 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridgeSim: Unveiling the OL-CL Gap in End-to-End Autonomous Driving
Apr 12, 2026Open-loop (OL) to closed-loop (CL) gap (OL-CL gap) exists when OL-pretrained policies scoring high in OL evaluations fail to transfer effectively in closed-loop (CL) deployment. In this paper, we unveil the root causes of this systemic failure and propose a practical remedy. Specifically, we demonstrate that OL policies suffer from Observational Domain Shift and Objective Mismatch. We show that while the former is largely recoverable with adaptation techniques, the latter creates a structural inability to model complex reactive behaviors, which forms the primary OL-CL gap. We find that a wide range of OL policies learn a biased Q-value estimator that neglects both the reactive nature of CL simulations and the temporal awareness needed to reduce compounding errors. To this end, we propose a Test-Time Adaptation (TTA) framework that calibrates observational shift, reduces state-action biases, and enforces temporal consistency. Extensive experiments show that TTA effectively mitigates planning biases and yields superior scaling dynamics than its baseline counterparts. Furthermore, our analysis highlights the existence of blind spots in standard OL evaluation protocols that fail to capture the realities of closed-loop deployment.
cpRRTC: GPU-Parallel RRT-Connect for Constrained Motion Planning
May 11, 2025Motion planning is a fundamental problem in robotics that involves generating feasible trajectories for a robot to follow. Recent advances in parallel computing, particularly through CPU and GPU architectures, have significantly reduced planning times to the order of milliseconds. However, constrained motion planning especially using sampling based methods on GPUs remains underexplored. Prior work such as pRRTC leverages a tracking compiler with a CUDA backend to accelerate forward kinematics and collision checking. While effective in simple settings, their approach struggles with increased complexity in robot models or environments. In this paper, we propose a novel GPU based framework utilizing NVRTC for runtime compilation, enabling efficient handling of high complexity scenarios and supporting constrained motion planning. Experimental results demonstrate that our method achieves superior performance compared to existing approaches.
Controllable Motion Generation via Diffusion Modal Coupling
Mar 04, 2025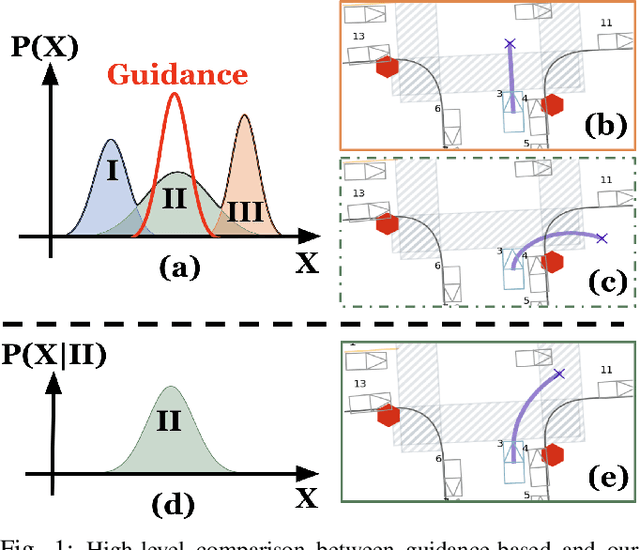
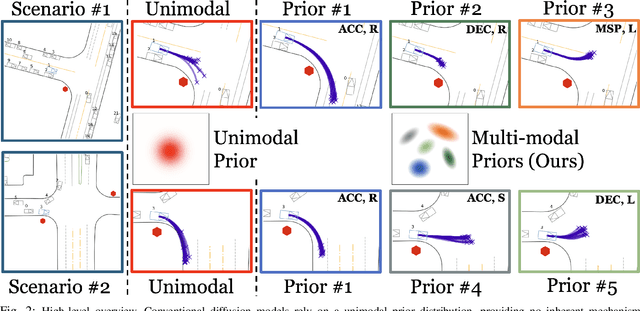
