agents that Ask for Help with Reinforcement Learning
Apr 02, 2025
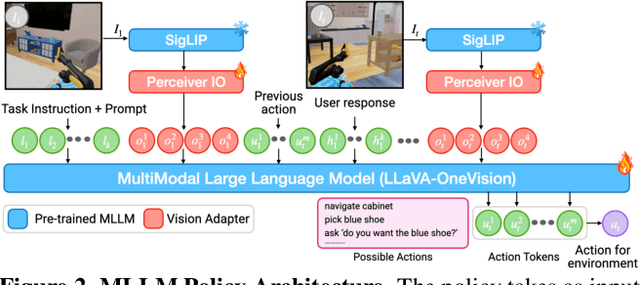
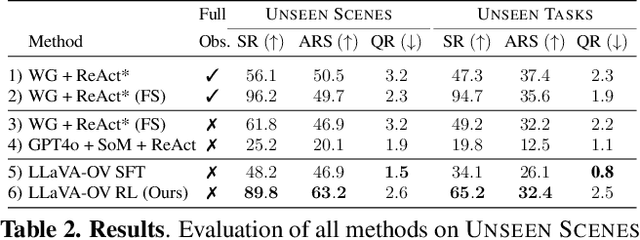
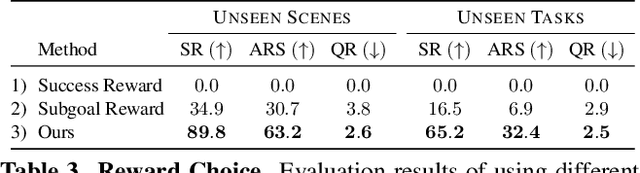
Embodied agents operating in real-world environments must interpret ambiguous and under-specified human instructions. A capable household robot should recognize ambiguity and ask relevant clarification questions to infer the user intent accurately, leading to more effective task execution. To study this problem, we introduce the Ask-to-Act task, where an embodied agent must fetch a specific object instance given an ambiguous instruction in a home environment. The agent must strategically ask minimal, yet relevant, clarification questions to resolve ambiguity while navigating under partial observability. To solve this problem, we propose a novel approach that fine-tunes multimodal large language models (MLLMs) as vision-language-action (VLA) policies using online reinforcement learning (RL) with LLM-generated rewards. Our method eliminates the need for large-scale human demonstrations or manually engineered rewards for training such agents. We benchmark against strong zero-shot baselines, including GPT-4o, and supervised fine-tuned MLLMs, on our task. Our results demonstrate that our RL-finetuned MLLM outperforms all baselines by a significant margin ($19.1$-$40.3\%$), generalizing well to novel scenes and tasks. To the best of our knowledge, this is the first demonstration of adapting MLLMs as VLA agents that can act and ask for help using LLM-generated rewards with online RL.
PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks
Oct 31, 2024
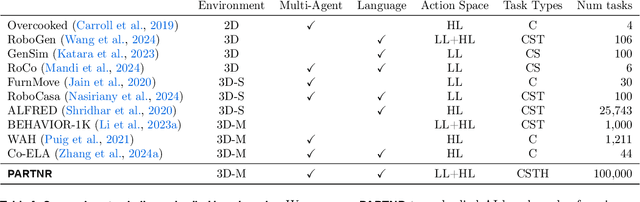

