 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Compositional Generation with Diffusion Models Using Lift Scores
May 19, 2025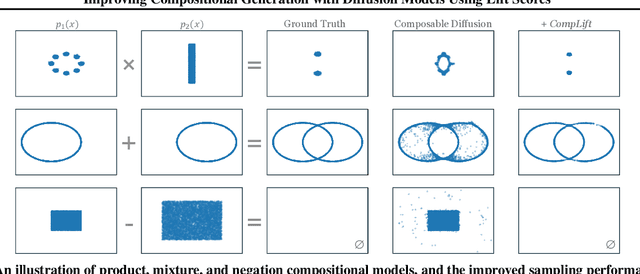

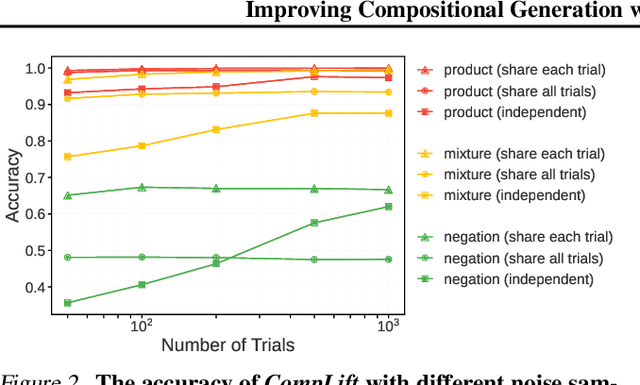
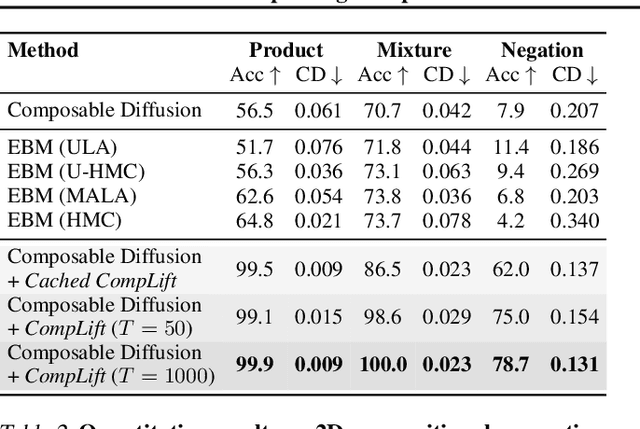
We introduce a novel resampling criterion using lift scores, for improving compositional generation in diffusion models. By leveraging the lift scores, we evaluate whether generated samples align with each single condition and then compose the results to determine whether the composed prompt is satisfied. Our key insight is that lift scores can be efficiently approximated using only the original diffusion model, requiring no additional training or external modules. We develop an optimized variant that achieves relatively lower computational overhead during inference while maintaining effectiveness. Through extensive experiments, we demonstrate that lift scores significantly improved the condition alignment for compositional generation across 2D synthetic data, CLEVR position tasks, and text-to-image synthesis. Our code is available at http://github.com/rainorangelemon/complift.
Controllable Motion Generation via Diffusion Modal Coupling
Mar 04, 2025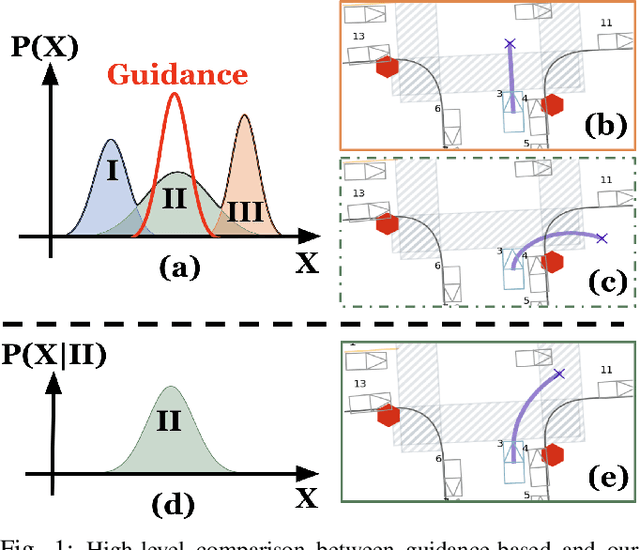
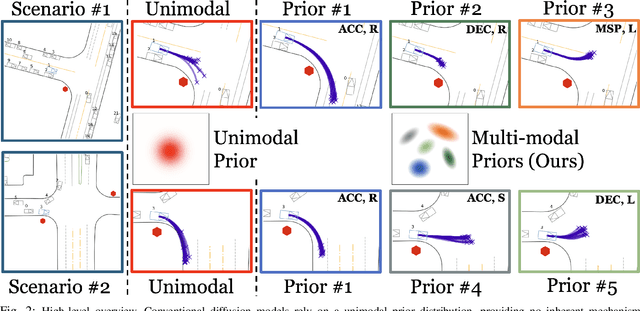
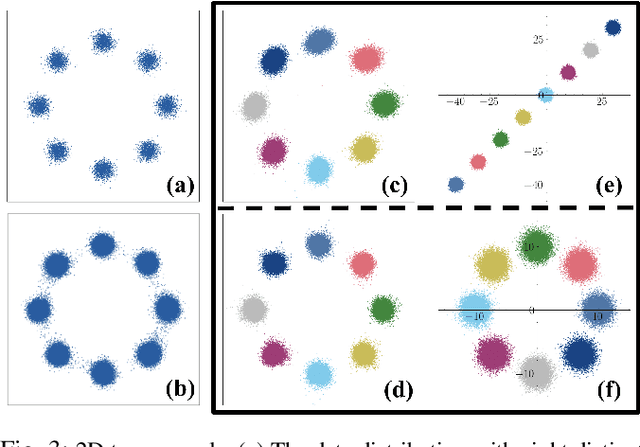
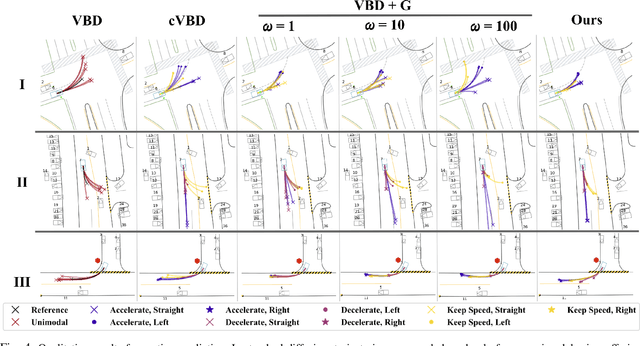
Diffusion models have recently gained significant attention in robotics due to their ability to generate multi-modal distributions of system states and behaviors. However, a key challenge remains: ensuring precise control over the generated outcomes without compromising realism. This is crucial for applications such as motion planning or trajectory forecasting, where adherence to physical constraints and task-specific objectives is essential. We propose a novel framework that enhances controllability in diffusion models by leveraging multi-modal prior distributions and enforcing strong modal coupling. This allows us to initiate the denoising process directly from distinct prior modes that correspond to different possible system behaviors, ensuring sampling to align with the training distribution. We evaluate our approach on motion prediction using the Waymo dataset and multi-task control in Maze2D environments. Experimental results show that our framework outperforms both guidance-based techniques and conditioned models with unimodal priors, achieving superior fidelity, diversity, and controllability, even in the absence of explicit conditioning. Overall, our approach provides a more reliable and scalable solution for controllable motion generation in robotics.