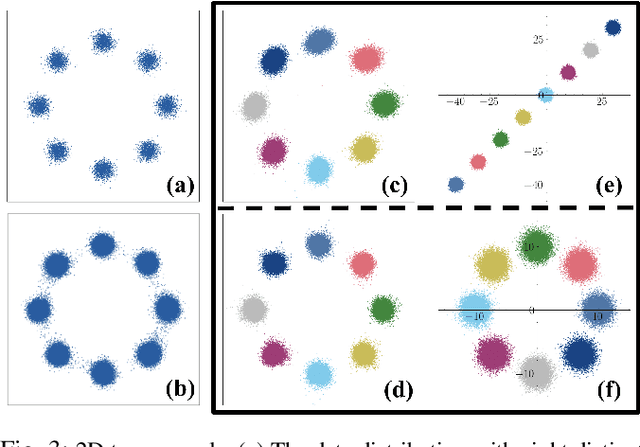
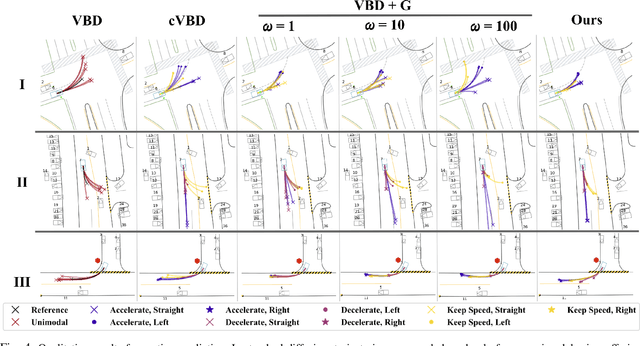
Diffusion models have recently gained significant attention in robotics due to their ability to generate multi-modal distributions of system states and behaviors. However, a key challenge remains: ensuring precise control over the generated outcomes without compromising realism. This is crucial for applications such as motion planning or trajectory forecasting, where adherence to physical constraints and task-specific objectives is essential. We propose a novel framework that enhances controllability in diffusion models by leveraging multi-modal prior distributions and enforcing strong modal coupling. This allows us to initiate the denoising process directly from distinct prior modes that correspond to different possible system behaviors, ensuring sampling to align with the training distribution. We evaluate our approach on motion prediction using the Waymo dataset and multi-task control in Maze2D environments. Experimental results show that our framework outperforms both guidance-based techniques and conditioned models with unimodal priors, achieving superior fidelity, diversity, and controllability, even in the absence of explicit conditioning. Overall, our approach provides a more reliable and scalable solution for controllable motion generation in robotics.
OSM vs HD Maps: Map Representations for Trajectory Prediction
Nov 04, 2023While High Definition (HD) Maps have long been favored for their precise depictions of static road elements, their accessibility constraints and susceptibility to rapid environmental changes impede the widespread deployment of autonomous driving, especially in the motion forecasting task. In this context, we propose to leverage OpenStreetMap (OSM) as a promising alternative to HD Maps for long-term motion forecasting. The contributions of this work are threefold: firstly, we extend the application of OSM to long-horizon forecasting, doubling the forecasting horizon compared to previous studies. Secondly, through an expanded receptive field and the integration of intersection priors, our OSM-based approach exhibits competitive performance, narrowing the gap with HD Map-based models. Lastly, we conduct an exhaustive context-aware analysis, providing deeper insights in motion forecasting across diverse scenarios as well as conducting class-aware comparisons. This research not only advances long-term motion forecasting with coarse map representations but additionally offers a potential scalable solution within the domain of autonomous driving.