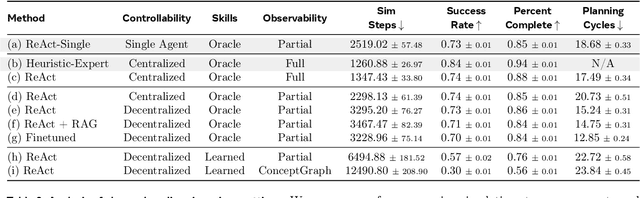
We present a benchmark for Planning And Reasoning Tasks in humaN-Robot collaboration (PARTNR) designed to study human-robot coordination in household activities. PARTNR tasks exhibit characteristics of everyday tasks, such as spatial, temporal, and heterogeneous agent capability constraints. We employ a semi-automated task generation pipeline using Large Language Models (LLMs), incorporating simulation in the loop for grounding and verification. PARTNR stands as the largest benchmark of its kind, comprising 100,000 natural language tasks, spanning 60 houses and 5,819 unique objects. We analyze state-of-the-art LLMs on PARTNR tasks, across the axes of planning, perception and skill execution. The analysis reveals significant limitations in SoTA models, such as poor coordination and failures in task tracking and recovery from errors. When LLMs are paired with real humans, they require 1.5x as many steps as two humans collaborating and 1.1x more steps than a single human, underscoring the potential for improvement in these models. We further show that fine-tuning smaller LLMs with planning data can achieve performance on par with models 9 times larger, while being 8.6x faster at inference. Overall, PARTNR highlights significant challenges facing collaborative embodied agents and aims to drive research in this direction.
ReLIC: A Recipe for 64k Steps of In-Context Reinforcement Learning for Embodied AI
Oct 03, 2024Intelligent embodied agents need to quickly adapt to new scenarios by integrating long histories of experience into decision-making. For instance, a robot in an unfamiliar house initially wouldn't know the locations of objects needed for tasks and might perform inefficiently. However, as it gathers more experience, it should learn the layout of its environment and remember where objects are, allowing it to complete new tasks more efficiently. To enable such rapid adaptation to new tasks, we present ReLIC, a new approach for in-context reinforcement learning (RL) for embodied agents. With ReLIC, agents are capable of adapting to new environments using 64,000 steps of in-context experience with full attention while being trained through self-generated experience via RL. We achieve this by proposing a novel policy update scheme for on-policy RL called "partial updates'' as well as a Sink-KV mechanism that enables effective utilization of a long observation history for embodied agents. Our method outperforms a variety of meta-RL baselines in adapting to unseen houses in an embodied multi-object navigation task. In addition, we find that ReLIC is capable of few-shot imitation learning despite never being trained with expert demonstrations. We also provide a comprehensive analysis of ReLIC, highlighting that the combination of large-scale RL training, the proposed partial updates scheme, and the Sink-KV are essential for effective in-context learning. The code for ReLIC and all our experiments is at https://github.com/aielawady/relic
HM3D-OVON: A Dataset and Benchmark for Open-Vocabulary Object Goal Navigation
Sep 22, 2024



We present the Habitat-Matterport 3D Open Vocabulary Object Goal Navigation dataset (HM3D-OVON), a large-scale benchmark that broadens the scope and semantic range of prior Object Goal Navigation (ObjectNav) benchmarks. Leveraging the HM3DSem dataset, HM3D-OVON incorporates over 15k annotated instances of household objects across 379 distinct categories, derived from photo-realistic 3D scans of real-world environments. In contrast to earlier ObjectNav datasets, which limit goal objects to a predefined set of 6-20 categories, HM3D-OVON facilitates the training and evaluation of models with an open-set of goals defined through free-form language at test-time. Through this open-vocabulary formulation, HM3D-OVON encourages progress towards learning visuo-semantic navigation behaviors that are capable of searching for any object specified by text in an open-vocabulary manner. Additionally, we systematically evaluate and compare several different types of approaches on HM3D-OVON. We find that HM3D-OVON can be used to train an open-vocabulary ObjectNav agent that achieves both higher performance and is more robust to localization and actuation noise than the state-of-the-art ObjectNav approach. We hope that our benchmark and baseline results will drive interest in developing embodied agents that can navigate real-world spaces to find household objects specified through free-form language, taking a step towards more flexible and human-like semantic visual navigation. Code and videos available at: naoki.io/ovon.
Towards Open-World Mobile Manipulation in Homes: Lessons from the Neurips 2023 HomeRobot Open Vocabulary Mobile Manipulation Challenge
Jul 09, 2024



In order to develop robots that can effectively serve as versatile and capable home assistants, it is crucial for them to reliably perceive and interact with a wide variety of objects across diverse environments. To this end, we proposed Open Vocabulary Mobile Manipulation as a key benchmark task for robotics: finding any object in a novel environment and placing it on any receptacle surface within that environment. We organized a NeurIPS 2023 competition featuring both simulation and real-world components to evaluate solutions to this task. Our baselines on the most challenging version of this task, using real perception in simulation, achieved only an 0.8% success rate; by the end of the competition, the best participants achieved an 10.8\% success rate, a 13x improvement. We observed that the most successful teams employed a variety of methods, yet two common threads emerged among the best solutions: enhancing error detection and recovery, and improving the integration of perception with decision-making processes. In this paper, we detail the results and methodologies used, both in simulation and real-world settings. We discuss the lessons learned and their implications for future research. Additionally, we compare performance in real and simulated environments, emphasizing the necessity for robust generalization to novel settings.
GOAT-Bench: A Benchmark for Multi-Modal Lifelong Navigation
Apr 09, 2024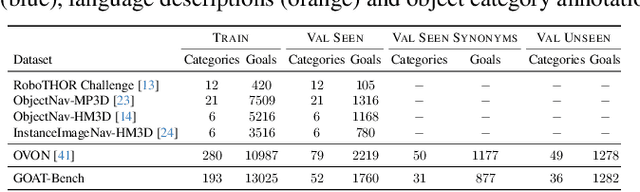