Efficient Motion Planning for Manipulators with Control Barrier Function-Induced Neural Controller
Apr 01, 2024

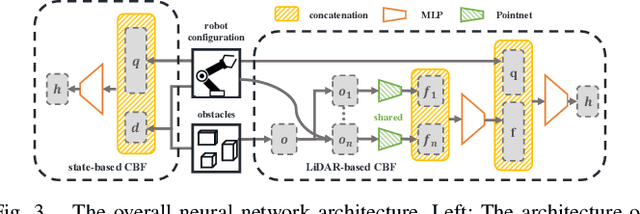
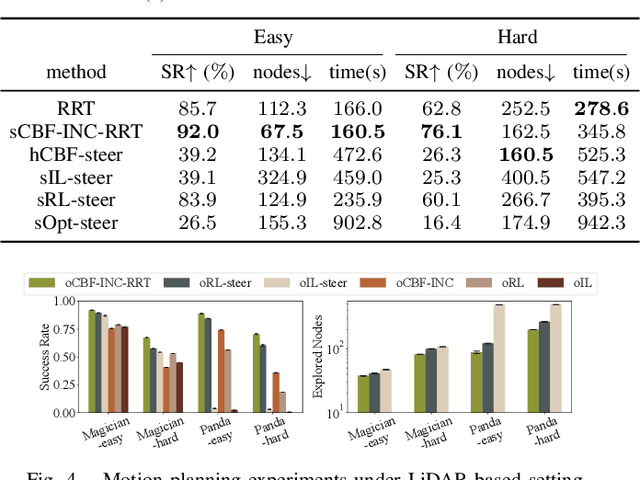
Sampling-based motion planning methods for manipulators in crowded environments often suffer from expensive collision checking and high sampling complexity, which make them difficult to use in real time. To address this issue, we propose a new generalizable control barrier function (CBF)-based steering controller to reduce the number of samples needed in a sampling-based motion planner RRT. Our method combines the strength of CBF for real-time collision-avoidance control and RRT for long-horizon motion planning, by using CBF-induced neural controller (CBF-INC) to generate control signals that steer the system towards sampled configurations by RRT. CBF-INC is learned as Neural Networks and has two variants handling different inputs, respectively: state (signed distance) input and point-cloud input from LiDAR. In the latter case, we also study two different settings: fully and partially observed environmental information. Compared to manually crafted CBF which suffers from over-approximating robot geometry, CBF-INC can balance safety and goal-reaching better without being over-conservative. Given state-based input, our neural CBF-induced neural controller-enhanced RRT (CBF-INC-RRT) can increase the success rate by 14% while reducing the number of nodes explored by 30%, compared with vanilla RRT on hard test cases. Given LiDAR input where vanilla RRT is not directly applicable, we demonstrate that our CBF-INC-RRT can improve the success rate by 10%, compared with planning with other steering controllers. Our project page with supplementary material is at https://mit-realm.github.io/CBF-INC-RRT-website/.
Iterative Reachability Estimation for Safe Reinforcement Learning
Sep 24, 2023
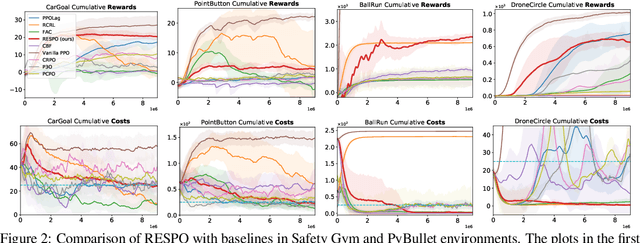