A Real2Sim2Real Method for Robust Object Grasping with Neural Surface Reconstruction
Oct 06, 2022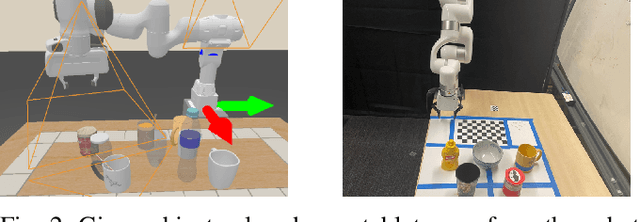
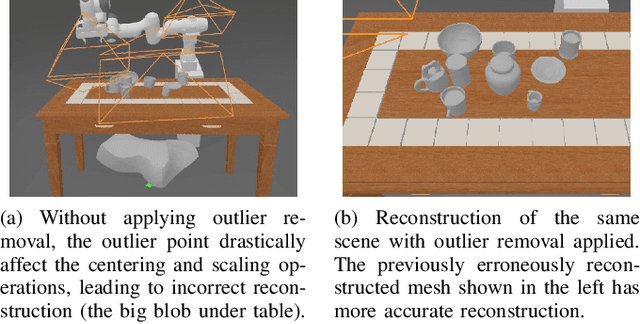


Recent 3D-based manipulation methods either directly predict the grasp pose using 3D neural networks, or solve the grasp pose using similar objects retrieved from shape databases. However, the former faces generalizability challenges when testing with new robot arms or unseen objects; and the latter assumes that similar objects exist in the databases. We hypothesize that recent 3D modeling methods provides a path towards building digital replica of the evaluation scene that affords physical simulation and supports robust manipulation algorithm learning. We propose to reconstruct high-quality meshes from real-world point clouds using state-of-the-art neural surface reconstruction method (the Real2Sim step). Because most simulators take meshes for fast simulation, the reconstructed meshes enable grasp pose labels generation without human efforts. The generated labels can train grasp network that performs robustly in the real evaluation scene (the Sim2Real step). In synthetic and real experiments, we show that the Real2Sim2Real pipeline performs better than baseline grasp networks trained with a large dataset and a grasp sampling method with retrieval-based reconstruction. The benefit of the Real2Sim2Real pipeline comes from 1) decoupling scene modeling and grasp sampling into sub-problems, and 2) both sub-problems can be solved with sufficiently high quality using recent 3D learning algorithms and mesh-based physical simulation techniques.
Single RGB-D Camera Teleoperation for General Robotic Manipulation
Jun 30, 2021

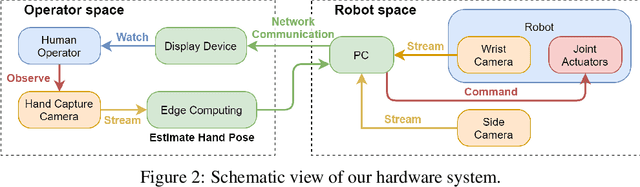

We propose a teleoperation system that uses a single RGB-D camera as the human motion capture device. Our system can perform general manipulation tasks such as cloth folding, hammering and 3mm clearance peg in hole. We propose the use of non-Cartesian oblique coordinate frame, dynamic motion scaling and reposition of operator frames to increase the flexibility of our teleoperation system. We hypothesize that lowering the barrier of entry to teleoperation will allow for wider deployment of supervised autonomy system, which will in turn generates realistic datasets that unlock the potential of machine learning for robotic manipulation.
Robotics Enabling the Workforce
Dec 16, 2020Robotics has the potential to magnify the skilled workforce of the nation by complementing our workforce with automation: teams of people and robots will be able to do more than either could alone. The economic engine of the U.S. runs on the productivity of our people. The rise of automation offers new opportunities to enhance the work of our citizens and drive the innovation and prosperity of our industries. Most critically, we need research to understand how future robot technologies can best complement our workforce to get the best of both human and automated labor in a collaborative team. Investments made in robotics research and workforce development will lead to increased GDP, an increased export-import ratio, a growing middle class of skilled workers, and a U.S.-based supply chain that can withstand global pandemics and other disruptions. In order to make the United States a leader in robotics, we need to invest in basic research, technology development, K-16 education, and lifelong learning.
