 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks
Oct 31, 2024
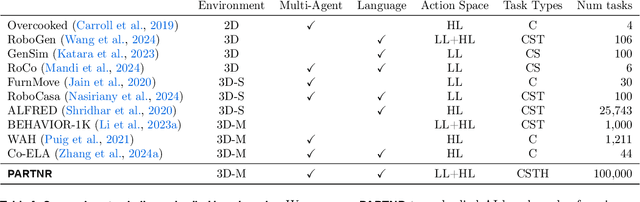

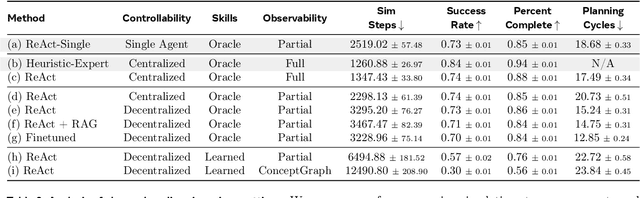
We present a benchmark for Planning And Reasoning Tasks in humaN-Robot collaboration (PARTNR) designed to study human-robot coordination in household activities. PARTNR tasks exhibit characteristics of everyday tasks, such as spatial, temporal, and heterogeneous agent capability constraints. We employ a semi-automated task generation pipeline using Large Language Models (LLMs), incorporating simulation in the loop for grounding and verification. PARTNR stands as the largest benchmark of its kind, comprising 100,000 natural language tasks, spanning 60 houses and 5,819 unique objects. We analyze state-of-the-art LLMs on PARTNR tasks, across the axes of planning, perception and skill execution. The analysis reveals significant limitations in SoTA models, such as poor coordination and failures in task tracking and recovery from errors. When LLMs are paired with real humans, they require 1.5x as many steps as two humans collaborating and 1.1x more steps than a single human, underscoring the potential for improvement in these models. We further show that fine-tuning smaller LLMs with planning data can achieve performance on par with models 9 times larger, while being 8.6x faster at inference. Overall, PARTNR highlights significant challenges facing collaborative embodied agents and aims to drive research in this direction.
Situated Instruction Following
Jul 15, 2024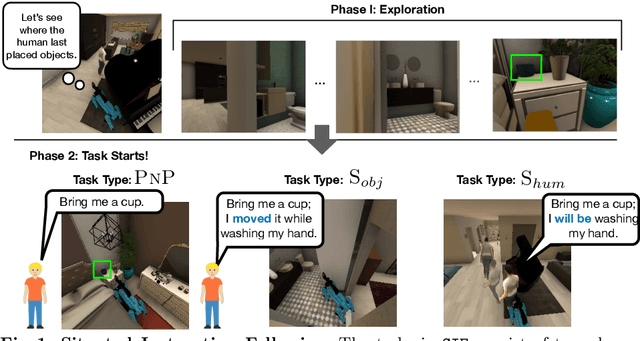
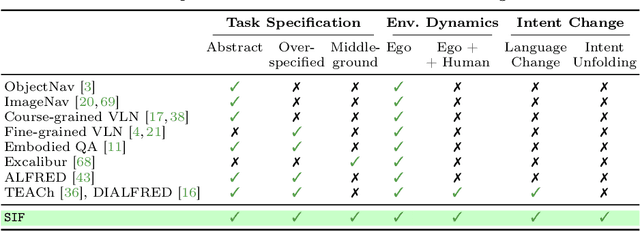
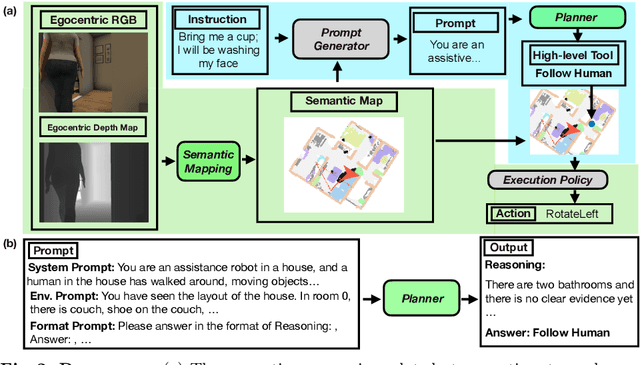
Language is never spoken in a vacuum. It is expressed, comprehended, and contextualized within the holistic backdrop of the speaker's history, actions, and environment. Since humans are used to communicating efficiently with situated language, the practicality of robotic assistants hinge on their ability to understand and act upon implicit and situated instructions. In traditional instruction following paradigms, the agent acts alone in an empty house, leading to language use that is both simplified and artificially "complete." In contrast, we propose situated instruction following, which embraces the inherent underspecification and ambiguity of real-world communication with the physical presence of a human speaker. The meaning of situated instructions naturally unfold through the past actions and the expected future behaviors of the human involved. Specifically, within our settings we have instructions that (1) are ambiguously specified, (2) have temporally evolving intent, (3) can be interpreted more precisely with the agent's dynamic actions. Our experiments indicate that state-of-the-art Embodied Instruction Following (EIF) models lack holistic understanding of situated human intention.