Ensuring safety is important for the practical deployment of reinforcement learning (RL). Various challenges must be addressed, such as handling stochasticity in the environments, providing rigorous guarantees of persistent state-wise safety satisfaction, and avoiding overly conservative behaviors that sacrifice performance. We propose a new framework, Reachability Estimation for Safe Policy Optimization (RESPO), for safety-constrained RL in general stochastic settings. In the feasible set where there exist violation-free policies, we optimize for rewards while maintaining persistent safety. Outside this feasible set, our optimization produces the safest behavior by guaranteeing entrance into the feasible set whenever possible with the least cumulative discounted violations. We introduce a class of algorithms using our novel reachability estimation function to optimize in our proposed framework and in similar frameworks such as those concurrently handling multiple hard and soft constraints. We theoretically establish that our algorithms almost surely converge to locally optimal policies of our safe optimization framework. We evaluate the proposed methods on a diverse suite of safe RL environments from Safety Gym, PyBullet, and MuJoCo, and show the benefits in improving both reward performance and safety compared with state-of-the-art baselines.
Sequential Neural Barriers for Scalable Dynamic Obstacle Avoidance
Jul 06, 2023



There are two major challenges for scaling up robot navigation around dynamic obstacles: the complex interaction dynamics of the obstacles can be hard to model analytically, and the complexity of planning and control grows exponentially in the number of obstacles. Data-driven and learning-based methods are thus particularly valuable in this context. However, data-driven methods are sensitive to distribution drift, making it hard to train and generalize learned models across different obstacle densities. We propose a novel method for compositional learning of Sequential Neural Control Barrier models (SNCBFs) to achieve scalability. Our approach exploits an important observation: the spatial interaction patterns of multiple dynamic obstacles can be decomposed and predicted through temporal sequences of states for each obstacle. Through decomposition, we can generalize control policies trained only with a small number of obstacles, to environments where the obstacle density can be 100x higher. We demonstrate the benefits of the proposed methods in improving dynamic collision avoidance in comparison with existing methods including potential fields, end-to-end reinforcement learning, and model-predictive control. We also perform hardware experiments and show the practical effectiveness of the approach in the supplementary video.