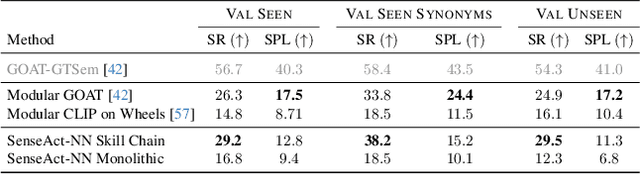
The Embodied AI community has made significant strides in visual navigation tasks, exploring targets from 3D coordinates, objects, language descriptions, and images. However, these navigation models often handle only a single input modality as the target. With the progress achieved so far, it is time to move towards universal navigation models capable of handling various goal types, enabling more effective user interaction with robots. To facilitate this goal, we propose GOAT-Bench, a benchmark for the universal navigation task referred to as GO to AnyThing (GOAT). In this task, the agent is directed to navigate to a sequence of targets specified by the category name, language description, or image in an open-vocabulary fashion. We benchmark monolithic RL and modular methods on the GOAT task, analyzing their performance across modalities, the role of explicit and implicit scene memories, their robustness to noise in goal specifications, and the impact of memory in lifelong scenarios.
Seeing the Unseen: Visual Common Sense for Semantic Placement
Jan 15, 2024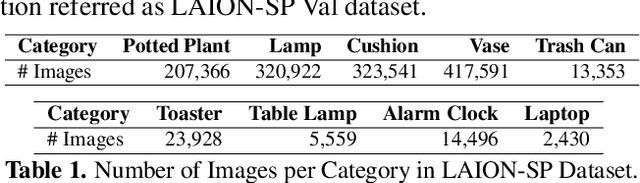
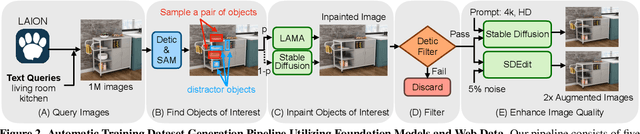
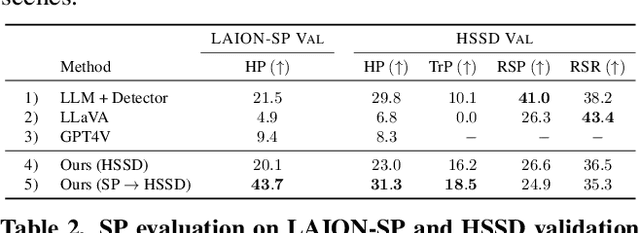

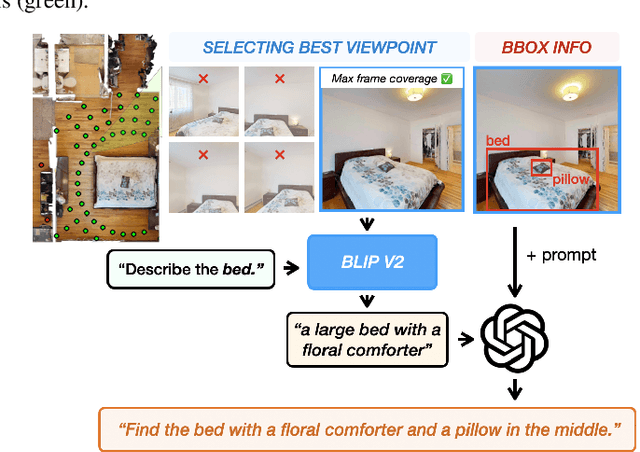
Computer vision tasks typically involve describing what is present in an image (e.g. classification, detection, segmentation, and captioning). We study a visual common sense task that requires understanding what is not present. Specifically, given an image (e.g. of a living room) and name of an object ("cushion"), a vision system is asked to predict semantically-meaningful regions (masks or bounding boxes) in the image where that object could be placed or is likely be placed by humans (e.g. on the sofa). We call this task: Semantic Placement (SP) and believe that such common-sense visual understanding is critical for assitive robots (tidying a house), and AR devices (automatically rendering an object in the user's space). Studying the invisible is hard. Datasets for image description are typically constructed by curating relevant images and asking humans to annotate the contents of the image; neither of those two steps are straightforward for objects not present in the image. We overcome this challenge by operating in the opposite direction: we start with an image of an object in context from web, and then remove that object from the image via inpainting. This automated pipeline converts unstructured web data into a dataset comprising pairs of images with/without the object. Using this, we collect a novel dataset, with ${\sim}1.3$M images across $9$ object categories, and train a SP prediction model called CLIP-UNet. CLIP-UNet outperforms existing VLMs and baselines that combine semantic priors with object detectors on real-world and simulated images. In our user studies, we find that the SP masks predicted by CLIP-UNet are favored $43.7\%$ and $31.3\%$ times when comparing against the $4$ SP baselines on real and simulated images. In addition, we demonstrate leveraging SP mask predictions from CLIP-UNet enables downstream applications like building tidying robots in indoor environments.