Pose Estimation of Specular and Symmetrical Objects
Oct 31, 2020
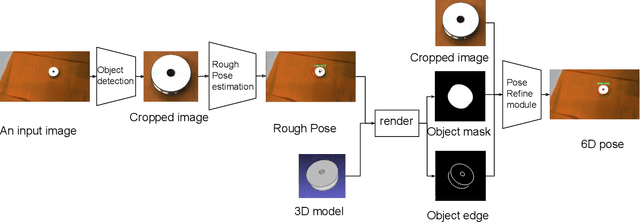
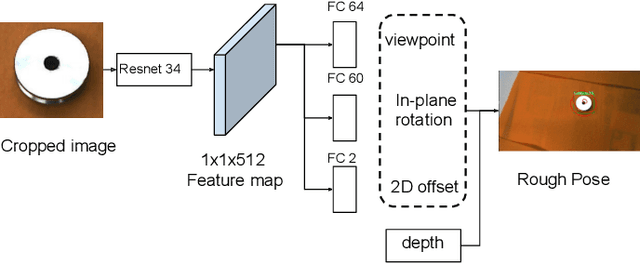
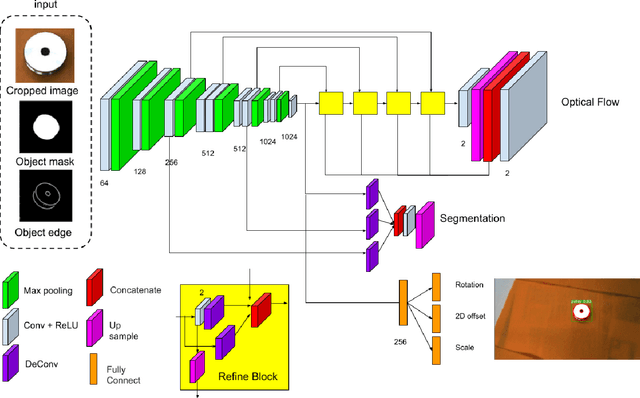
In the robotic industry, specular and textureless metallic components are ubiquitous. The 6D pose estimation of such objects with only a monocular RGB camera is difficult because of the absence of rich texture features. Furthermore, the appearance of specularity heavily depends on the camera viewpoint and environmental light conditions making traditional methods, like template matching, fail. In the last 30 years, pose estimation of the specular object has been a consistent challenge, and most related works require massive knowledge modeling effort for light setups, environment, or the object surface. On the other hand, recent works exhibit the feasibility of 6D pose estimation on a monocular camera with convolutional neural networks(CNNs) however they mostly use opaque objects for evaluation. This paper provides a data-driven solution to estimate the 6D pose of specular objects for grasping them, proposes a cost function for handling symmetry, and demonstrates experimental results showing the system's feasibility.
Auto-calibration Method Using Stop Signs for Urban Autonomous Driving Applications
Oct 14, 2020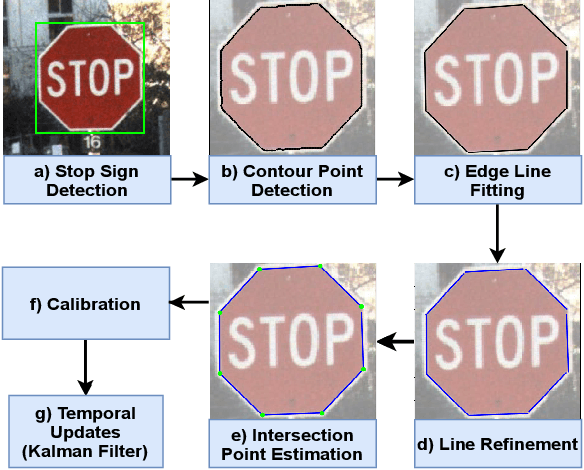
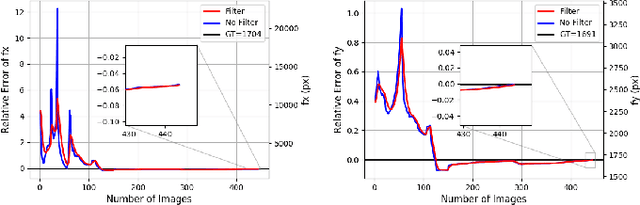
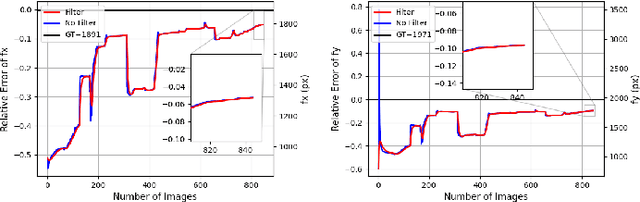
For use of cameras on an intelligent vehicle, driving over a major bump could challenge the calibration. It is then of interest to do dynamic calibration. What structures can be used for calibration? How about using traffic signs that you recognize? In this paper an approach is presented for dynamic camera calibration based on recognition of stop signs. The detection is performed based on convolutional neural networks (CNNs). A recognized sign is modeled as a polygon and matched to a model. Parameters are tracked over time. Experimental results show clear convergence and improved performance for the calibration.