Accelerating Multi-Agent Planning Using Graph Transformers with Bounded Suboptimality
Jan 20, 2023
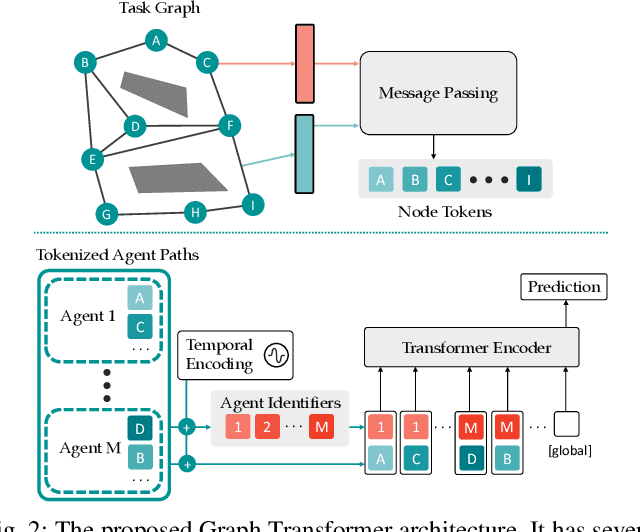
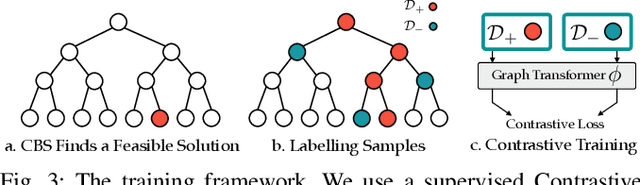
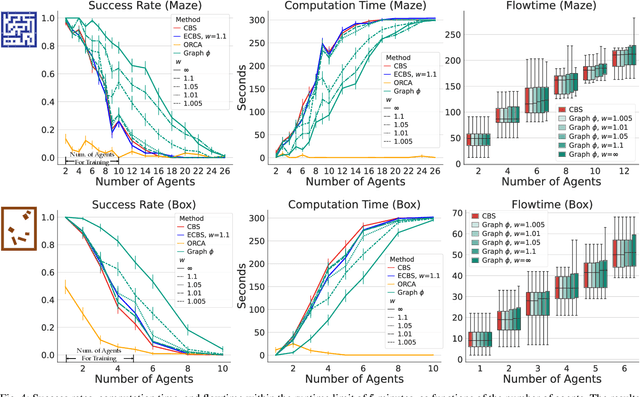
Conflict-Based Search is one of the most popular methods for multi-agent path finding. Though it is complete and optimal, it does not scale well. Recent works have been proposed to accelerate it by introducing various heuristics. However, whether these heuristics can apply to non-grid-based problem settings while maintaining their effectiveness remains an open question. In this work, we find that the answer is prone to be no. To this end, we propose a learning-based component, i.e., the Graph Transformer, as a heuristic function to accelerate the planning. The proposed method is provably complete and bounded-suboptimal with any desired factor. We conduct extensive experiments on two environments with dense graphs. Results show that the proposed Graph Transformer can be trained in problem instances with relatively few agents and generalizes well to a larger number of agents, while achieving better performance than state-of-the-art methods.
Reducing Collision Checking for Sampling-Based Motion Planning Using Graph Neural Networks
Oct 17, 2022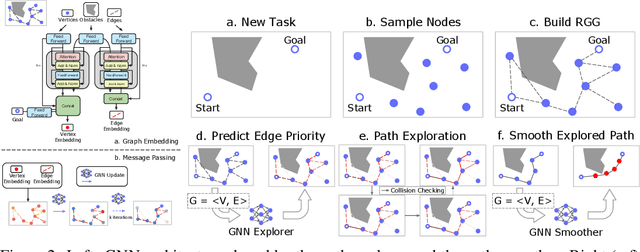
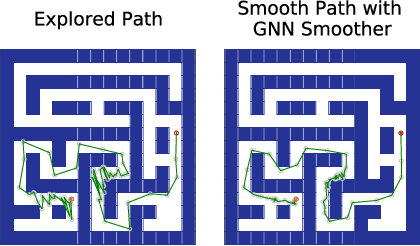
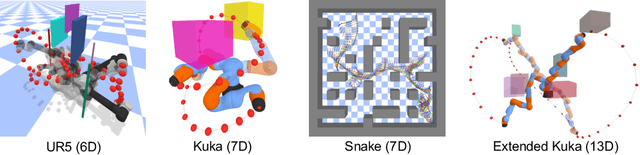
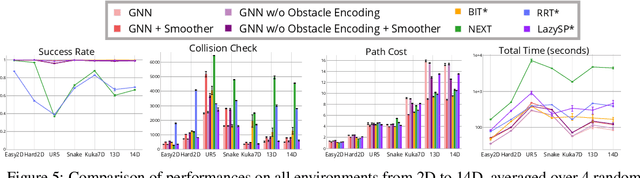
Sampling-based motion planning is a popular approach in robotics for finding paths in continuous configuration spaces. Checking collision with obstacles is the major computational bottleneck in this process. We propose new learning-based methods for reducing collision checking to accelerate motion planning by training graph neural networks (GNNs) that perform path exploration and path smoothing. Given random geometric graphs (RGGs) generated from batch sampling, the path exploration component iteratively predicts collision-free edges to prioritize their exploration. The path smoothing component then optimizes paths obtained from the exploration stage. The methods benefit from the ability of GNNs of capturing geometric patterns from RGGs through batch sampling and generalize better to unseen environments. Experimental results show that the learned components can significantly reduce collision checking and improve overall planning efficiency in challenging high-dimensional motion planning tasks.