Spatial-Language Attention Policies for Efficient Robot Learning
Apr 21, 2023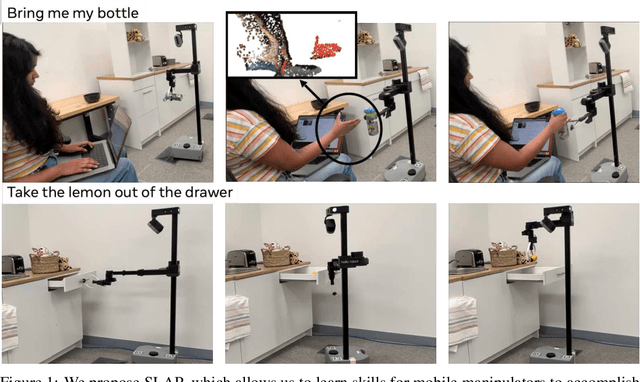
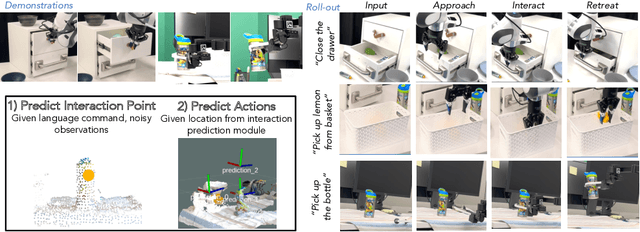
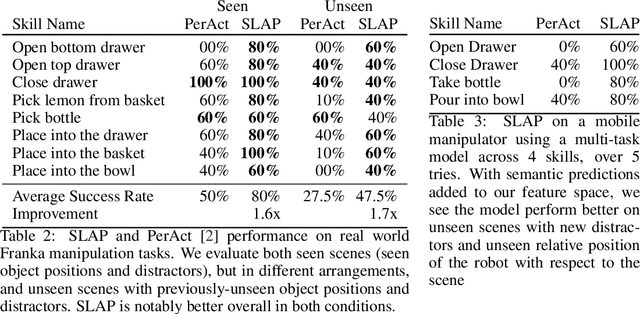
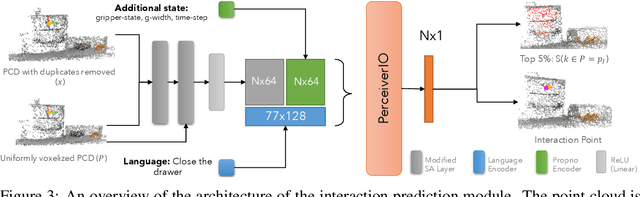
We investigate how to build and train spatial representations for robot decision making with Transformers. In particular, for robots to operate in a range of environments, we must be able to quickly train or fine-tune robot sensorimotor policies that are robust to clutter, data efficient, and generalize well to different circumstances. As a solution, we propose Spatial Language Attention Policies (SLAP). SLAP uses three-dimensional tokens as the input representation to train a single multi-task, language-conditioned action prediction policy. Our method shows 80% success rate in the real world across eight tasks with a single model, and a 47.5% success rate when unseen clutter and unseen object configurations are introduced, even with only a handful of examples per task. This represents an improvement of 30% over prior work (20% given unseen distractors and configurations).
Lessons Learned Developing an Assembly System for WRS 2020 Assembly Challenge
Mar 28, 2021


The World Robot Summit (WRS) 2020 Assembly Challenge is designed to allow teams to demonstrate how one can build flexible, robust systems for assembly of machined objects. We present our approach to assembly based on integration of machine vision, robust planning and execution using behavior trees and a hierarchy of recovery strategies to ensure robust operation. Our system was selected for the WRS 2020 Assembly Challenge finals based on robust performance in the qualifying rounds. We present the systems approach adopted for the challenge.