Probabilistic Semantic Mapping for Urban Autonomous Driving Applications
Jun 08, 2020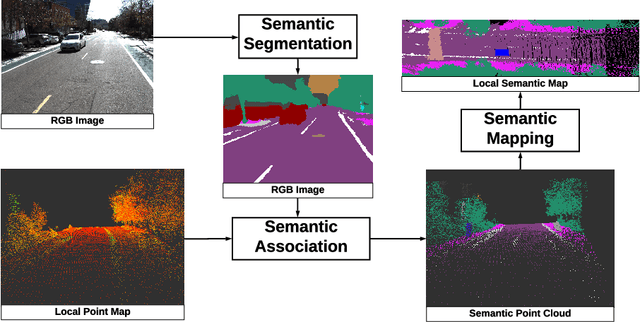
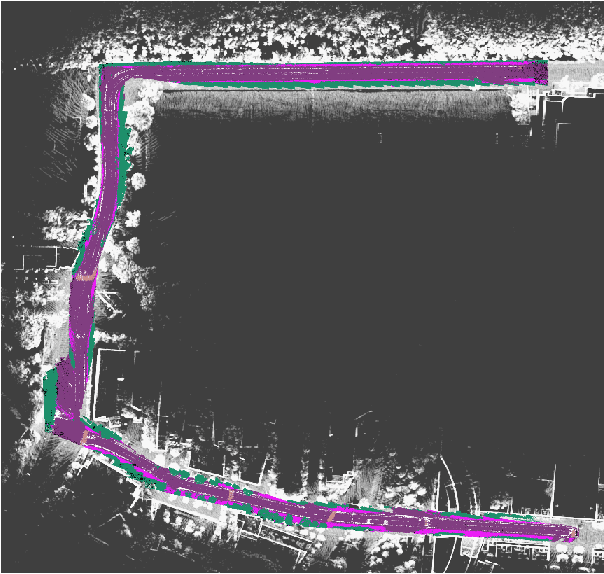

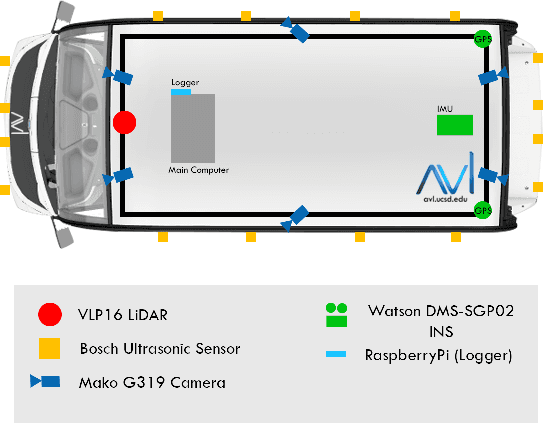
Recent advancement in statistical learning and computational ability has enabled autonomous vehicle technology to develop at a much faster rate and become widely adopted. While many of the architectures previously introduced are capable of operating under highly dynamic environments, many of these are constrained to smaller-scale deployments and require constant maintenance due to the associated scalability cost with high-definition (HD) maps. HD maps provide critical information for self-driving cars to drive safely. However, traditional approaches for creating HD maps involves tedious manual labeling. As an attempt to tackle this problem, we fuse 2D image semantic segmentation with pre-built point cloud maps collected from a relatively inexpensive 16 channel LiDAR sensor to construct a local probabilistic semantic map in bird's eye view that encodes static landmarks such as roads, sidewalks, crosswalks, and lanes in the driving environment. Experiments from data collected in an urban environment show that this model can be extended for automatically incorporating road features into HD maps with potential future work directions.