Learning Control Admissibility Models with Graph Neural Networks for Multi-Agent Navigation
Oct 17, 2022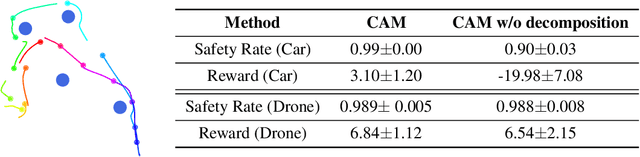
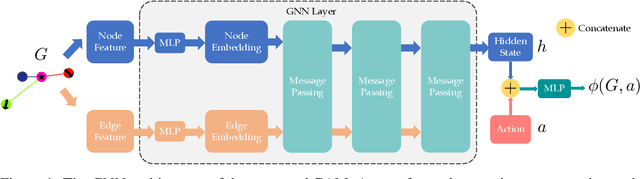
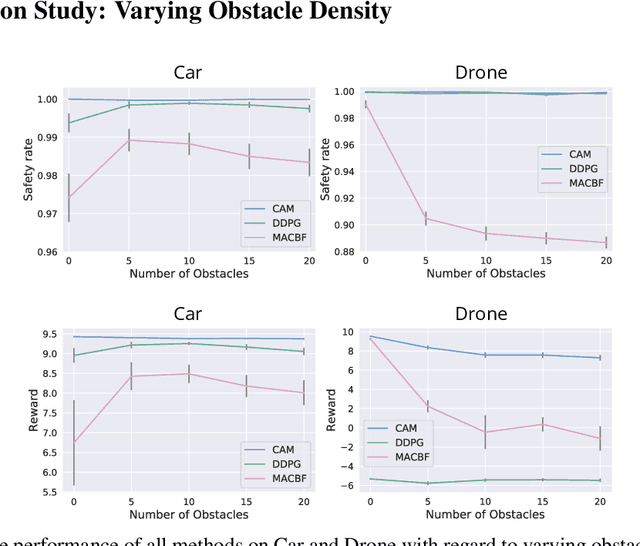
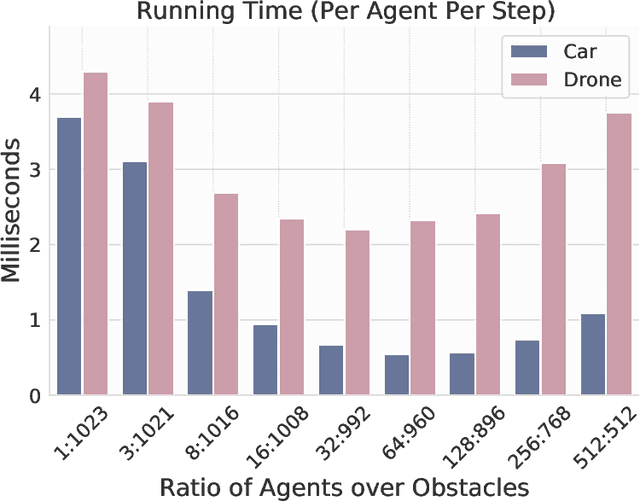
Deep reinforcement learning in continuous domains focuses on learning control policies that map states to distributions over actions that ideally concentrate on the optimal choices in each step. In multi-agent navigation problems, the optimal actions depend heavily on the agents' density. Their interaction patterns grow exponentially with respect to such density, making it hard for learning-based methods to generalize. We propose to switch the learning objectives from predicting the optimal actions to predicting sets of admissible actions, which we call control admissibility models (CAMs), such that they can be easily composed and used for online inference for an arbitrary number of agents. We design CAMs using graph neural networks and develop training methods that optimize the CAMs in the standard model-free setting, with the additional benefit of eliminating the need for reward engineering typically required to balance collision avoidance and goal-reaching requirements. We evaluate the proposed approach in multi-agent navigation environments. We show that the CAM models can be trained in environments with only a few agents and be easily composed for deployment in dense environments with hundreds of agents, achieving better performance than state-of-the-art methods.