Meta-Modeling of Assembly Contingencies and Planning for Repair
Mar 12, 2021


The World Robotics Challenge (2018 & 2020) was designed to challenge teams to design systems that are easy to adapt to new tasks and to ensure robust operation in a semi-structured environment. We present a layered strategy to transform missions into tasks and actions and provide a set of strategies to address simple and complex failures. We propose a model for characterizing failures using this model and discuss repairs. Simple failures are by far the most common in our WRC system and we also present how we repaired them.
Pose Estimation of Specular and Symmetrical Objects
Oct 31, 2020
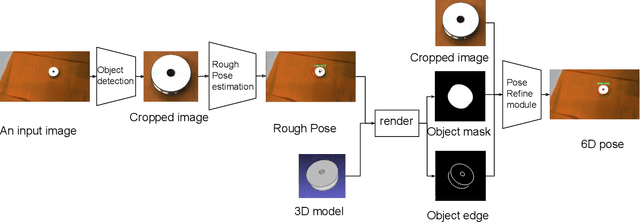
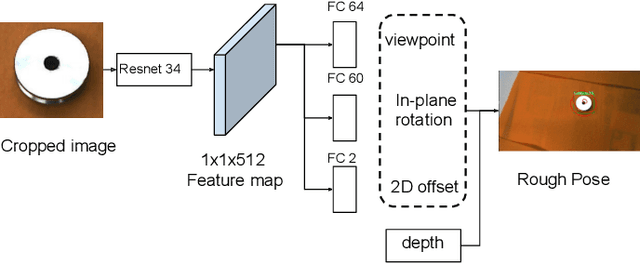
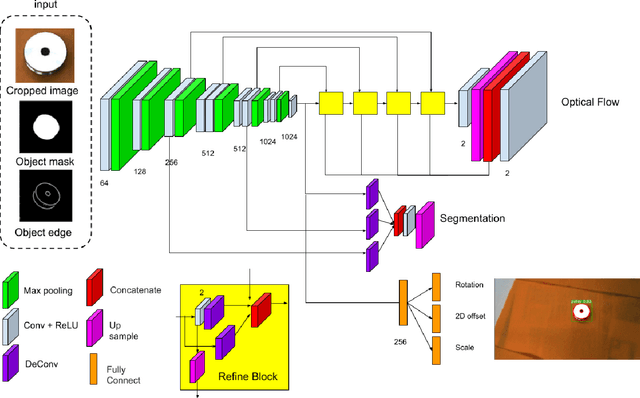
In the robotic industry, specular and textureless metallic components are ubiquitous. The 6D pose estimation of such objects with only a monocular RGB camera is difficult because of the absence of rich texture features. Furthermore, the appearance of specularity heavily depends on the camera viewpoint and environmental light conditions making traditional methods, like template matching, fail. In the last 30 years, pose estimation of the specular object has been a consistent challenge, and most related works require massive knowledge modeling effort for light setups, environment, or the object surface. On the other hand, recent works exhibit the feasibility of 6D pose estimation on a monocular camera with convolutional neural networks(CNNs) however they mostly use opaque objects for evaluation. This paper provides a data-driven solution to estimate the 6D pose of specular objects for grasping them, proposes a cost function for handling symmetry, and demonstrates experimental results showing the system's feasibility.
Modeling Preemptive Behaviors for Uncommon Hazardous Situations From Demonstrations
Jun 01, 2018



This paper presents a learning from demonstration approach to programming safe, autonomous behaviors for uncommon driving scenarios. Simulation is used to re-create a targeted driving situation, one containing a road-side hazard creating a significant occlusion in an urban neighborhood, and collect optimal driving behaviors from 24 users. Paper employs a key-frame based approach combined with an algorithm to linearly combine models in order to extend the behavior to novel variations of the target situation. This approach is theoretically agnostic to the kind of LfD framework used for modeling data and our results suggest it generalizes well to variations containing an additional number of hazards occurring in sequence. The linear combination algorithm is informed by analysis of driving data, which also suggests that decision-making algorithms need to consider a trade-off between road-rules and immediate rewards to tackle some complex cases.