Learning-based Motion Planning in Dynamic Environments Using GNNs and Temporal Encoding
Oct 16, 2022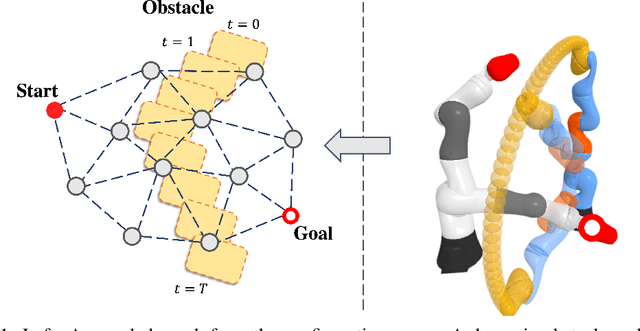
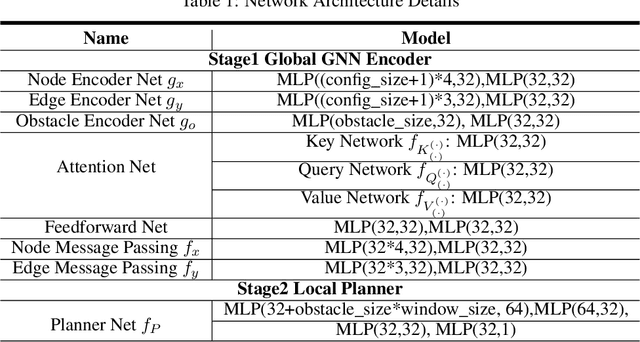
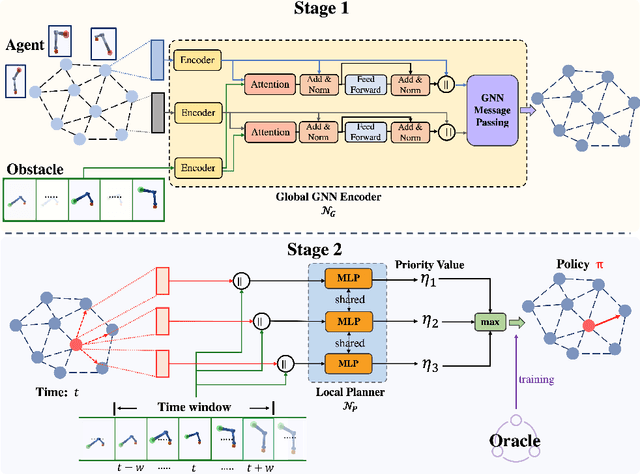
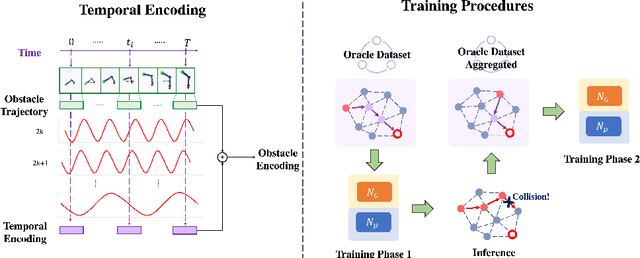
Learning-based methods have shown promising performance for accelerating motion planning, but mostly in the setting of static environments. For the more challenging problem of planning in dynamic environments, such as multi-arm assembly tasks and human-robot interaction, motion planners need to consider the trajectories of the dynamic obstacles and reason about temporal-spatial interactions in very large state spaces. We propose a GNN-based approach that uses temporal encoding and imitation learning with data aggregation for learning both the embeddings and the edge prioritization policies. Experiments show that the proposed methods can significantly accelerate online planning over state-of-the-art complete dynamic planning algorithms. The learned models can often reduce costly collision checking operations by more than 1000x, and thus accelerating planning by up to 95%, while achieving high success rates on hard instances as well.